
ALTER AVAILABILITY GROUP [UbuntuAG] JOIN WITH (CLUSTER_TYPE = EXTERNAL); ALTER AVAILABILITY GROUP [UbuntuAG] GRANT CREATE ANY DATABASE;
下图为添加完节点后的状态:

j) 测试:创建一个DB并加入到刚刚创建的AG中:
CREATE DATABASE [db1]; ALTER DATABASE [db1] SET RECOVERY FULL; BACKUP DATABASE [db1] TO DISK = N'var/opt/mssql/data/db1.bak'; ALTER AVAILABILITY GROUP [UbuntuAG] ADD DATABASE [db1];
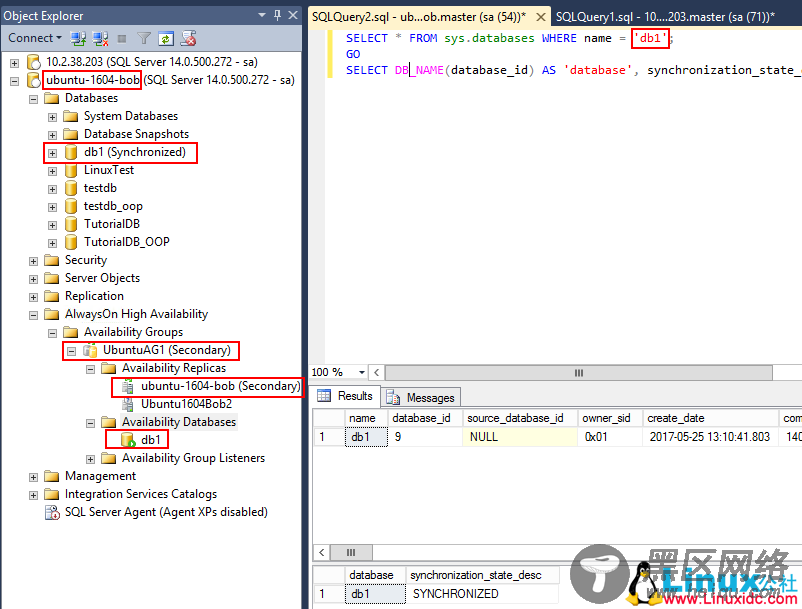
k) 验证:在Secondary端查看DB是否已经成功同步过去了:
SELECT * FROM sys.databases WHERE name = 'db1'; GO SELECT DB_NAME(database_id) AS 'database', synchronization_state_desc FROM sys.dm_hadr_database_replica_states;
这时,一个简单的AG就创建好了,但是它不能提供高可用性和灾难恢复功能,必须配置一个Cluster技术才能好使。如果上述h)和i)步骤的TSQL更换成以下两个,则创建出来的就是read-scale类型的AG。
创建AG命令:
CREATE AVAILABILITY GROUP [UbuntuAG] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'**<node1>**' WITH ( ENDPOINT_URL = N'tcp://**<node1>**:**<5022>**', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL) ), N'**<node2>**' WITH ( ENDPOINT_URL = N'tcp://**<node2>**:**<5022>**', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL) ); ALTER AVAILABILITY GROUP [UbuntuAG] GRANT CREATE ANY DATABASE;
把Secondary节点加到AG中命令: