
zscore sport:ranking:why:20210227 jay
66079,步数也有了。
现在我们知道了:why 的好友 jay 今日运动步数 66079 步,在 why 的微信好友中排第一名。
但是你仔细看,这上面我还漏了两个字段:
微信头像
朋友点赞个数
两个字段应该怎么放呢?
放数据库里面当然可以,但是我们主要还是说一下 Redis 的解决方案。
这个时候其实我们想要存储的是 User 对象,对象里面有这几个字段:昵称、头像图片链接、点赞数、步数。
你说,这个用 Redis 的啥数据结构来存?
可不就得用 Hash 结构了吗。
Hash 结构同样涉及到 key 和 value,那么它们分别是什么呢?
key 就是我们的有序集合的 key 后面再加上好友昵称,比如这样的:
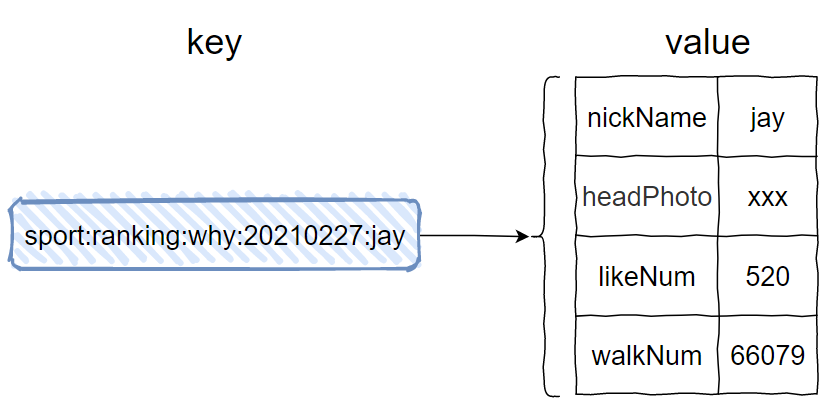
对应的命令是这样的:
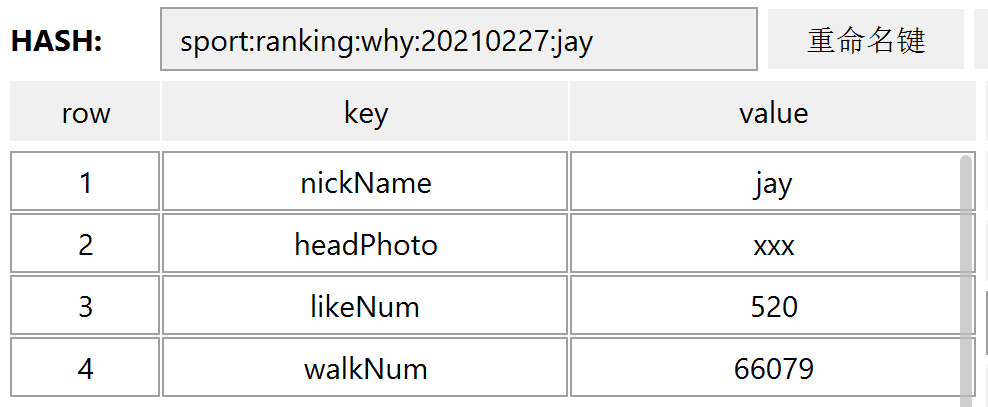
hmset sport:ranking:why:20210227:jay nickName jay headPhoto xxx likeNum 520 walkNum 66079
执行完成之后,在 RDM 里面看起来是这样的:
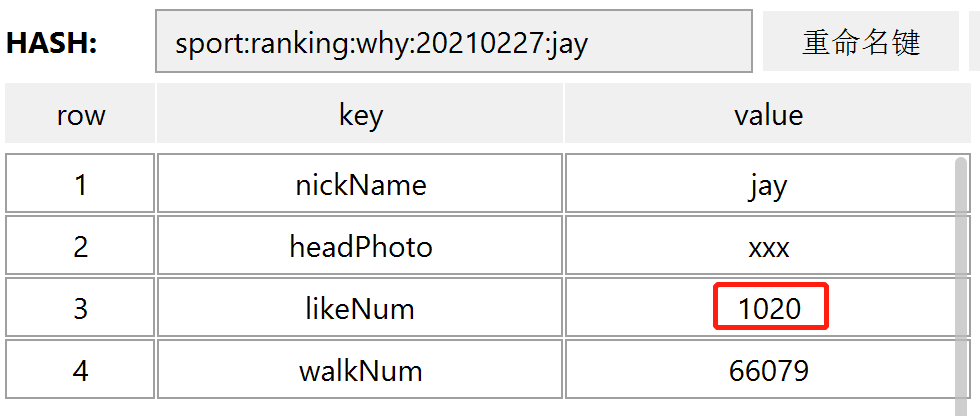
当后续有更多的赞的时候,需要调用更新命令更新 likeNum:
hincrby sport:ranking:why:20210227:jay likeNum 500
执行完成之后点赞数就会变成 1020:
这样,排行榜上的所有字段我们都能获取到了,微信排行榜就说完了。
呃......
怎么感觉还是 API 教学呢?
不得劲,换个其他的。

前面我们说的都是每日排行榜。
假设面试官要求我们提供一个最近七天、上一周、上一月、上个季度、这一年排行榜啥的,又该怎么搞呢?
其实这还是在考察你对于 Redis 有序集合 API 的掌握程度。
也就是这个 API:
zinterstore/zunionstore destination numkeys key [key ...] [weights weight [weight ...]] [aggregate sum|min|max] 获取交集/并集
这个 API 看起来有点复杂,不要怕,一个个的讲:
zinterstore/zunionstore其实就是交集/并集
destination 将交集/并集的结果保存到这个键中
numkeys 需要做交集/并集的集合的个数
key [key ...] 具体参与交集/并集的集合
weights weight [weight ...] 每个参与计算的集合的权重。在做交集/并集计算时,每个集合中的 member 会把自己的 score 乘以这个权重,默认为 1。
aggregate sum|min|max 对于各个集合中的相同元素是 sum(求和)、min(取最小值)还是max(取最大值),默认为 sum。
拿最近七天举例,我们随便搞点数据进来,你可以直接粘过去玩:
zadd sport:ranking:why:20210222 43243 why 2341 mx 8764 les 42321 skr
zadd sport:ranking:why:20210223 57632 why 24354 mx 4231 les 43512 skr 5341 jay
zadd sport:ranking:why:20210224 10026 why 12344 mx 54312 les 34531 skr 43512 jay
zadd sport:ranking:why:20210225 54312 why 32451 mx 23412 les 21341 skr 56321 jay
zadd sport:ranking:why:20210226 3212 why 63421 mx 53652 les 45621 skr 5723 jay
zadd sport:ranking:why:20210227 5462 why 10158 mx 30169 les 48858 skr 66079 jay
zadd sport:ranking:why:20210228 43553 why 4451 mx 7431 les 9563 skr 8232 jay
可以看到我们一共有 7 天的数据:
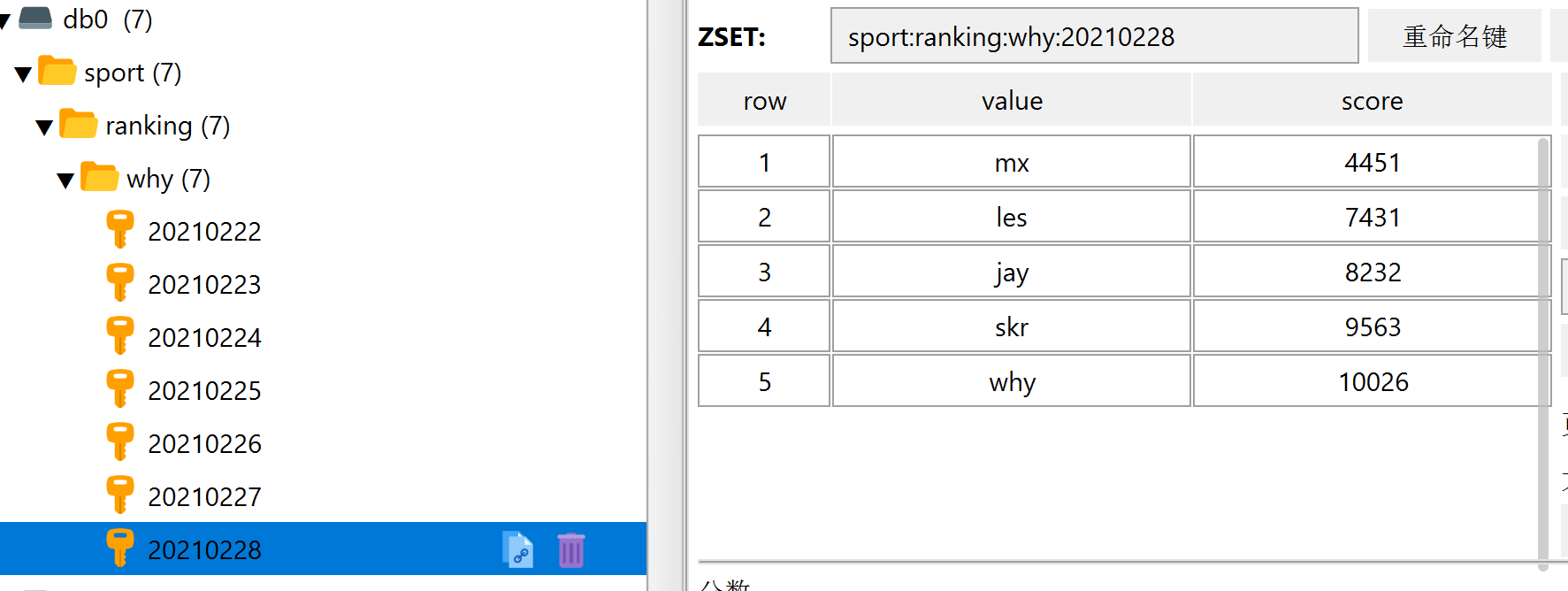
而且需要注意的是 20210222 这一天是没有 jay 的数据的。
现在我们要求出最近 7 天的排行榜,就用下面这行命令,命令有点复杂,但是对着命令格式看,还是很清晰的: