
分表的效果是:
当通过Atlas执行(SELECT、 DELETE、 UPDATE、 INSERT、 REPLACE)操作时,
Atlas会根据分表字段结果(id%100=k),定位到相应的子表(stu_k)。
例如,执行
select * from stu where >
但如果执行SQL语句(select * from stu;)时不带上id,则会提示执行stu 表不存在。
Atlas暂不支持自动建表和跨库分表的功能
Atlas目前支持分表的语句有SELECT、 DELETE、 UPDATE、 INSERT、 REPLACE
需要安装非shard版本,sharding版本不支持分表功能
分表设置,此例中person为库名,mt为表名,id为分表字段,3为子表数量,可设置多项,以逗号分隔,若不分表则不需要设置该项
局限性:
应用程序连接atlas分表的时候,查询必须要加where 条件 ,分表字段= 不能用范围查询>,<,或者between and ,不支持全表查询。
例:
mysql> select * from students where >Empty set (0.00 sec)
mysql> select * from students;
ERROR 1146 (42S02): Table 'test.students' doesn't exist
mysql> select * from students where id>2;
ERROR 1146 (42S02): Table 'test.students' doesn't exist
Sharding当前是Atlas的分布式分支, 是Atlas最近重点开发的功能. Sharding的基本思想
就是把一个数据表中的数据切分成多个部分, 存放到不同的主机上去(切分的策略有多种),从而缓解单台机器的性能跟容量的问题. sharding是一种水平切分, 适用于单表数据庞大的情景
Atlas以表为单位sharding, 同一个数据库内可以同时共有sharding的表和不sharding的表, 不sharding的表数据存在未sharding的数据库组中.
目前Atlas sharding支持insert, delete, select, update语句, 所有的写操作如insert,delete, update只能一次命中一个组, 否则会报”ERROR 1105 (HY000):write operationis only allow to one dbgroup!”错误.
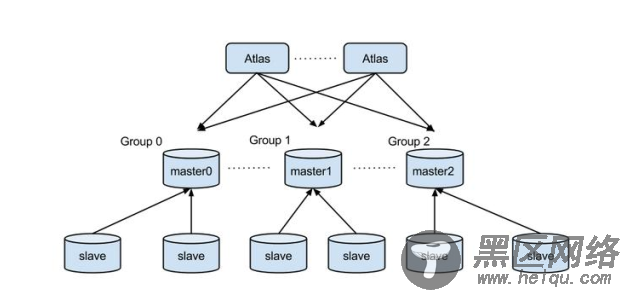
Sharding数据库组
在Atlas中, 将一个组看做是数据存储的单位,一个组由一台master, 零台或者多台slave组成(mysql主从同步需要由用户自己配置). 每个组之间的数据独立, 没有关系, 表的数据的各个部分存储在各个组中.
组内读写分离
与非sharding的方案一样,Atlas sharding也支持组内的读写分离, 也就是说Atlas在命中了某个组之后, 还是会对这个组内的master和slave执行读写分离(读发送到slave, 写发送到master)
Range 方式
范围数据切分方式,比如
shard Key范围在0-1000的数据存放在Group0中,
范围在1000-2000的数据存放在Group1中,
2000-MaxInt 的数据存放在Group2 中.
这些范围的大小不需要相同.比如id为shard key的话, sql: “select * from test where id = 1500;”,
Atlas会将此语句发往Group1. 暂时Atlas的range是静态的, 不支持动态的增加范围
hash 方式
目前Atlas使用取模的方式实现Hash, 也就是说Hash(id) = id % group_count, 如id =10, id % 3 = 1, 所以会命中到DbGroup1中.
Atlas sharding部分新增配置项,包含两个部分:
shardrule. 一个shardrule对应一个分表规则,不同的shardrule通过下划线后面的数字区分。
例如shardrule-0, shardrule-1….。
一个shardrule里面有以下几项:
[shardrule-0]
table = test.sharding_test #分表名,由数据库+表名组成
type = range #sharding类型:range 或 hash
shard-key = id #sharding 字段
groups = 0:0-999,1:1000-1999 #分片的group,
如果是range类型的sharding,则groups的格式是:group_id:id范围。
如果是hash类型的sharding,则groups的格式是:group_id。例如groups = 0, 1
group. 一个group一般包含一主多从,由master(proxy-backend-addresses)和
slave(proxy-read-only-backend-addresses)组成。 group之间的区别也是通过下
划线后面的数字区分。
假设我们有以下一个sharding的表, 建表语句如下:
DROP TABLE IF EXISTS `sharding_test`;
CREATE TABLE `sharding_test` ( `id` int(11) NOT NULL AUTO_INCREMENT,
`name` char(50) COLLATE utf8_bin NOT NULL,
`age` int(11) DEFAULT NULL,
`birthday` date DEFAULT NULL,
`nickname` char(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`id`) );