
子查询过滤后读入内存,然后外层表与先读入的内存表(子查询)做哈希连接进行过滤。集算器提供了 switch@i()、join@i() 两个函数用来做哈希连接过滤,switch 是外键式连接,用来把外键字段变成指引字段,这样就可以通过外键字段直接引用指向表的字段,join 函数不会改变外键字段的值,可用于只过滤。
集算器实现:

子查询关联字段不是主键
SQL 示例(5):
select
O_ORDERPRIORITY, count(*) as O_COUNT
from
ORDERS
where
O_ORDERDATE >= date '1995-10-01'
and O_ORDERDATE < date '1995-10-01' + interval '3' month
and exists (
select
*
from
LINEITEM
where
L_ORDERKEY = O_ORDERKEY
and L_COMMITDATE < L_RECEIPTDATE
)
group by
O_ORDERPRIORITY
优化思路:
子查询过滤后按关联字段去重读入内存,然后就变成类似于主键的情况了,可以继续用上面说的 switch@i()、join@i() 两个函数用来做哈希连接过滤。
集算器实现:
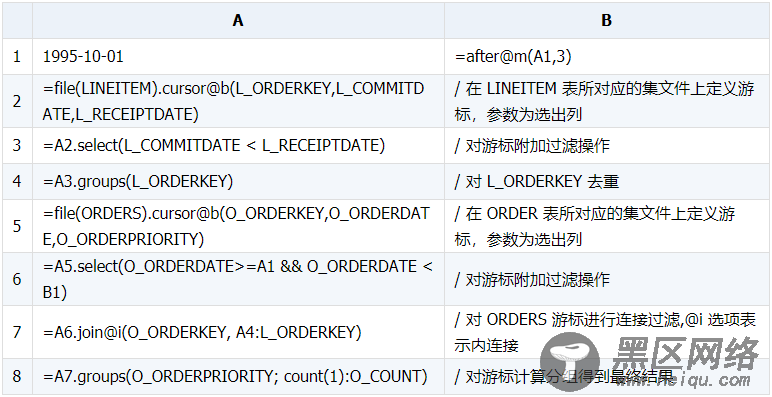
子查询结果集存放不下
SQL 示例(5):
select
O_ORDERPRIORITY, count(*) as O_COUNT
from
ORDERS
where
O_ORDERDATE >= date '1995-10-01'
and O_ORDERDATE < date '1995-10-01' + interval '3' month
and exists (
select
*
from
LINEITEM
where
L_ORDERKEY = O_ORDERKEY
and L_COMMITDATE < L_RECEIPTDATE
)
group by
O_ORDERPRIORITY
优化思路:
等值 EXISTS 相当于对内部表关联字段去重然后跟外层表做内连接,而做连接效率较好的就是哈希连接和有序归并连接,所以这个问题就变成了怎么把 EXISTS 翻译成高效的连接,下面我们来分析在不同的数据分布下如何把 EXISTS 转成连接。
1、外层表数据量比较小可以装入内存:
先读入外层表,如果外层表关联字段不是逻辑主键则去重,再拿上一步算出来的关联字段的值对子查询做哈希连接过滤,最后拿算出来的子查询关联字段的值对外层表做哈希连接过滤。
2、外层表和内层表按关联字段有序:
此时可以利用函数 joinx() 来做有序游标的归并连接,如果内层表关联字段不是逻辑主键则需要先去重。此例中的 ORDERS 表和 LINEITEM 表是按照 ORDERKEY 同序存放,可以利用此方法来做优化。
3、内层表是大维表并且按主键有序存放:
集算器提供了针对有序大维表文件做连接的函数 A.joinx,其它方法跟内存能放下时的处理类似在此不再描述。
集算器实现(1):

集算器实现(2):

同表关联
SQL 示例(6):
select
L_SUPPKEY, count(*) as numwait
from
LINEITEM L1,
where
L1.L_RECEIPTDATE > L1.L_COMMITDATE
and exists (
select
*
from
LINEITEM L2
where
L2.L_ORDERKEY = L1.L_ORDERKEY
and L2.L_SUPPKEY <> L1.L_SUPPKEY
)
and not exists (
select
*
from
LINEITEM L3
where
L3.L_ORDERKEY = L1.L_ORDERKEY
and L3.L_SUPPKEY <> L1.L_SUPPKEY
and L3.L_RECEIPTDATE > L3.L_COMMITDATE
)
group by
L_SUPPKEY
优化思路: