
目前,MQ 的应用场景非常多,大家能倒背如流的是:系统解耦、异步通信和流量削峰。除此之外,还有延迟通知、最终一致性保证、顺序消息、流式处理等等。
那到底是先有消息模型,还是先有应用场景呢?答案肯定是:先有应用场景(也就是先有问题),再有消息模型,因为消息模型只是解决方案的抽象而已。
MQ 经过 30 多年的发展,能从最原始的队列模型发展到今天百花齐放的各种消息中间件(平台级的解决方案),我觉得万变不离其宗,还是得益于:消息模型的适配性很广。
我们试着重新理解下消息队列的模型。它其实解决的是:生产者和消费者的通信问题。那它对比 RPC 有什么联系和区别呢?

通过对比,能很明显地看出两点差异:
1、引入 MQ 后,由之前的一次 RPC 变成了现在的两次 RPC,而且生产者只跟队列耦合,它根本无需知道消费者的存在。
2、多了一个中间节点「队列」进行消息转储,相当于将同步变成了异步。
再返过来思考 MQ 的所有应用场景,就不难理解 MQ 为什么适用了?因为这些应用场景无外乎都利用了上面两个特性。
举一个实际例子,比如说电商业务中最常见的「订单支付」场景:在订单支付成功后,需要更新订单状态、更新用户积分、通知商家有新订单、更新推荐系统中的用户画像等等。
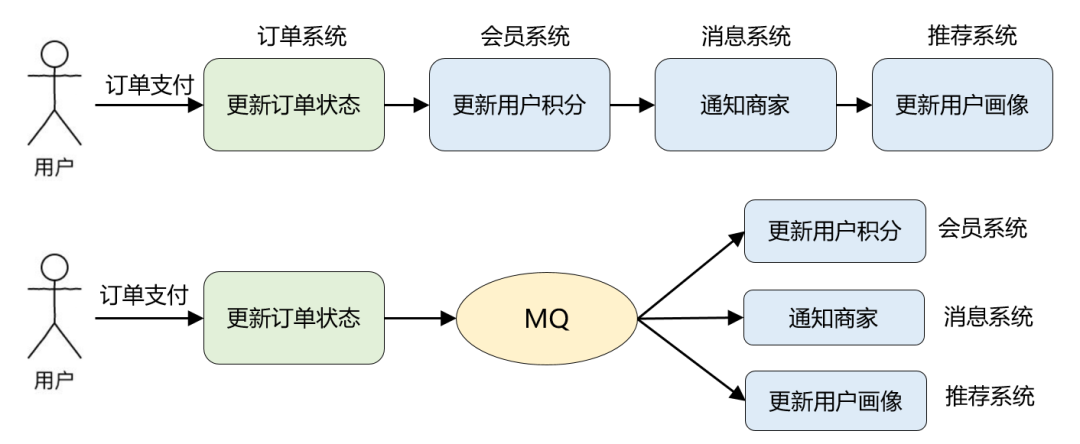
引入 MQ 后,订单支付现在只需要关注它最重要的流程:更新订单状态即可。其他不重要的事情全部交给 MQ 来通知。这便是 MQ 解决的最核心的问题:系统解耦。
改造前订单系统依赖 3 个外部系统,改造后仅仅依赖 MQ,而且后续业务再扩展(比如:营销系统打算针对支付用户奖励优惠券),也不涉及订单系统的修改,从而保证了核心流程的稳定性,降低了维护成本。
这个改造还带来了另外一个好处:因为 MQ 的引入,更新用户积分、通知商家、更新用户画像这些步骤全部变成了异步执行,能减少订单支付的整体耗时,提升订单系统的吞吐量。这便是 MQ 的另一个典型应用场景:异步通信。
除此以外,由于队列能转储消息,对于超出系统承载能力的场景,可以用 MQ 作为 “漏斗” 进行限流保护,即所谓的流量削峰。
我们还可以利用队列本身的顺序性,来满足消息必须按顺序投递的场景;利用队列 + 定时任务来实现消息的延时消费 ……
MQ 其他的应用场景基本类似,都能回归到消息模型的特性上,找到它适用的原因,这里就不一一分析了。
总之,就是建议大家多从复杂多变的实践场景再回归到理论层面进行思考和抽象,这样能吃得更透。
04 如何设计一个 MQ?
了解了上面这些理论知识以及应用场景后,下面我们再一起看下:到底如何设计一个 MQ?
4.1 MQ 的雏形我们还是先从简单版的 MQ 入手,如果只是实现一个很粗糙的 MQ,完全不考虑生产环境的要求,该如何设计呢?
文章开头说过,任何 MQ 无外乎:一发一存一消费,这是 MQ 最核心的功能需求。另外,从技术维度来看 MQ 的通信模型,可以理解成:两次 RPC + 消息转储。
有了这些理解,我相信只要有一定的编程基础,不用 1 个小时就能写出一个 MQ 雏形:
1、直接利用成熟的 RPC 框架(Dubbo 或者 Thrift),实现两个接口:发消息和读消息。
2、消息放在本地内存中即可,数据结构可以用 JDK 自带的 ArrayBlockingQueue 。
4.2 写一个适用于生产环境的 MQ当然,我们的目标绝不止于一个 MQ 雏形,而是希望实现一个可用于生产环境的消息中间件,那难度肯定就不是一个量级了,具体我们该如何下手呢?
1、先把握这个问题的关键点
假如我们还是只考虑最基础的功能:发消息、存消息、消费消息(支持发布-订阅模式)。
那在生产环境中,这些基础功能将面临哪些挑战呢?我们能很快想到下面这些:
1、高并发场景下,如何保证收发消息的性能?
2、如何保证消息服务的高可用和高可靠?
3、如何保证服务是可以水平任意扩展的?
4、如何保证消息存储也是水平可扩展的?
5、各种元数据(比如集群中的各个节点、主题、消费关系等)如何管理,需不需要考虑数据的一致性?
可见,高并发场景下的三高问题在你设计一个 MQ 时都会遇到,「如何满足高性能、高可靠等非功能性需求」才是这个问题的关键所在。
2、整体设计思路
先来看下整体架构,会涉及三类角色:

另外,将「一发一存一消费」这个核心流程进一步细化后,比较完整的数据流如下:
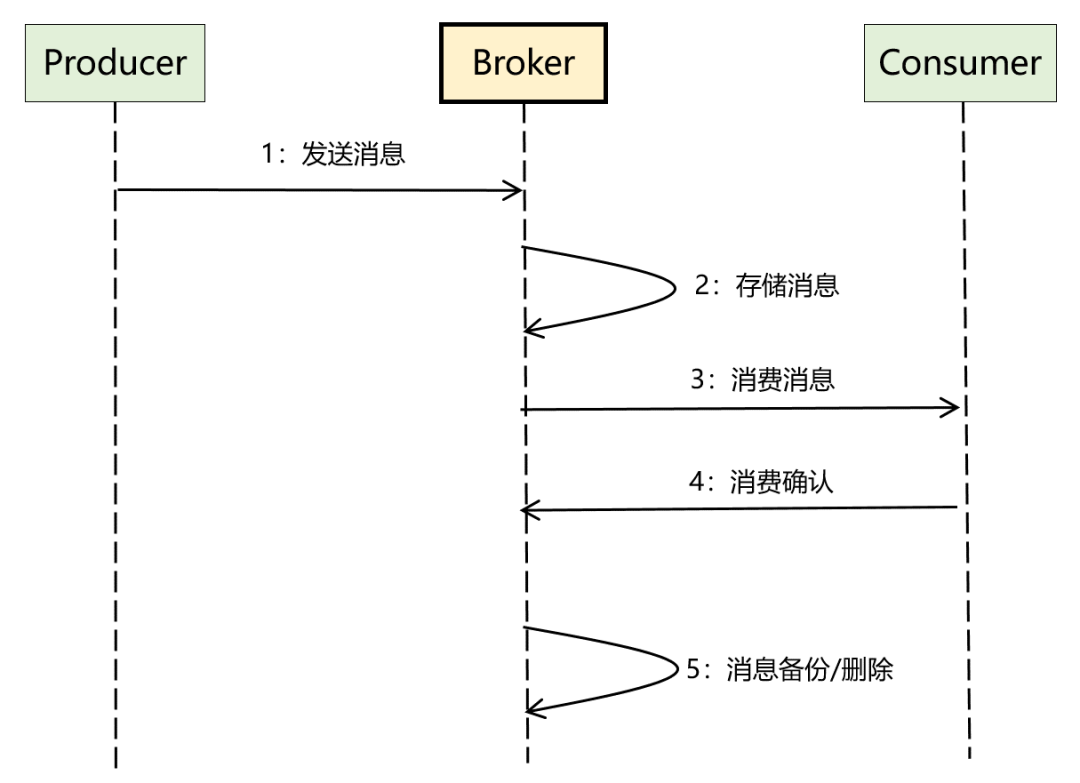
基于上面两个图,我们可以很快明确出 3 类角色的作用,分别如下: