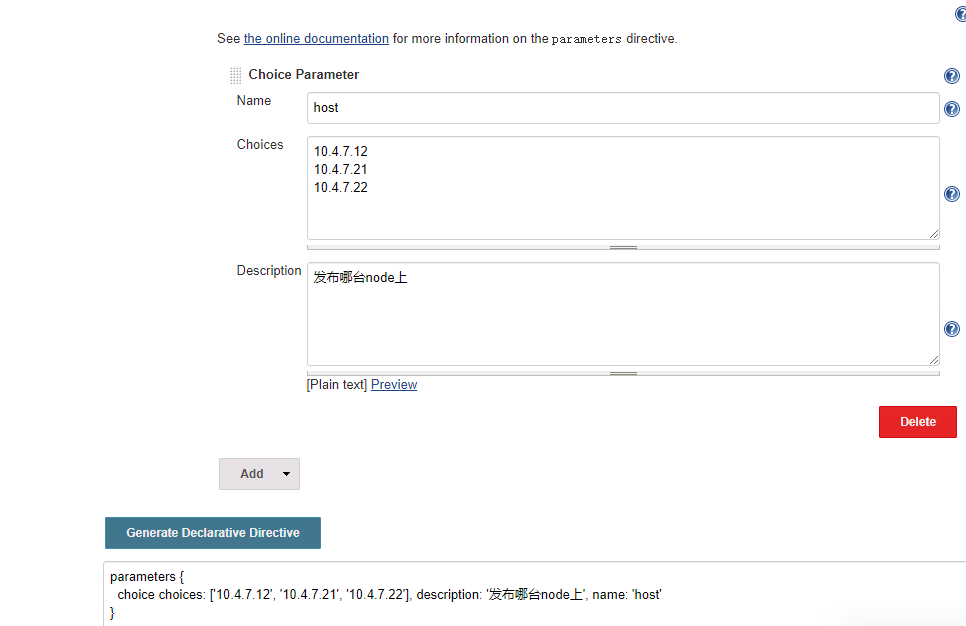
将这个出产的语法,复制到pipeline语法中
choice choices: ['10.4.7.12', '10.4.7.21', '10.4.7.22'], description: '宣布哪台node上', name: 'host'
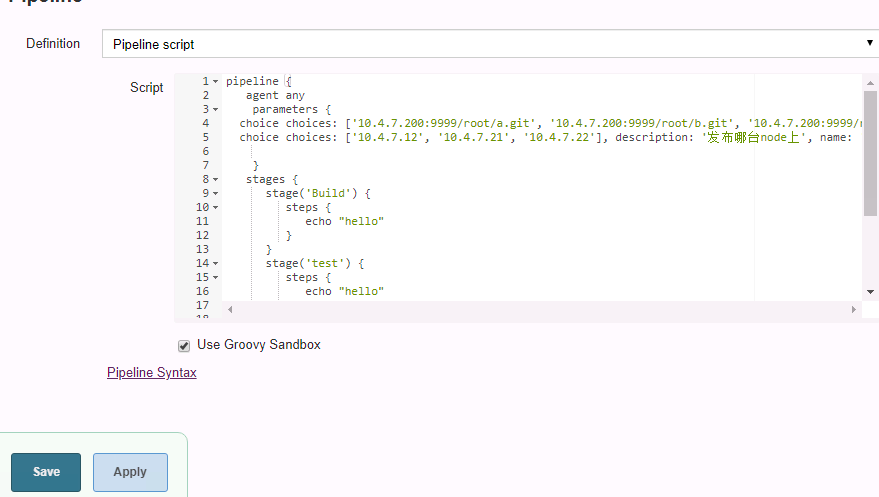
构建一下,发明也可以利用选择型参数了,雷同这个的人工交互就可以选择多个参数了,可以写一个通用的模版,就处理惩罚人工交互的逻辑
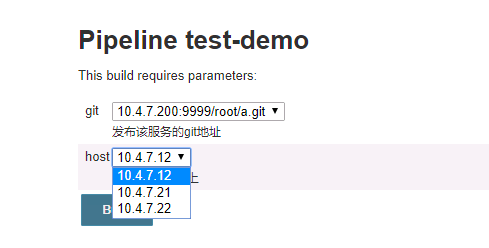
此刻我们可以去人工选择了,这内里的值怎么获取到,我们处理惩罚差异的项目,必需在这内里去实现,好比选择这个git之后,拉取这个代码编译构建,这些大概都是一些沟通点,差异点宣布的呆板纷歧样,所以要选择用户是拿到的哪个git地点,宣布的哪个呆板,在剧本里去拿到,其实默认这个name就是一个变量,jenkins已经将这个赋予变量,而且pipeline可以直接获取这个变量名,就是适才界说的git,host这个名字,那么我们从适才配置的parameters里去测试这个变量可不行以拿到,拿到的话说明这个就很好去处理惩罚
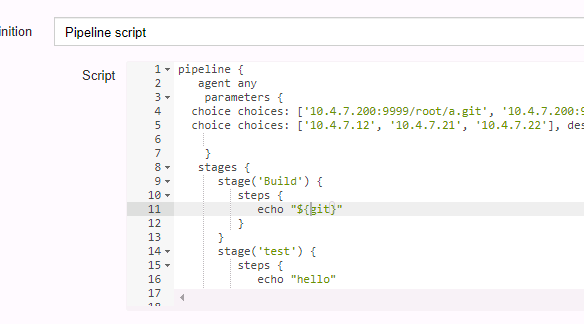
构建一下,此刻构建乐成后已经是构建乐成了,也已经获取到适才我们的git这个参数下的值了

有了这些方法,就可以将这些差异点通过内里的agent和shell脚原来处理惩罚了,写pipeline参数化构建就是满意更多的一个需求,能适配更多的项目,能让人工过问的做一些巨大的任务
五、jenkins在k8s中动态建设署理
如安在k8s中动态的建设slave署理?
当完成这些任务之后思量的问题,这些任务都是在jenkins呆板去完成的,那么这个也必定是在pod中去运行的,因为我们的是将jenkins陈设在pod中的,也就是这当前的这个节点去完成的拉代替码,编译,构建镜像,宣布,那么大概会碰着一个问题,那么项目许多,天天做一连集成很高,十屡次甚至上百次,面临这样的一个需求量,当前的这个pod是很难支撑的,就比如适才的job,有十几小我私家去运行,来运行差异的处事,原来是可以几分钟完成的工作,最后导致10多分钟才执行完成,这样的话就很延长项目进度了,所以就需要利用jenkins的master-slave架构了,而master只认真调治分派,slave来完成这些job任务,而slave是由物理机可能虚拟机存在的,和master保持通信,只要有任务就下发到slave节点,这样就办理了单jenkins的机能问题了

也就是提前建设好几个jenkins-slave,在其他节点让它们待定着,当master有人点job构建了,这个jenkins会帮你把这个job详细做的事,转发到slave去干活,master也就启到一个率领的脚色,它自己就没什么压力了,只认真调治了,那么假如不消k8s的容器的这样架构,就比如在一台呆板上装了一个jenkins,然后找台主机做slave,在manage node,添加new node,然后这个就会通过master下发任务让slave去完成了。