
4、运行Hadoop程序及查看运行日志
当上面的工作准备好了之后,我们运行自己写的Hadoop程序很简单:
$ hadoop jar /usr/mywind/hadoop/share/hadoop/mapreduce/testt.jar com.my.hadoop.test.main.TestHadoop input output
注意这是output文件夹名称不能重复哦,假如你执行了一次,在HDFS文件系统下面会自动生成一个output文件夹,第二次运行时,要么把output文件夹先删除($ hdfs dfs -rmr /user/a01513/output),要么把命令中的output改成其他名称如output1、output2等等。
如果看到以下输出结果,证明你的运行成功了:
a01513@hadoop :~$ hadoop jar /usr/mywind/hadoop/share/hadoop/mapreduce/testt.jar com.my.hadoop.test.main.TestHadoop input output
14/09/02 11:14:03 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0 :8032
14/09/02 11:14:04 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0 :8032
14/09/02 11:14:04 WARN mapreduce.JobSubmitter: Hadoop command-line option parsin g not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
14/09/02 11:14:04 INFO mapred.FileInputFormat: Total input paths to process : 1
14/09/02 11:14:04 INFO mapreduce.JobSubmitter: number of splits:2
14/09/02 11:14:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_14 09386620927_0015
14/09/02 11:14:05 INFO impl.YarnClientImpl: Submitted application application_14 09386620927_0015
14/09/02 11:14:05 INFO mapreduce.Job: The url to track the job: :80 88/proxy/application_1409386620927_0015/
14/09/02 11:14:05 INFO mapreduce.Job: Running job: job_1409386620927_0015
14/09/02 11:14:12 INFO mapreduce.Job: Job job_1409386620927_0015 running in uber mode : false
14/09/02 11:14:12 INFO mapreduce.Job: map 0% reduce 0%
14/09/02 11:14:21 INFO mapreduce.Job: map 100% reduce 0%
14/09/02 11:14:28 INFO mapreduce.Job: map 100% reduce 100%
14/09/02 11:14:28 INFO mapreduce.Job: Job job_1409386620927_0015 completed successfully
14/09/02 11:14:29 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=105
FILE: Number of bytes written=289816
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1638
HDFS: Number of bytes written=10
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=14817
Total time spent by all reduces in occupied slots (ms)=4500
Total time spent by all map tasks (ms)=14817
Total time spent by all reduce tasks (ms)=4500
Total vcore-seconds taken by all map tasks=14817
Total vcore-seconds taken by all reduce tasks=4500
Total megabyte-seconds taken by all map tasks=15172608
Total megabyte-seconds taken by all reduce tasks=4608000
Map-Reduce Framework
Map input records=9
Map output records=9
Map output bytes=81
Map output materialized bytes=111
Input split bytes=208
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=111
Reduce input records=9
Reduce output records=1
Spilled Records=18
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=115
CPU time spent (ms)=1990
Physical memory (bytes) snapshot=655314944
Virtual memory (bytes) snapshot=2480295936
Total committed heap usage (bytes)=466616320
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1430
File Output Format Counters
Bytes Written=10
a01513@hadoop :~$
我们可以到Eclipse查看输出的结果:
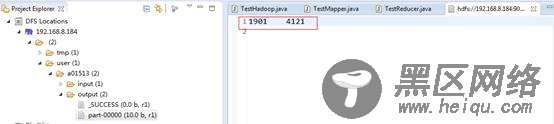
或者用命令行查看:
$ hdfs dfs -cat output/part-00000
假如你们发现运行后结果是为空的,可能到日志目录查找相应的log.info输出信息,log目录在:/usr/mywind/hadoop/logs/userlogs 下面。
好了,不太喜欢打字,以上就是整个过程了,欢迎大家来学习指正。