
在这样的背景下,Cloudera公司的一些开发者利用Hiveserver2中现有的授权管理模型,扩展并细化了很多细节,完成了一个相对具有使用价值的授权管理工具Sentry,下图是Sentry与Hiveserver2中的授权管理模型的对比:

Sentry的很多基本模型和设计思路都来源于Hiveserver2,但在其基础之上加强了RBAC的概念。在Sentry中,所有的权限都只能授予角色,当角色被挂载到用户组的时候,该组内的用户才具有相应的权限。权限à角色à用户组à用户,这一条线的映射关系在Sentry中显得尤为清晰,这条线的映射显示了一条权限如何能最后被一个用户所拥有;从权限到角色,再到用户组都是通过grant/revoke的SQL语句来授予的。从“用户组”到能够影响“用户”是通过Hadoop自身的用户-组映射来实现的。Hadoop提供两种映射:一种是本地服务器上的Linux/Unix用户到所在组的映射;另一种是通过LDAP实现的用户到所属组的映射;后者对于大型系统而言更加适用,因为具有集中配置,易于修改的好处。
Sentry将Hiveserver2中支持的数据对象从数据库/表/视图扩展到了服务器,URI以及列粒度。虽然列的权限控制可以用视图来实现,但是对于多用户,表数量巨大的情况,视图的方法会使得给视图命名变得异常复杂;而且用户原先写的针对原表的查询语句,这时就无法直接使用,因为视图的名字可能与原表完全不同。
目前Sentry1.4能够支持的授权级别还局限于SELECT,INSERT,ALL这三个级别,但后续版本中已经能够支持到与Hiveserver2现有的水平。Sentry来源于Hiveserver2中的授权管理模型,但却不局限于只管理Hive,而希望能管理Impala, Solr等其他需要授权管理的查询引擎,Sentry的架构图如下所示:
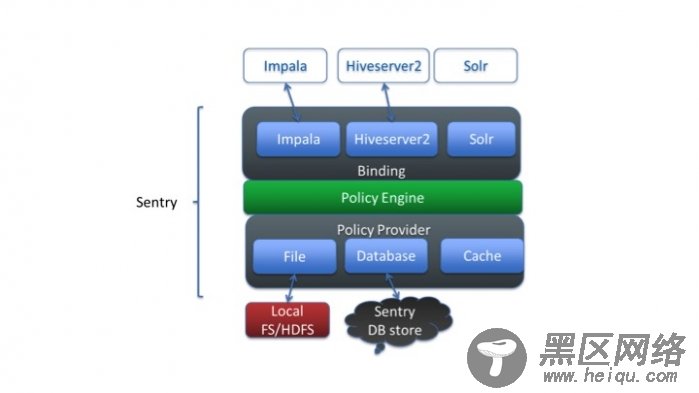
Sentry的体系结构中有三个重要的组件:一是Binding;二是Policy Engine;三是Policy Provider。
Binding实现了对不同的查询引擎授权,Sentry将自己的Hook函数插入到各SQL引擎的编译、执行的不同阶段。这些Hook函数起两大作用:一是起过滤器的作用,只放行具有相应数据对象访问权限的SQL查询;二是起授权接管的作用,使用了Sentry之后,grant/revoke管理的权限完全被Sentry接管,grant/revoke的执行也完全在Sentry中实现;对于所有引擎的授权信息也存储在由Sentry设定的统一的数据库中。这样所有引擎的权限就实现了集中管理。
Policy Engine判定输入的权限要求与已保存的权限描述是否匹配,Policy Provider负责从文件或者数据库中读取出原先设定的访问权限。Policy Engine以及Policy Provider其实对于任何授权体系来说都是必须的,因此是公共模块,后续还可服务于别的查询引擎。
5. 小结大数据平台上细粒度的访问权限控制各家都在做,当然平台厂商方面主导的还是Cloudera和Hortonworks两家,Cloudera主推Sentry为核心的授权体系;Hortonwork一方面靠对开源社区走向得把控,另一方面靠收购的XA Secure。无论今后两家公司对大数据平台市场的影响力如何变化,大数据平台上的细粒度授权访问都值得我们去学习。