如果你所在公司的开发环境或者项目的开发环境处于单一语言的开发环境之中,框架不适用,因为框架的使用范围之一就是针对一个项目中存在多个语言开发的业务模块,而新项目都需要这些模块的功能,按照以前的习惯,肯定是重新开发,至少也是将其他的语言开发的业务功能变成webservice接口供新代码调用,在这种情况下,本文讨论的框架就可以派上用场并且还能在客户端消除语言差异,只使用纯javascript和html静态代码进行开发。
当然即使在单一的语言环境下,仍然可以使用该模型进行开发,不过开发人员就无法享受到各种优秀的服务端控件(Asp.net控件,专门为java开发的控件等等),只能使用纯javascript控件,这会对开发人员造成不方便(特别是依赖服务端控件的开发人员尤其如此)。
经过以上两篇博文的谈论,我们发现这种模型是完全有用武之地的,它将服务端的语言彻底和客户端分离,开发客户端的人员(在理论条件下)可以完全忽略服务端的语言种类,只进行纯Javascript开发,利用JQUERY中提供的AJAX方法同服务端方法通信。
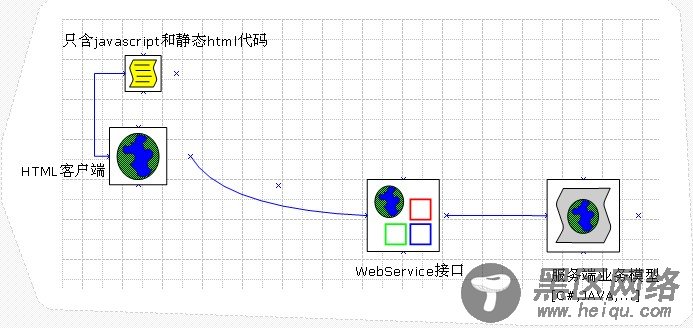
从上面的整体架构图,我们看出:其客户端都是WebService接口来获取数据和传送数据的,而服务端业务模型是什么语言开发的,完全不需要关注(当然在现实情况下,一般WebService接口最好同服务端业务模型是一个语言开发的)。
这个时候可以会首先想到效率的问题:
众所周知,WebService接口的效率较慢,那么这样搞是不是会让采用这种结构模型开发的网站速度变慢,与其这样,还不如采用常规的方法开发,不仅熟悉而且速度也不错呢?
先看下面几个推论:
1)WebService接口的效率慢 <---> 异步获取数据 ,两者互相能够抵消吗?
2)客户端采用Post的方式,可以减少数据的量,能部分抵消WebService接口的效率慢吗?
以上两个推论,虽然我们没完全做过对比,但可以肯定的说,它们是有对冲效率的,WebService慢,反映在页面端无怪乎就是页面等待长时间不出来,造成用户体验下降,但因为采用异步获取的方式,这种情况还会出现吗?应该不会。
在传送过程中,采用Post方式,数据量大大减少,又采用了异步方式,实际运行效果应该是相当不错的。
但对于某些特殊情况并且有很普遍的问题,比如Table表格的分页情况,我们又该怎么处理呢?
Table表格数据填充和分页 这个在页面上非常普遍的问题确对以上的推论造成了威胁,究其原因就是因为一般的分页代码都是把数据返回到客户端内存中,然后进行分页,因此大量的数据从服务端传递到客户端,必然造成问题,其实这个问题不仅仅是这个框架的问题,所有采用这种方式进行分页的代码都存在这样的问题,只不过这个框架采用WebService接口与客户端通信,才导致这个问题的重要性被无限放大了。
以下我们就来讨论在这种框架下进行分页的处理:
环境:Visual studio 2005
JQuery 1.3.2
SQLServer2005
分页原理:
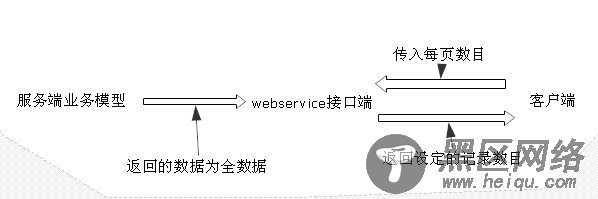
从上图中,看到不管数据表中有多少数据,每次返回到客户端的数据都是一页的数据,这种方法没有采用存储过程方式,而是在webservice端进行处理的。
代码片段:
服务端填充Table表格代码----:
说明:
TB_WEB_NZ_INVESTMENT 是实体类,对应表对象
FlowID 表对象的字段属性,通过它获取一类相似的数据记录
代码中有对【首页】,【尾页】,【中间页】的元素进行过滤,对返回的泛型List对象进行范围过滤
复制代码 代码如下:
/// <summary>
/// 分页功能的表格填充服务端
/// </summary>
/// <param></param>
/// <param>每页数目</param>
/// <param>当前页</param>
/// <returns></returns>
[WebMethod]
[ScriptMethod(ResponseFormat = ResponseFormat.Json)]
public string Load_ContributivePerson_Table(string FlowID, int PageCount, int CurrentPage)
{
List<TB_WEB_NZ_INVESTMENT> list = new List<TB_WEB_NZ_INVESTMENT>();
list = objBusinessFacade.GetTB_WEB_NZ_INVESTMENT_CollectionByFlowID(FlowID);
int TotalPageCount = 0;
if (PageCount != 0)
{
if ((list.Count % PageCount) > 0)
{
TotalPageCount = list.Count / PageCount + 1;
}
else
{
TotalPageCount = list.Count / PageCount;
}
}//if
if (CurrentPage == 1)
{
//第一页
if (PageCount < list.Count)
{
list.RemoveRange(PageCount, list.Count - PageCount);
}
}
else if (CurrentPage > 1 && CurrentPage < TotalPageCount)
{
//中间页
int R1 = (CurrentPage - 1) * PageCount-1;
int R2 = CurrentPage * PageCount;
List<TB_WEB_NZ_INVESTMENT> list1 = new List<TB_WEB_NZ_INVESTMENT>();
for (int i = 0; i < list.Count; i++)
{
if (i > R1&&i<R2)
{
list1.Add(list[i]);
}
}
list.Clear();
list = list1;
}
else if (CurrentPage == TotalPageCount)
{
//尾页
//但返回的显示对象列表确只能是最后一页里面的记录
//这里需要剔除不是最后一页的元素对象
list.RemoveRange(0,(CurrentPage-1) * PageCount);
}
return new JavaScriptSerializer().Serialize(list);
}
原理说明图:-----------------------

结合以上代码和该图讲解:
1)首页操作:
list.RemoveRange(PageCount, list.Count - PageCount);
翻译成数字:list.RemoveRange(5,14-5);
首页显示的元素:A1 A2 A3 A4 A5 对应的索引:0 1 2 3 4
list.RemoveRange(5,14-5); //排除索引值为5(含自身)的后面的所有元素,这样列表中只有A1-A5 元素
2)中间页操作:(这里就是第2页)
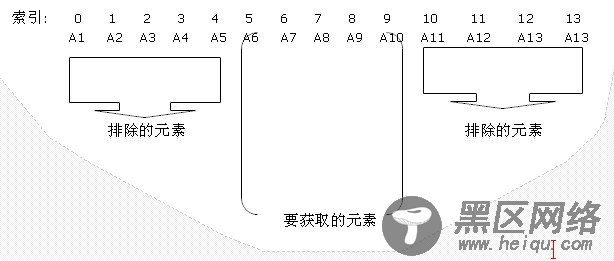
CurrentPage 等于 2
int R1 = (CurrentPage - 1) * PageCount-1; 等于4
int R2 = CurrentPage * PageCount; 等于10
R1 和R2 代表两个区间范围索引,即在索引4(不含索引4) 到 索引10(不含索引10) 之间的元素,是我们要取出的元素
复制代码 代码如下: