
直方图是表上某个字段在按照一定百分比和规律采样后的数据分布的一种描述,最重要的作用之一就是根据查询条件,预估符合条件的数据量,为sql执行计划的生成提供重要的依据
在MySQL 8.0之前的版本中,MySQL仅有一个简单的统计信息却没有直方图,没有直方图的统计信息可以说是没有任何意义的。
MySQL 8.0新特性之一就是开始支持统计信息的直方图,这个概念很早就提出来了,抽空具体尝试了一下使用方法。
照旧,直接上例子,造数据,创建一个测试环境
create table test
(
id int auto_increment primary key,
name varchar(100),
create_date datetime ,
index (create_date desc)
);
USE `db01`$$
DROP PROCEDURE IF EXISTS `insert_test_data`$$
CREATE DEFINER=`root`@`%` PROCEDURE `insert_test_data`()
BEGIN
DECLARE v_loop INT;
SET v_loop = 100000;
WHILE v_loop>0 DO
INSERT INTO test(NAME,create_date)VALUES (UUID(),DATE_ADD(NOW(),INTERVAL -RAND()*100000 MINUTE) );
SET v_loop = v_loop - 1;
END WHILE;
END$$
DELIMITER ;
MySQL中统计信息的创建,不同于MSSQL,MySQL统计信息不依赖于索引,需要单独创建,语法如下
--创建字段上的统计直方图信息
ANALYZE TABLE test UPDATE HISTOGRAM ON create_date,name WITH 16 BUCKETS;
--删除字段上的统计直方图信息
ANALYZE TABLE test DROP HISTOGRAM ON create_date
1,可以一次性创建多个字段的统计信息,系统会逐个创建列出的字段上的统计信息,统计信息不依赖于索引,这一点与MSSQL不同(当然MSSQL也可以抛开索引独立创建统计信息)
2,BUCKETS值是一个必须提供的参数,默认值为1000,范围是1-1024,这一点也不同与MSSQL也不一样,MSSQL是有一个类似的最大值为200的步长(step)字段
3,一般来说,数据量较大的情况下,对于不重复或者重复性不高的数据,BUCKETS值越大,描述出来的统计信息越详细
4,统计信息的具体内容在 information_schema.column_statistics中,但是可读性并不好,可以根据需求自行解析(出来一种自己喜欢的格式)
与sqlserver中的统计信息一样,理论上,在准确性与取样百分比(BUCKETS)是成正比的,当然生成统计信息的代价也就越大,
至于BUCKETS与统计信息的取样百分比,以及综合代价,笔者暂时没有找到相关的资料。
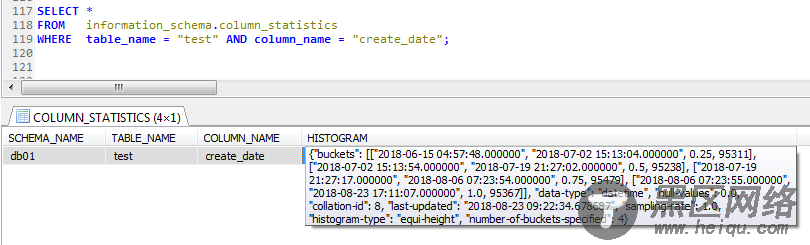
如下是通过ANALYZE TABLE test UPDATE HISTOGRAM ON create_date WITH 4 BUCKETS;创建的统计信息直方图
可以发现直方图的HISTOGRAM字段是一个JSON格式的字符串,可读性并不好。
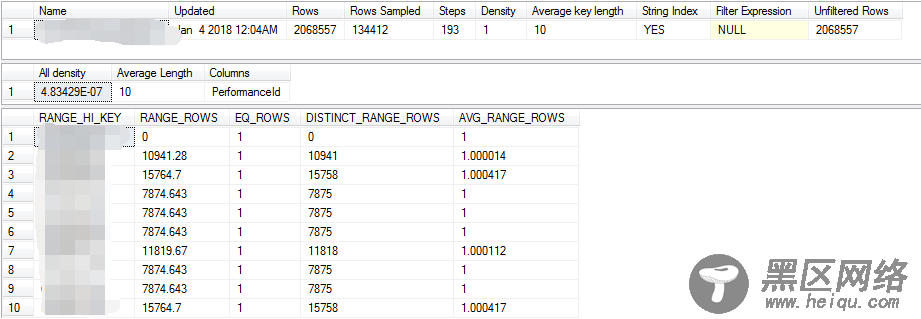
想到了sqlserver中DBCC SHOW_STATISTICS的直方图信息,如下的格式,直方图中的数据分布情况看起来非常清晰直观
于是就做了一个MySQL直方图的格式转换,说白了就是解析information_schema.column_statistics表中的HISTOGRAM 字段中的JSON内容
如下,一个简单的解析直方图统计信息json数据的存储过程,参数分别是库名,表名,字段名
DELIMITER $$
USE `db01`$$
DROP PROCEDURE IF EXISTS `parse_column_statistics`$$
CREATE DEFINER=`root`@`%` PROCEDURE `parse_column_statistics`(
IN `p_schema_name` VARCHAR(200),
IN `p_table_name` VARCHAR(200),
IN `p_column_name` VARCHAR(200)
)
BEGIN
DECLARE v_histogram TEXT;
-- get the special HISTOGRAM
SELECT HISTOGRAM->>'$."buckets"' INTO v_HISTOGRAM
FROM information_schema.column_statistics
WHERE schema_name = p_schema_name
AND table_name = p_table_name
AND column_name = p_column_name;
-- remove the first and last [ and ] char
SET v_histogram = SUBSTRING(v_HISTOGRAM,2,LENGTH(v_HISTOGRAM)-2);
DROP TABLE IF EXISTS t_buckets ;
CREATE TEMPORARY TABLE t_buckets
(
id INT AUTO_INCREMENT PRIMARY KEY,
buckets_content VARCHAR(500)
);
-- split by "]," and get single bucket content
WHILE (INSTR(v_histogram,'],')>0) DO
INSERT INTO t_buckets(buckets_content)
SELECT SUBSTRING(v_histogram,1,INSTR(v_histogram,'],'));
SET v_HISTOGRAM = SUBSTRING(v_histogram,INSTR(v_histogram,'],')+2,LENGTH(v_histogram));
END WHILE;
INSERT INTO t_buckets(buckets_content)
SELECT v_histogram;
-- get the basic statistics data
WITH cte AS
(
SELECT
HISTOGRAM->>'$."last-updated"' AS last_updated,
HISTOGRAM->>'$."number-of-buckets-specified"' AS number_of_buckets_specified
FROM INFORMATION_SCHEMA.COLUMN_STATISTICS
WHERE schema_name = p_schema_name
AND table_name = p_table_name
AND column_name = p_column_name
)
SELECT
CASE WHEN id = 1 THEN p_schema_name ELSE '' END AS schema_name,
CASE WHEN id = 1 THEN p_table_name ELSE '' END AS table_name,
CASE WHEN id = 1 THEN p_column_name ELSE '' END AS column_name,
CASE WHEN id = 1 THEN last_updated ELSE '' END AS last_updated,
CASE WHEN id = 1 THEN number_of_buckets_specified ELSE '' END AS 'number_of_buckets_specified' ,
id AS buckets_specified_index,
buckets_content
FROM
(
SELECT * FROM cte,t_buckets
)t;
END$$
DELIMITER ;