
可以看到,由于标签取值不同,我们会有四种不同的memSeries。如果一次性给定4个标签,应该是很容易从map中直接获取出对应的memSeries(尽管Prometheus并没有这么做)。但大部分我们的promql只是给定了部分标签,如何快速的查找符合标签的数据呢?
这就引入倒排索引。
先看一下,上面例子中的memSeries在内存中会有4种,同时内存中还夹杂着其它监控项的series
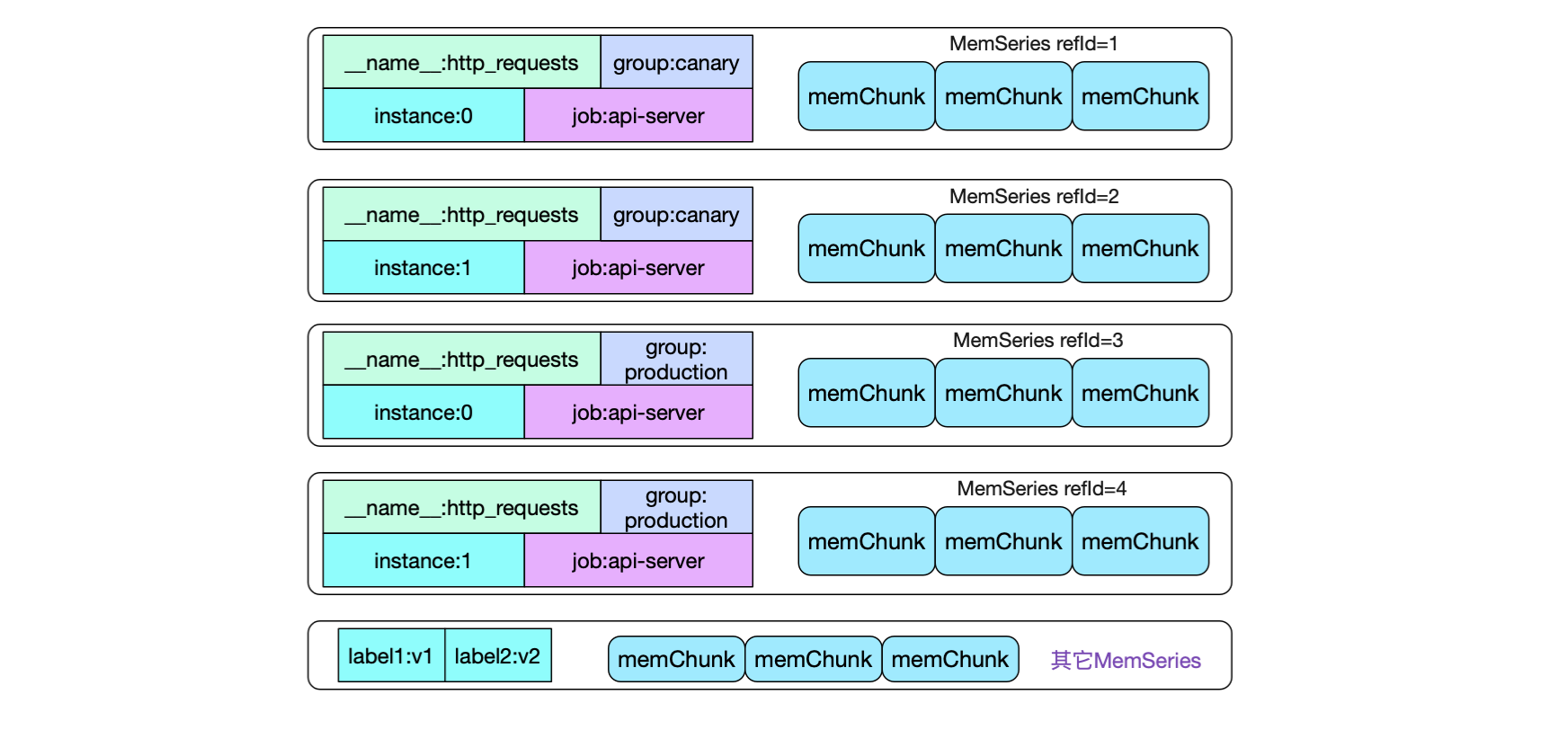
如果我们想知道job:api-server,group为production在一段时间内所有的http请求数量,那么必须获取标签携带
({__name__:http_requests}{job:api-server}{group:production})的所有监控数据。
如果没有倒排索引,那么我们必须遍历内存中所有的memSeries(数万乃至数十万),一一按照Labels去比对,这显然在性能上是不可接受的。而有了倒排索引,我们就可以通过求交集的手段迅速的获取需要哪些memSeries。
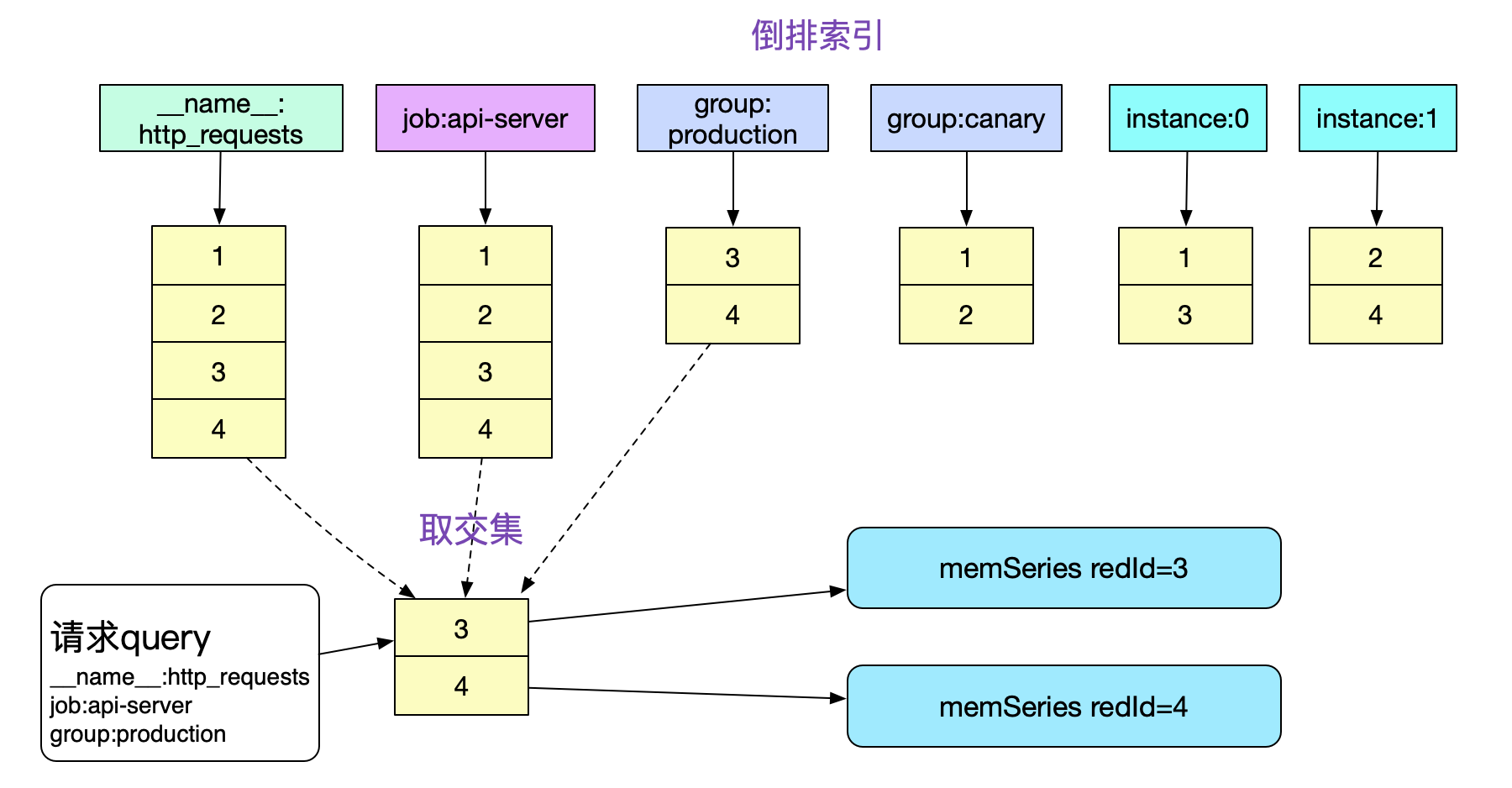
注意,这边倒排索引存储的refId必须是有序的。这样,我们就可以在O(n)复杂度下顺利的算出交集,另外,针对其它请求形式,还有并集/差集的操作,对应实现结构体为: type intersectPostings struct {...} // 交集 type mergedPostings struct {...} // 并集 type removedPostings struct {...} // 差集
倒排索引的插入组织即为Prometheus下面的代码
Add(labels,t,v) |->getOrCreateWithID |->memPostings.Add // Add a label set to the postings index. func (p *MemPostings) Add(id uint64, lset labels.Labels) { p.mtx.Lock() // 将新创建的memSeries refId都加到对应的Label倒排里去 for _, l := range lset { p.addFor(id, l) } p.addFor(id, allPostingsKey) // allPostingKey "","" every one都加进去 p.mtx.Unlock() } 正则支持事实上,给定特定的Label:Value还是无法满足我们的需求。我们还需要对标签正则化,例如取出所有ip为1.1.*前缀的http_requests监控数据。为了这种正则,Prometheus还维护了一个标签所有可能的取值。对应代码为:
Add(labels,t,v) |->getOrCreateWithID |->memPostings.Add func (h *Head) getOrCreateWithID(id, hash uint64, lset labels.Labels){ ... for _, l := range lset { valset, ok := h.values[l.Name] if !ok { valset = stringset{} h.values[l.Name] = valset } // 将可能取值塞入stringset中 valset.set(l.Value) // 符号表的维护 h.symbols[l.Name] = struct{}{} h.symbols[l.Value] = struct{}{} } ... }那么,在内存中,我们就有了如下的表
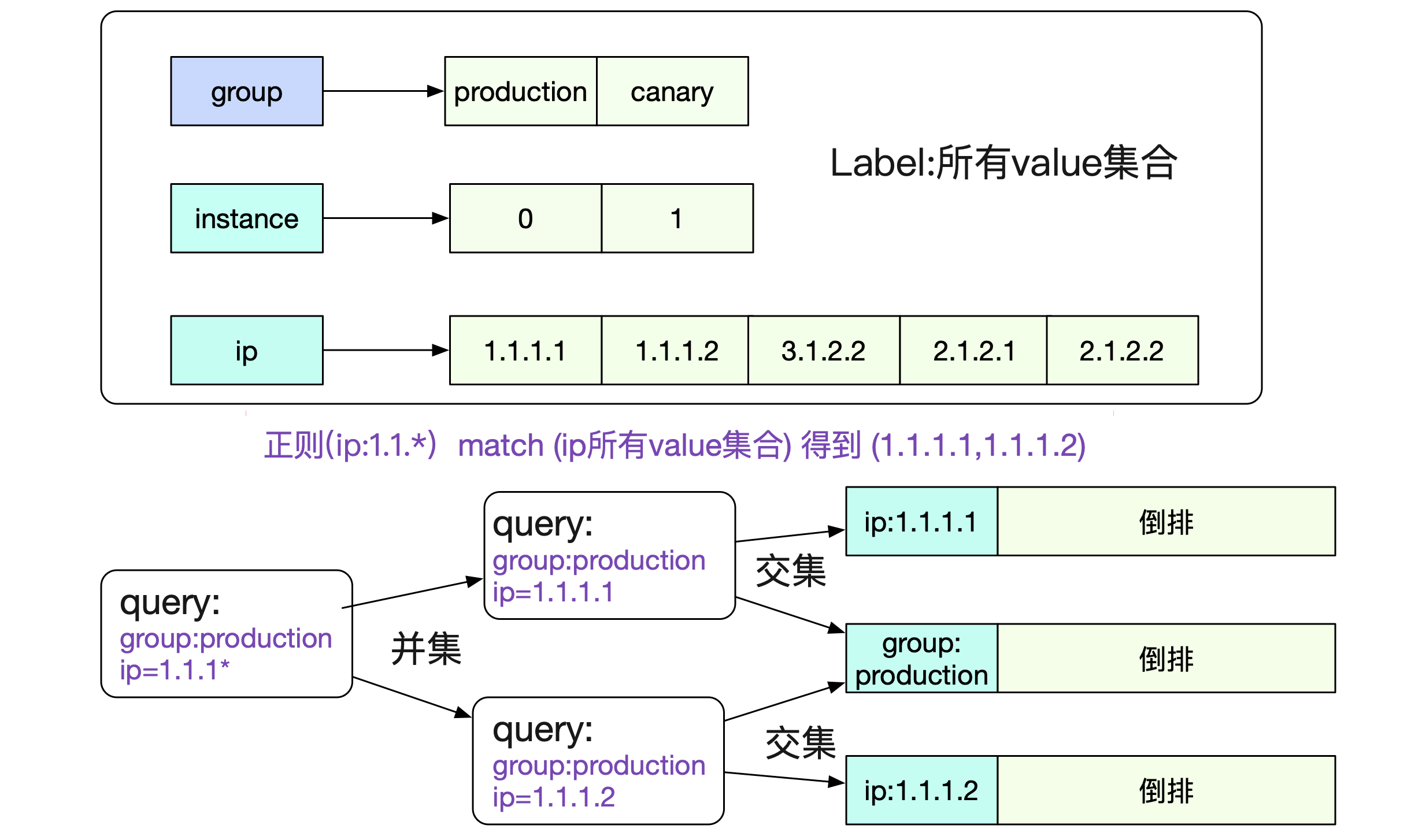
图中所示,有了label和对应所有value集合的表,一个正则请求就可以很容的分解为若干个非正则请求并最后求交/并/查集,即可得到最终的结果。 总结
Prometheus作为当今最流行的时序数据库,其中有非常多的值得我们借鉴的设计和机制。这一篇笔者主要描述了监控数据在内存中的存储结构。下一篇,将会阐述监控数据在磁盘中的存储结构,敬请期待!
欢迎大家关注我公众号,里面有各种干货,还有大礼包相送哦!
