我们看这么一段代码,这段代码我大致分成了四个部分,第一部分用于获取文件通道,第二部分用于分配缓存区并完成读操作,第三部分用于将缓存区中数据进行打印,第四部分为关闭通道连接。
第一部分:getChannel 方法用于获取一个文件相关的通道实例,具体实现如下:


getChannel 方法会调用 FileChannelImpl 的工厂方法构建一个 FileChannelImpl 实例,FileChannelImpl 是抽象类 FileChannel 的一个子类实现。
构成 FileChannelImpl 实例所需的必要参数有,该文件的文件指针,该文件的完整路径,读写权限等。
第二部分:Buffer 的基本结构我们上述已经简单介绍了,这里不再赘述了,所谓的缓存区,本质上就是字节数组。

ByteBuffer 实例的构建是通过工厂模式产生的,必须指定参数 capacity 作为内部字节数组的容量。HeapByteBuffer 是虚拟机的堆上内存,所有数据都将存储在堆空间,我们不久将会介绍它的一个兄弟,DirectByteBuffer,它被分配在堆外内存中,具体的一会说。
这个 HeapByteBuffer 的构造情况我们不妨跟进去看看:

调用父类的构造方法,初始化我们在 ByteBuffer 中提过的一些属性值,如 position,capacity,mark,limit,offset 以及字节数组 hb。
接着,我们看看这个 read 方法的调用链。
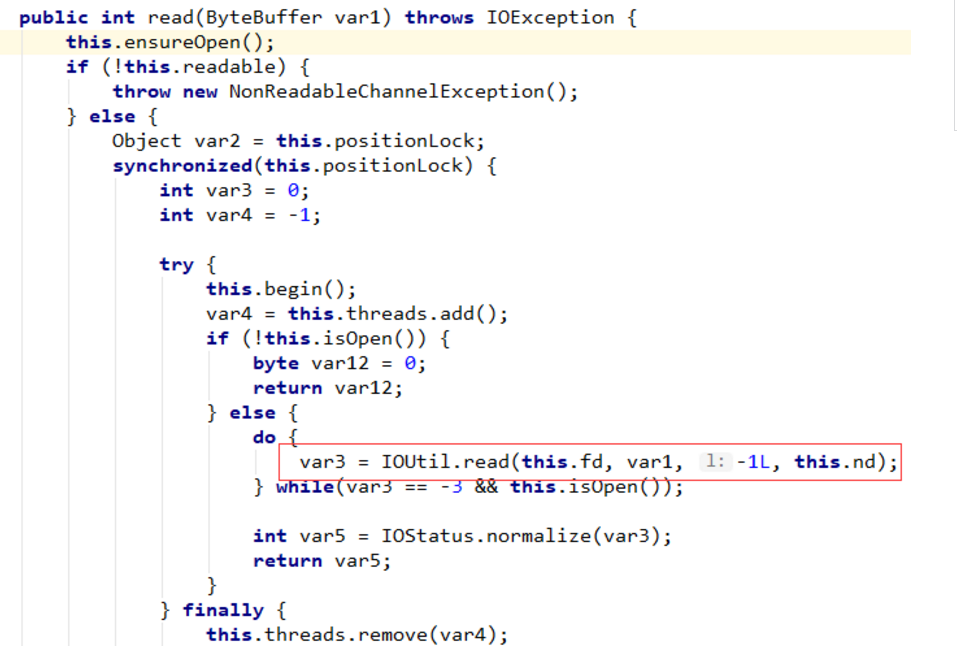
这个 read 方法是子类 FileChannelImpl 对父类 FileChannel read 方法的重写。这个方法不是读操作的核心,我们简单概括一下,该方法首先会拿到当前通道实例的锁,如果没有被其他线程占有,那么占有该锁,并调用 IOUtil 的 read 方法。
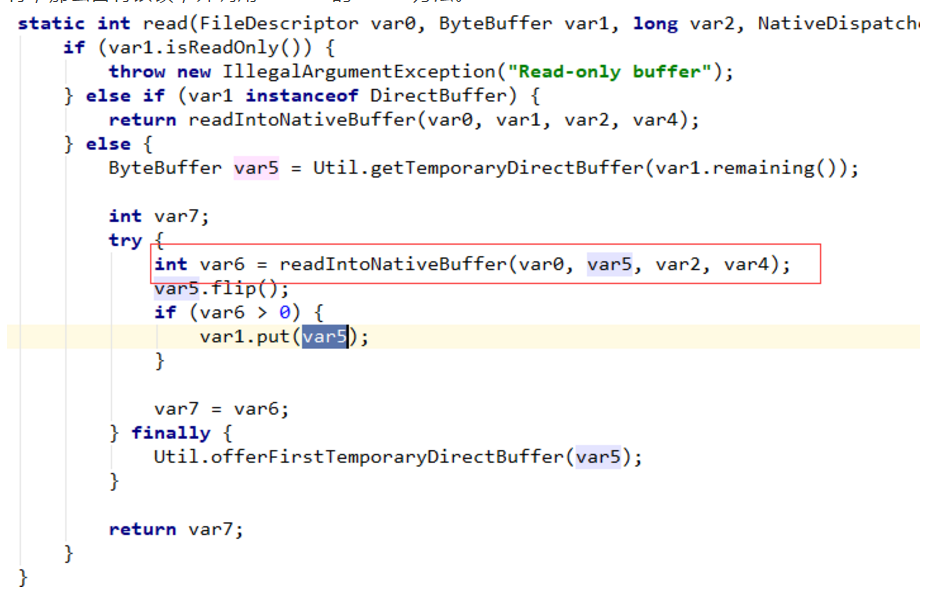
IOUtil 的 read 方法内部也调用了很多方法,有的甚至是本地方法,这里只简单介绍一下整个 read 方法的大体逻辑,具体细节留待大家自行学习。
首先判断我们的 ByteBuffer 实例是不是一个 DirectBuffer,也就是判断当前的 ByteBuffer 实例是不是被分配在直接内存中,如果是,那么将调用readIntoNativeBuffer 方法从磁盘读取数据直接放入 ByteBuffer 实例所在的直接内存中。
否则,虚拟机将在直接内存区域分配一块内存,该内存区域的首地址存储在 var5 实例的 address 属性中。
接着从磁盘读取数据放入 var5 所代表的直接内存区域中。
最后,put 方法会将 var5 所代表的直接内存区域中的数据写入到 var1 所代表的堆内缓存区并释放临时创建的直接内存空间。
这样,我们传入的缓存区中就成功的被读入了数据。写操作是相反的,大家可以自行类比,反正堆内数据想要到达磁盘就必定要经过堆外内存的复制过程。
第三第四部分比较简单,这里不再赘述了。提醒一下,想要更好的使用这个通道和缓存区进行文件读写操作,你就一定得对缓存区的几个变量的值时刻把握住,position 和 limit 当前的值是什么,大致什么位置,一定得清晰,否则这个读写共存的缓存区可能会让你晕头转向。
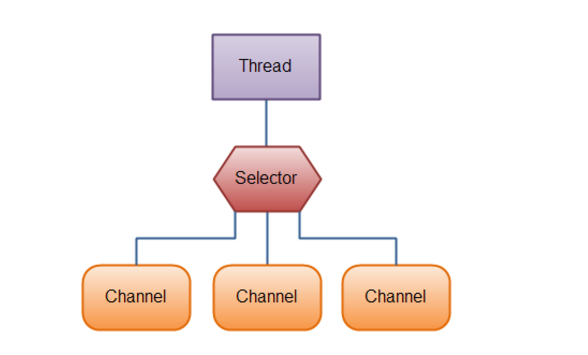
选择器 SelectorSelector 是 Java NIO 的一个组件,它用于监听多个 Channel 的各种状态,用于管理多个 Channel。但本质上由于 FileChannel 不支持注册选择器,所以 Selector 一般被认为是服务于网络套接字通道的。
而大家口中的「NIO 是非阻塞的」,准确来说,指的是网络编程中客户端与服务端连接交换数据的过程是非阻塞的。普通的文件读写依然是阻塞的,和 IO 是一样的,这一点可能很多初学者会懵,包括我当时也总想不通为什么说 NIO 的文件读写是非阻塞的,明明就是阻塞的。
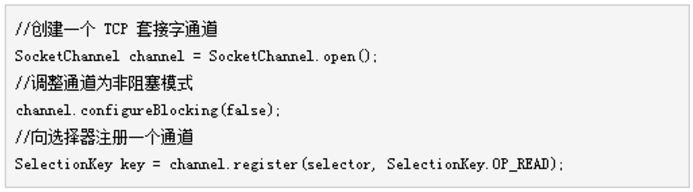
创建一个选择器一般是通过 Selector 的工厂方法,Selector.open :
而一个通道想要注册到某个选择器中,必须调整模式为非阻塞模式,例如: