
查看了一下java的nio直接内存,发现也就几十kb,然而直接内存还是慢慢往上涨。毫无头绪,然后开始了自己的从linux层面开始排查问题
5. 推荐的直接内存排查方法 5.1 pmap一般配合pmap使用,从内核中读取内存块,然后使用views 内存块来判断错误,我简单试了下,乱码,都是二进制的东西,看不出所以然来。
pmap -d 58 | sort -n -k2 pmap -x 58 | sort -n -k3 grep rw-p /proc/$1/maps | sed -n 's/^\([0-9a-f]*\)-\([0-9a-f]*\) .*$/\1 \2/p' | while read start stop; do gdb --batch --pid $1 -ex "dump memory $1-$start-$stop.dump 0x$start 0x$stop"; done这个时候真的懵了,不知道从何入手了,难道是linux操作系统方面的问题?
5.2 [gperftools](https://github.com/gperftools/gperftools)起初,在网上看到有人说是因为linux自带的glibc版本太低了,导致的内存溢出,考虑一下。初步觉得也可能是因为这个问题,所以开始慢慢排查。oracle官方有一个jemalloc用来替换linux自带的,谷歌那边也有一个tcmalloc,据说性能比glibc、jemalloc都强,开始换一下。
根据网上说的,在容器里装libunwind,然后再装perf-tools,然后各种捣鼓,到最后发现,执行不了,
看着工具高大上的,似乎能找出linux的调用栈,
6. 意外的结果毫无头绪的时候,回想到了linux的top命令以及日志情况,测试环境是由于太多执行端业务方都没有维护,导致调度系统一直会出错,一出错就会导致大量刷错误日志,平均一天一个容器大概就有3G的日志,cron一旦到准点,就会有大量的任务要同时执行,而且容器中是做了对io的限制,磁盘也限制为10G,导致大量的日志都堆积在buff/cache里面,最终直接内存一直在涨,这个时候,系统不会挂,但是先会一直显示内存使用率达到100%。
修复后的结果如下图所示:
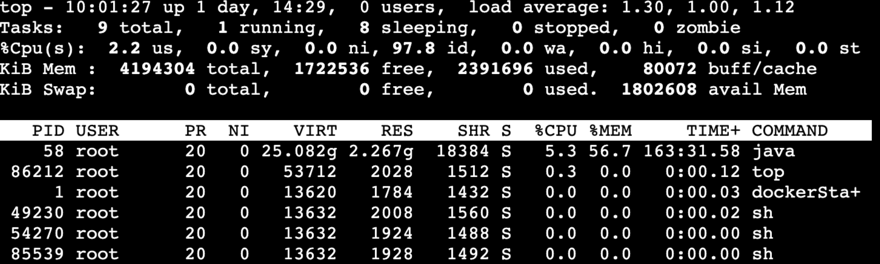

定时调度这个系统当时并没有考虑到公司的系统会用的这么多,设计的时候也仅仅是为了实现上千的量,没想到到最后变成了一天的调度都有几百万次。最初那批开发也就使用了大量的本地缓存map来临时存储数据,然后面向简历编程各种用netty自己实现了通信的方式,一堆坑都留给了后人。目前也算是解决掉了一个由于线程过多导致系统不可用的情况而已,但是由于存在大量的map,系统还是得偶尔重启一下比较好。
参考:
1.记一次线上内存泄漏问题的排查过程
2.Java堆外内存增长问题排查Case
3.Troubleshooting Native Memory Leaks in Java Applications