
被动推送是采用部署日志收集 Agent 进行采集的,有两种方式,一种是 Daemonset 每个机器节点上部署一个 Agent,还有一种 Sidecar,每个 Pod 以 Sidecar 的形式部署一个 Agent。
Sidecar 部署方式比较消耗资源,相当于每个 Pod 都有一个 agent,但是这种方式 灵活性以及隔离性较强,适合大型的 K8s 集群或者作为 PaaS 平台为业务方提供服务的群使用,Daemonset 部署方式,资源消耗较小,适合功能单一、业务不多的集群。
结合我们自身的场景,属于小规模集群,并且业务也不算多,我们选择了 Daemonset 的部署方式,在测试环境,我们经过调研选择了阿里开源的一个日志收集组件log-pilot GitHub 地址是:github.com/AliyunContainerService/log-pilot ,通过结合 Elasticsearch、Kibana 等算是一个不错的 K8s 日志解决方案。
因为我们的服务器都在阿里云上,我们运维人员比较少只有2位,没有精力再去维护一个大型的分布式存储集群,所以我们的业务日志选择存储在了阿里云的日志服务,所以在生产环境,我们的 K8s 也使用了阿里云日志服务,目前单日日志 6亿+ 没有任何问题。
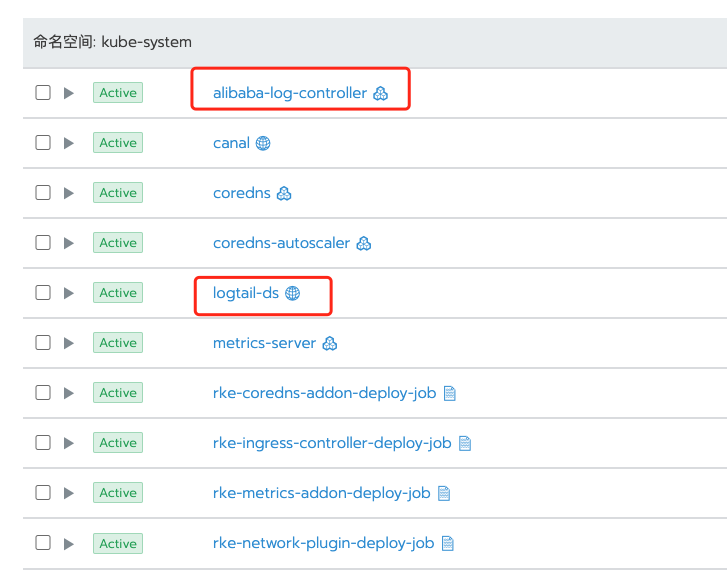
使用阿里云收集日志呢,你需要开通阿里云的日志服务,然后安装 Logtail 日志组件 alibaba-log-controller Helm,这个在官方文档里有安装脚本,我把文档链接贴在下面,在安装组件的过程中会自动创建aliyunlogconfigs CRD,部署alibaba-log-controller的Deployment,最后以 DaemonSet 模式安装 Logtail。然后你就可以在控制台,接入你想要收集的日志了。安装完以后是这样的:
Logtail支持采集容器内产生的文本日志,并附加容器的相关元数据信息一起上传到日志服务。Kubernetes文件采集具备以下功能特点:
只需配置容器内的日志路径,无需关心该路径到宿主机的映射
支持通过Label指定采集的容器
支持通过Label排除特定容器
支持通过环境变量指定采集的容器
支持通过环境变量指定排除的容器
支持多行日志(例如java stack日志)
支持Docker容器数据自动打标签
支持Kubernetes容器数据自动打标签
如果你想了解更多,可以查看阿里云日志服务的官方文档:
https://help.aliyun.com/document_detail/157317.html?spm=a2c4g.11186623.6.621.193c25f44oLO1V
容器的多租户隔离我这里所讲的,主要指的是企业内部用户的多租户隔离,而不是指的 SaaS、KaaS 服务模型的多租户隔离。
在权限方面,因为我司对于权限的管控较严格,而 Rancher 恰好提供了非常方便的基于 集群、项目、命名空间等多个粒度的权限控制,并且支持我司基于 OpenLDAP 的认证协议,非常便于管理,我可以给不同项目组的开发、测试人员开通相对应的 集群/项目/命名空间的权限。
比如下图,我可以给集群添加用户、也可以给某个 Project 添加用户,并且可以指定几个不同的角色,甚至可以自定义角色。
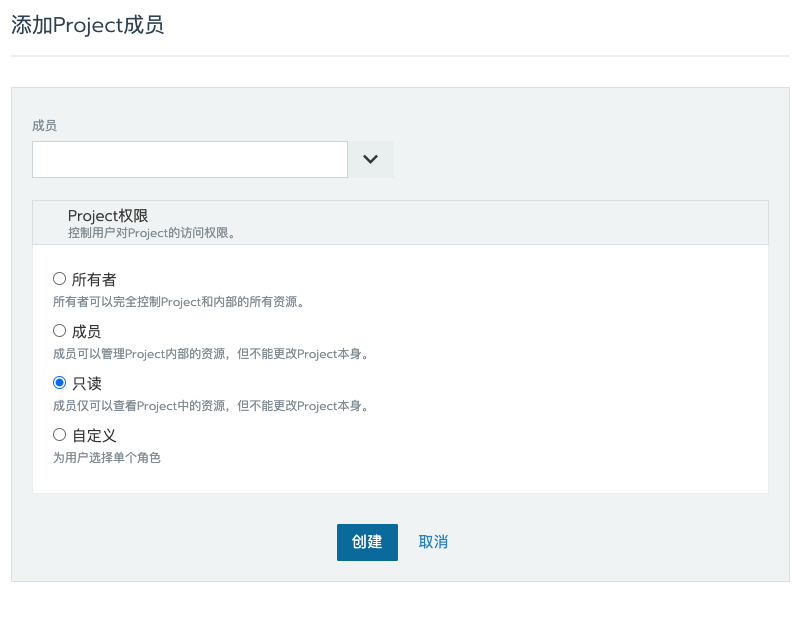
比如场景1:我可以给 项目组长,分配开发环境集群->项目1 所有者(Owner)权限,然后项目组长可以自由控制给本项目添加他的成员,并分配相应权限。
场景2:我可以给 测试经理,分配测试集群的所有者(Owner)权限,由测试经理来分配,谁来负责哪个项目的测试部署,以及开发人员只能查看日志等。
在资源方面,一定要进行容器的资源配额设置,如果不设置资源限额,一旦某一个应用出现了性能问题,将会影响整个 node 节点上的所有应用,K8s 会将出现问题的应用调度到其他 node 上,如果你的资源不够,将会出现整个系统的瘫痪,导致雪崩。
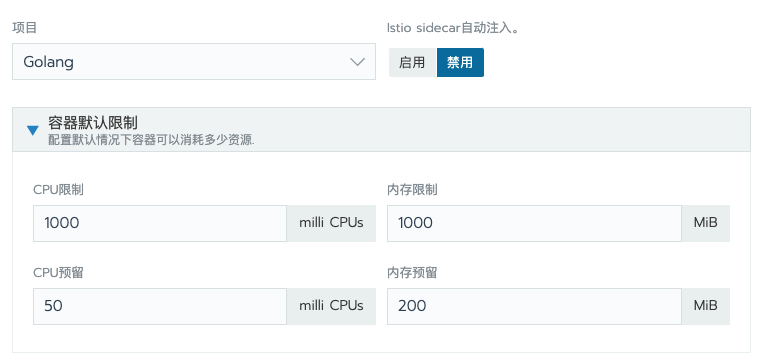
Java 应用的资源配额限制也有一个坑,因为默认 Java 是通过 /proc/meminfo 来获取内存信息的,默认 JVM 会使用系统内存的 25% 作为 Max Heap Size,但是容器内的/proc/meminfo是宿主机只读模式挂载到容器里的,所以采取默认值是行不通的,会导致应用超过容器限制的内存配额后被OOM,而健康检查又将服务重启,造成应用不断的重启。
那是不是通过手动参数设置 JVM 内存 = 容器内存限额呢?不行!因为 JVM消耗的内存不仅仅是 Heap,因为 JVM 也是一个应用,它需要额外的空间去完成它的工作,你需要配置的限额应该是 Metaspace + Threads + heap + JVM 进程运行所需内存 + 其他数据 关于这块,因为涉及到的内容较多,就不进行展开,感兴趣的同学可以自己去搜索 一下。
总 结