
#定义三个实例
conn_1 = {'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'password': 'root',"database":"db01","priority":100}
conn_2 = {'host': '127.0.0.1', 'port': 3307, 'user': 'root', 'password': 'root',"database":"db01","priority":200}
conn_3 = {'host': '127.0.0.1', 'port': 3308, 'user': 'root', 'password': 'root',"database":"db01","priority":300}
conn_list = []
conn_list.append(conn_1)
conn_list.append(conn_2)
conn_list.append(conn_3)
print("####execute update on master####")
myrouter = MySQLRouter(conn_list=conn_list, operation="write")
conn = myrouter.get_connection()
cursor = conn.cursor()
cursor.execute("update t01 set update_date = now() where id = 1")
conn.commit()
cursor.close()
conn.close()
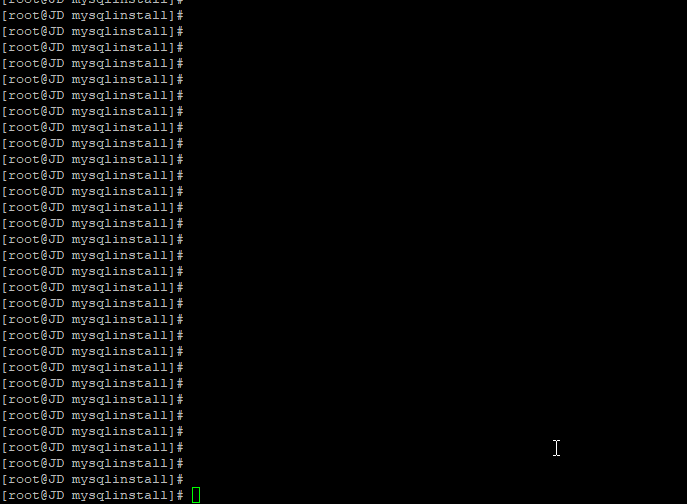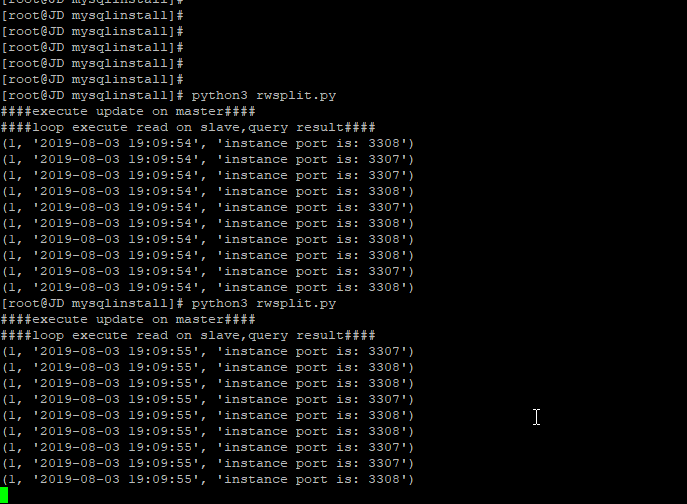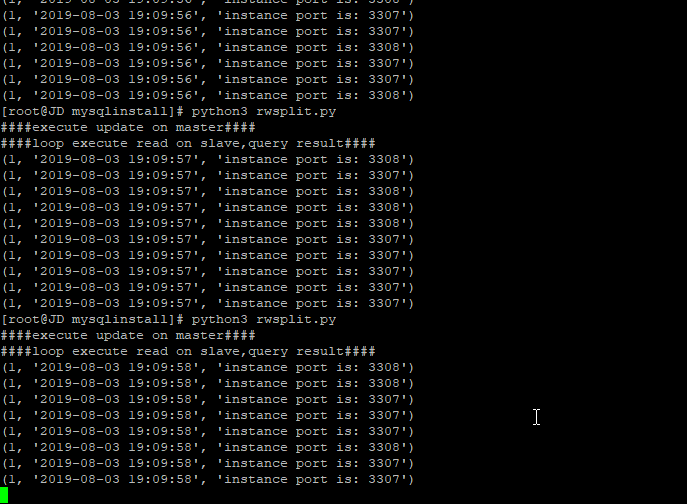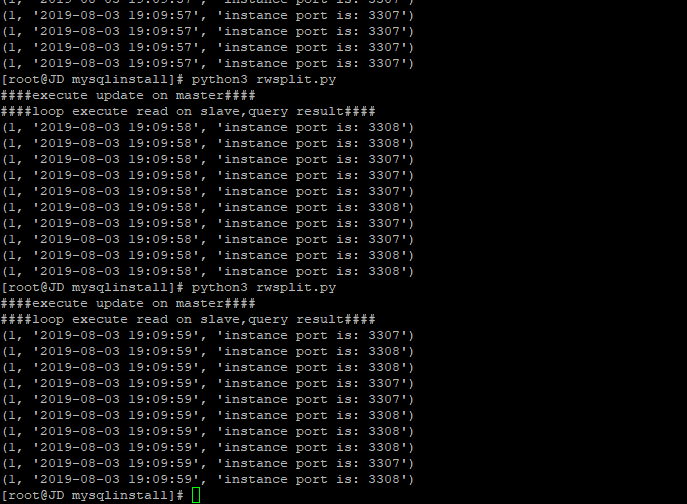
print("####loop execute read on slave,query result####")
#循环读,判断读指向哪个节点。
for loop in range(10):
myrouter = MySQLRouter(conn_list = conn_list,operation = "read")
conn = myrouter.get_connection()
cursor = conn.cursor()
cursor.execute("SELECT id,cast(update_date as char), CONCAT('instance port is: ', CAST( @@PORT AS CHAR)) AS port FROM t01;")
result = cursor.fetchone()
print(result)
cursor.close()
conn.close()
这里用过服务器的一个优先级,将写请求指向最高优先级的master服务器,读请求随机指向非最高优先级的slave,
对于更新请求,都在master上执行,slave复制了master的数据,每次读到的数据都不一样,并且每次都请求的执行,基本上都随机地指向了两台slave服务器
通过查询返回一个端口号,来判断读请求是否平均分散到了不通的slave端。
与“MySQL Router拿来当玩具玩玩就好”相比,这里的实现一样low,因为对数据的请求需要请求明确指定是读还是写。
对于自动读写分离,无非是一个SQL语句执行的是的读或写判断问题,并非难事,这个需要解析请求的SQL是读的还是写的问题。
某些数据库中间件可以实现自动的读写分离,但是要明白,对于那些支持自动读写分离的中间件,往往是要受到一定的约束的,比如不能用存储过程什么的,为什么呢?
还是上面提到的SQL解析的问题,因为一旦使用了存储过程,无法解析出来这个SQL到底是执行的是读还是写,最起码不是太直接。
对于SQL读写的判断,也就是维护一个读或者写的枚举正则表达式,非读即写,只是要格外关注这个读写的判断的效率问题。
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx