
对一个变量取地址,可能会被分配到堆上。但是编译器进行逃逸分析后,如果考察到在函数返回后,此变量不会被引用,那么还是会被分配到栈上。套个取址符,就想骗补助?Too young!
简单来说,编译器会根据变量是否被外部引用来决定是否逃逸:
如果函数外部没有引用,则优先放到栈中;
如果函数外部存在引用,则必定放到堆中;
针对第一条,可能放到堆上的情形:定义了一个很大的数组,需要申请的内存过大,超过了栈的存储能力。
逃逸分析实例Go提供了相关的命令,可以查看变量是否发生逃逸。
还是用上面我们提到的例子:
package main import "fmt" func foo() *int { t := 3 return &t; } func main() { x := foo() fmt.Println(*x) }foo函数返回一个局部变量的指针,main函数里变量x接收它。执行如下命令:
linuxidc@linuxidc:~/www.linuxidc.com/Linux公社 -$ go build -gcflags '-m -l' linuxidc.com.go

加-l是为了不让foo函数被内联。得到如下输出:
# command-line-arguments
./linuxidc.com.go:7:12: &t escapes to heap
./linuxidc.com.go:6:5: moved to heap: t
./linuxidc.com.go:12:17: *x escapes to heap
./linuxidc.com.go:12:16: main ... argument does not escape
foo函数里的变量t逃逸了,和我们预想的一致。让我们不解的是为什么main函数里的x也逃逸了?这是因为有些函数参数为interface类型,比如fmt.Println(a ...interface{}),编译期间很难确定其参数的具体类型,也会发生逃逸。
使用反汇编命令也可以看出变量是否发生逃逸。
go tool compile -S linuxidc.com.go截取部分结果,图中标记出来的说明t是在堆上分配内存,发生了逃逸。
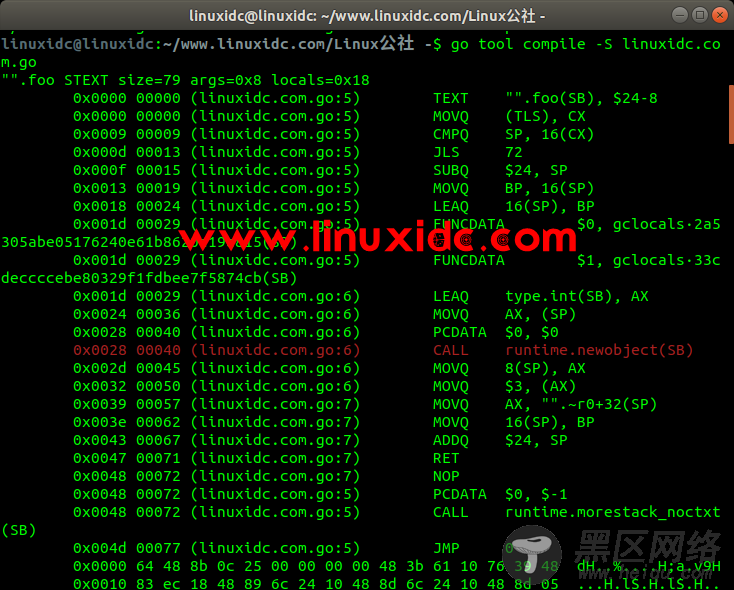
堆上动态分配内存比栈上静态分配内存,开销大很多。
变量分配在栈上需要能在编译期确定它的作用域,否则会分配到堆上。
Go编译器会在编译期对考察变量的作用域,并作一系列检查,如果它的作用域在运行期间对编译器一直是可知的,那么就会分配到栈上。
简单来说,编译器会根据变量是否被外部引用来决定是否逃逸。对于Go程序员来说,编译器的这些逃逸分析规则不需要掌握,我们只需通过go build -gcflags '-m'命令来观察变量逃逸情况就行了。
不要盲目使用变量的指针作为函数参数,虽然它会减少复制操作。但其实当参数为变量自身的时候,复制是在栈上完成的操作,开销远比变量逃逸后动态地在堆上分配内存少的多。
最后,尽量写出少一些逃逸的代码,提升程序的运行效率。
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx