近年来各站点基于 Web 的多终端适配进行得如火如荼,行业间也发展出依赖各种技术的解决方案。有如基于浏览器原生 CSS3 Media Query 的响应式设计、基于云端智能重排的「云适配」方案等。本文则主要探讨在前后端分离基础下的多终端适配方案。
关于前后端分离
关于前后端分离的方案,在《基于NodeJS的前后端分离的思考与实践(一)》中有非常清晰的解释。我们在服务端接口和浏览器之间引入 NodeJS 作为渲染层,因为 NodeJS 层彻底与数据抽离,同时无需关心大量的业务逻辑,所以十分适合在这一层进行多终端的适配工作。
UA 探测
进行多终端适配首先要解决的是 UA 探测问题,对于一个过来的请求,我们需要知道这个设备的类型才能针对对它输出对应的内容。现在市面上已经有非常成熟的兼容大量设备的 User Agent 特征库和探测工具,这里有 Mozilla 整理的一个列表。其中,既有运行在浏览器端的,也有运行在服务端代码层的,甚至有些工具提供了 Nginx/Apache 的模块,负责解析每个请求的 UA 信息。
实际上我们推荐最后一种方式。基于前后端分离的方案决定了 UA 探测只能运行在服务器端,但如果把探测的代码和特征库耦合在业务代码里并不是一个足够友好的方案。我们把这个行为再往前挪,挂在 Nginx/Apache 上,它们负责解析每个请求的 UA 信息,再通过如 HTTP Header 的方式传递给业务代码。
这样做有几点好处:
我们的代码里面无需再去关注 UA 如何解析,直接从上层取出解析后的信息即可。如果在同一台服务器上有多个应用,则能够共同使用同一个 Nginx 解析后的 UA 信息,节省了不同应用间的解析损耗。

来自天猫分享的基于 Nginx 的 UA 探测方案
淘宝的 Tengine Web 服务器也提供了类似的模块 ngx_http_user_agent_module。
值得一提的是,选用 UA 探测工具时必须要考虑特征库的可维护性,因为市面上新增的设备类型越来越多,每个设备都会有独立的 User Agent,所以该特征库必须提供良好的更新和维护策略,以适应不断变化的设备。
建立在 MVC 模式中的几种适配方案
取得 UA 信息后,我们就要考虑如果根据指定的 UA 进行终端适配了。即使在 NodeJS 层,虽然没有了大部分的业务逻辑,但我们依然把内部区分为 Model / Controller / View 三个模型。

我们先利用上面的图,去解析一些已有的多终端适配方案。
建立在 Controller 上的适配方案
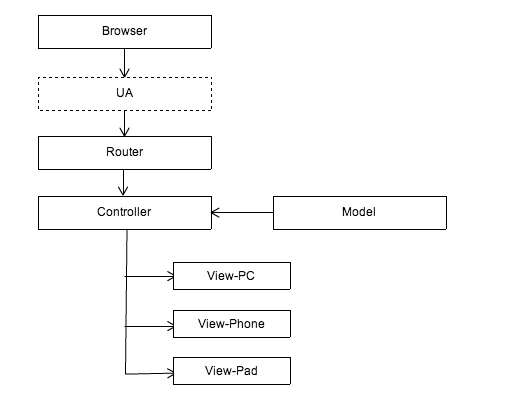
这种方案应该是最简单粗暴的处理方法。通过路由(Router)将相同的 URL 统一传递到同一个控制层(Controller)。控制层再通过 UA 信息将数据和模型(Model)逻辑派发到对应的展现(View)进行渲染,渲染层则按预先的约定提供了适配几个终端的模板。
这种方案的好处是,保持了数据和控制层的统一性,业务逻辑只需处理一次遍可以应用在所有终端上。但这种场景只适合如展示型页面等低交互型的应用,一旦业务比较复杂,各个终端的 Controller 可能有各自的处理逻辑,如果还是共用一个 Controller ,会导致 Controller 非常的臃肿而且难以维护,这无疑是一个错误的选择。
建立在 Router 上的适配方案
为了解决上面遇到的问题,我们可以在 Router 上就将设备区分,针对不同的终端分发到不同的 Controller 上:

这也是最常见的方案之一,大多表现在针对不同终端使用各自独立的一套应用。如 PC 淘宝首页和 WAP 版的淘宝首页,不同设备访问 ,服务器会通过 Router 的控制,重定向到 WAP 版的淘宝首页或者 PC 版的淘宝首页,它们各自是完全独立的两套应用。
但这种方案无疑带来了数据和部分逻辑无法共用的问题,各种终端之间无法分享同一份数据和业务逻辑,产生大量重复性工作,效率低下。
为了缓解这个问题,有人提出了优化后的方案:依然是在同一套应用里面,各个数据来源抽象成各个 Model,提供给不同终端的 Controller 组合使用:

这个方案解决了前面数据无法共用的问题。在 Controller 上各个终端还是相互独立,但能共同使用同一批数据源,至少在数据上无需再针对终端类型开发独立的接口了。