
[yzyu@dlp ceph-cluster]$ ceph osd pool create cephfs_data 128 ##数据存储池 pool 'cephfs_data' created [yzyu@dlp ceph-cluster]$ ceph osd pool create cephfs_metadata 128 ##元数据存储池 pool 'cephfs_metadata' created [yzyu@dlp ceph-cluster]$ ceph fs new cephfs cephfs_data cephfs_metadata ##创建文件系统 new fs with metadata pool 1 and data pool 2 [yzyu@dlp ceph-cluster]$ ceph fs ls ##查看文件系统 name: cephfs, metadata pool: cephfs_data, data pools: [cephfs_metadata ] [yzyu@dlp ceph-cluster]$ ceph -s cluster 24fb6518-8539-4058-9c8e-d64e43b8f2e2 health HEALTH_WARN clock skew detected on mon.node2 too many PGs per OSD (320 > max 300) Monitor clock skew detected monmap e1: 2 mons at {node1=10.199.100.171:6789/0,node2=10.199.100.172:6789/0} election epoch 6, quorum 0,1 node1,node2 fsmap e5: 1/1/1 up {0=node1=up:active} osdmap e17: 2 osds: 2 up, 2 in flags sortbitwise,require_jewel_osds pgmap v54: 320 pgs, 3 pools, 4678 bytes data, 24 objects 10309 MB used, 30628 MB / 40938 MB avail 320 active+clean
测试Ceph的客户端存储
[root@ceph-client ~]# mkdir /mnt/ceph
[root@ceph-client ~]# grep key /etc/ceph/ceph.client.admin.keyring |awk '{print $3}' >>/etc/ceph/admin.secret
[root@ceph-client ~]# cat /etc/ceph/admin.secret
AQCd/x9bsMqKFBAAZRNXpU5QstsPlfe1/FvPtQ==
[root@ceph-client ~]# mount -t ceph 10.199.100.171:6789:/ /mnt/ceph/ -o name=admin,secretfile=/etc/ceph/admin.secret
[root@ceph-client ~]# df -hT |grep ceph
10.199.100.171:6789:/ ceph 40G 11G 30G 26% /mnt/ceph
[root@ceph-client ~]# dd if=/dev/zero of=/mnt/ceph/1.file bs=1G count=1
记录了1+0 的读入
记录了1+0 的写出
1073741824字节(1.1 GB)已复制,14.2938 秒,75.1 MB/秒
[root@ceph-client ~]# ls /mnt/ceph/
1.file
[root@ceph-client ~]# df -hT |grep ceph
10.199.100.171:6789:/ ceph 40G 13G 28G 33% /mnt/ceph
错误整理
1. 如若在配置过程中出现问题,重新创建集群或重新安装ceph,那么需要将ceph集群中的数据都清除掉,命令如下;
[dhhy@dlp ceph-cluster]$ ceph-deploy purge node1 node2
[dhhy@dlp ceph-cluster]$ ceph-deploy purgedata node1 node2
[dhhy@dlp ceph-cluster]$ ceph-deploy forgetkeys && rm ceph.*
2.dlp节点为node节点和客户端安装ceph时,会出现yum安装超时,大多由于网络问题导致,可以多执行几次安装命令;
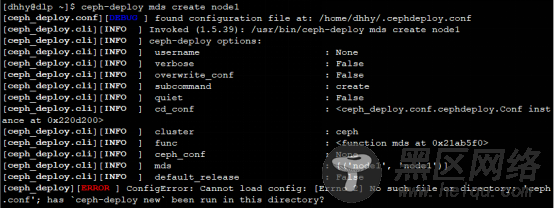
3.dlp节点指定ceph-deploy命令管理node节点配置时,当前所在目录一定是/home/dhhy/ceph-cluster/,不然会提示找不到ceph.conf的配置文件;
4.osd节点的/var/local/osd*/存储数据实体的目录权限必须为777,并且属主和属组必须为ceph;
5. 在dlp管理节点安装ceph时出现以下问题

解决方法:
1.重新yum安装node1或者node2的epel-release软件包;
2.如若还无法解决,将软件包下载,使用以下命令进行本地安装;
6.如若在dlp管理节点中对/home/yzyu/ceph-cluster/ceph.conf主配置文件发生变化,那么需要将其主配置文件同步给node节点,命令如下:
node节点收到配置文件后,需要重新启动进程:

7.在dlp管理节点查看ceph集群状态时,出现如下,原因是因为时间不一致所导致;
将dlp节点的ntpd时间服务重新启动,node节点再次同步时间即可,如下所示:
8.在dlp管理节点进行管理node节点时,所处的位置一定是/home/yzyu/ceph-cluster/,不然会提示找不到ceph.conf主配置文件;
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx