
猪哥就以某东商品页为例子带大家学习爬虫的简单流程,为什么以某东下手而不是某宝?因为某东浏览商品页不需要登录,简单便于大家快速入门!
1.第一步:浏览器中找到你想爬取的商品
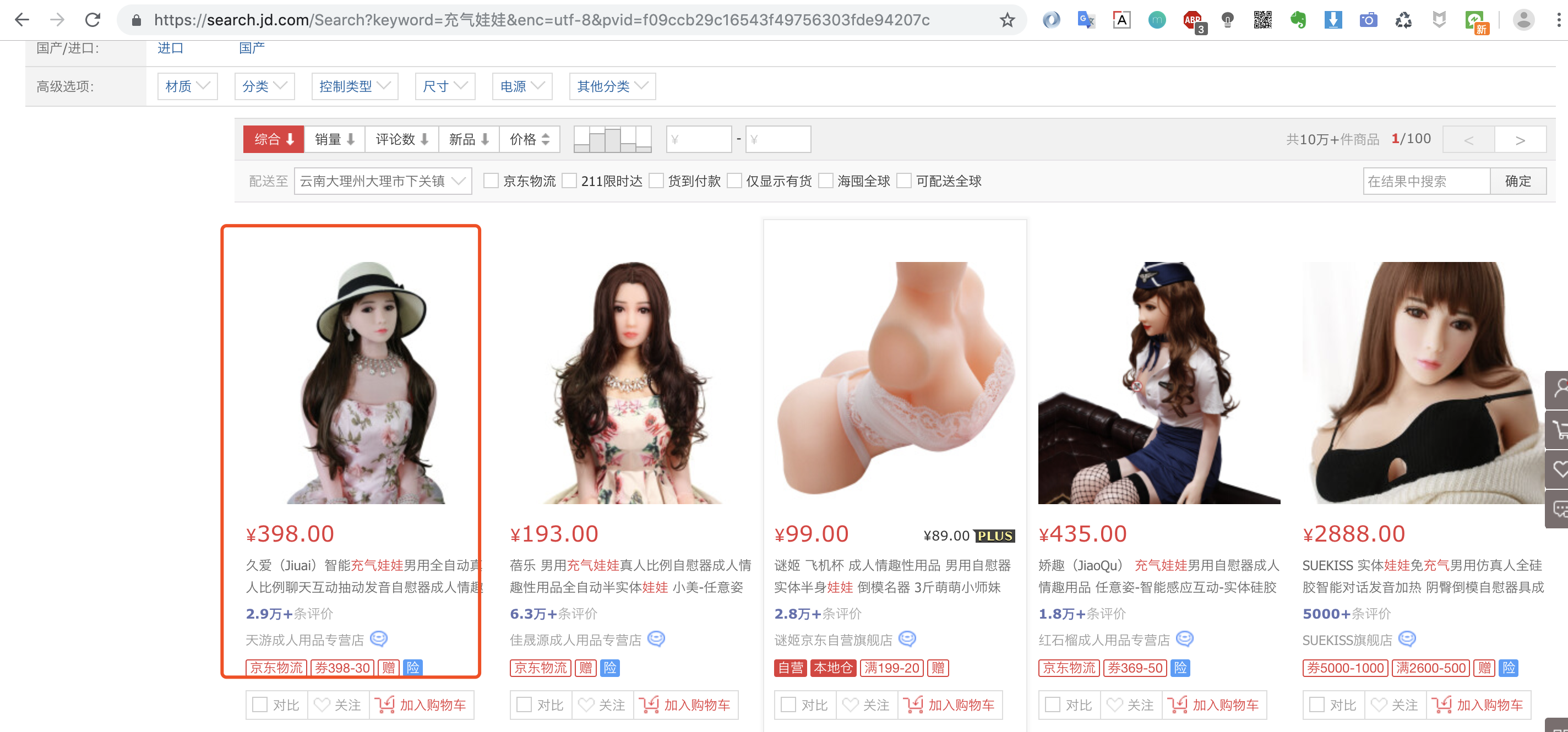

ps:猪哥并不是在开车哦,为什么选这款商品?因为后面会爬取这款商品的评价做数据分析,是不是很刺激! 2.第二步:浏览器检查数据来源
打开浏览器调试窗口是为了查看网络请求,看看数据是怎么加载的?是直接返回静态页面呢,还是js动态加载呢?

鼠标右键然后点检查或者直接F12即可打开调试窗口,这里猪哥推荐大家使用Chrome浏览器,为什么?因为好用,程序员都在用!具体的Chrome如何调试,大家自行网上看教程!
打开调试窗口之后,我们就可以重新请求数据,然后查看返回的数据,确定数据来源。
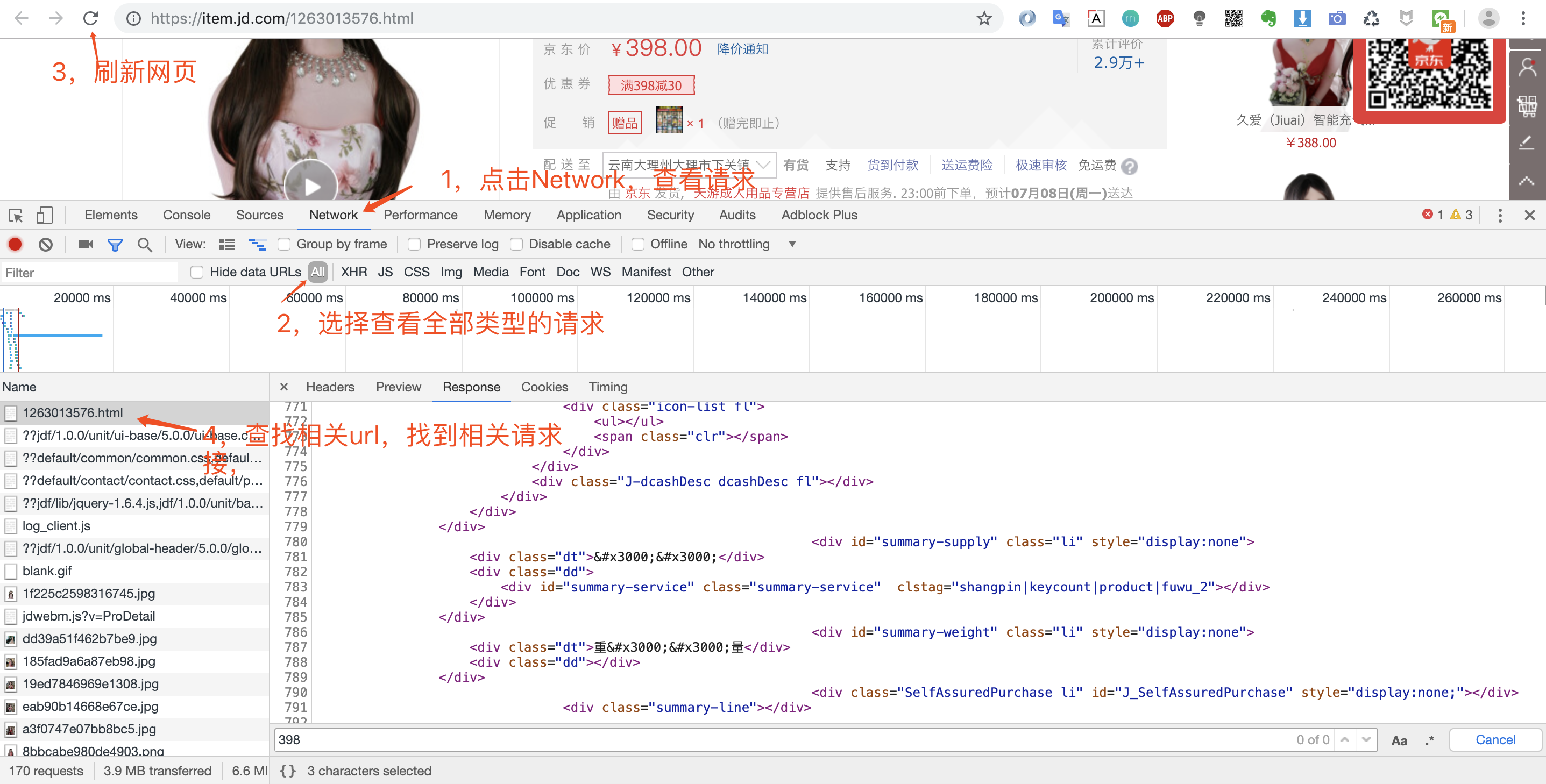
我们可以看到第一个请求链接:https://item.jd.com/1263013576.html 返回的数据便是我们要的网页数据。因为我们是爬取商品页,所以不存在分页之说。
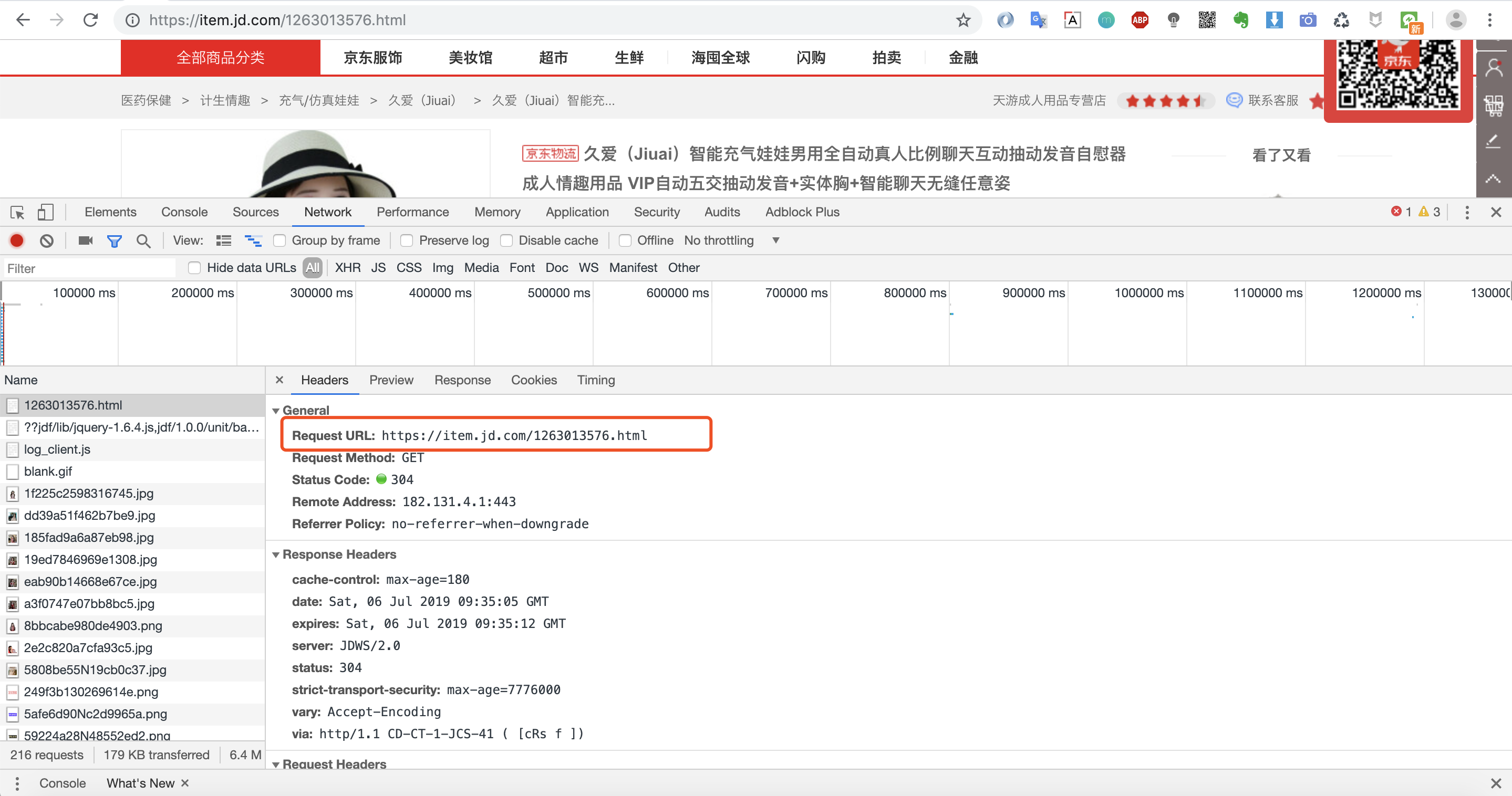
当然价格和一些优惠券等核心信息是通过另外的请求加载,这里我们暂时不讨论,先完成我们的第一个小例子!
4.第四步:代码模拟请求爬取数据获取url链接之后我们来开始写代码吧
import requests def spider_jd(): """爬取京东商品页""" url = 'http://item.jd.com/1263013576.html' try: r = requests.get(url) # 有时候请求错误也会有返回数据 # raise_for_status会判断返回状态码,如果4XX或5XX则会抛出异常 r.raise_for_status() print(r.text[:500]) except: print('爬取失败') if __name__ == '__main__': spider_jd()检查返回结果
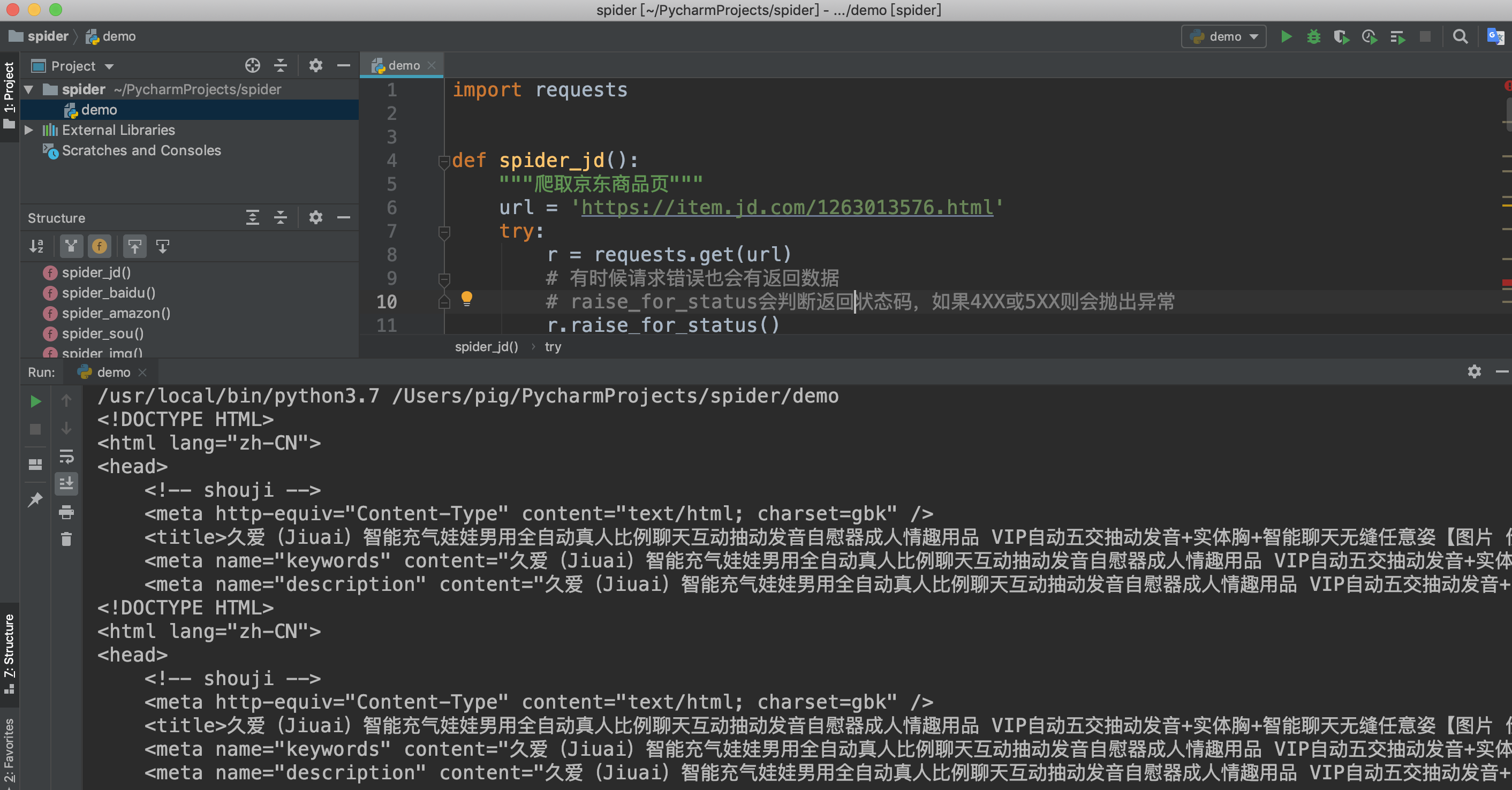
至此我们就完成了某东商品页的爬取,虽然案例简单,代码很少,但是爬虫的流程基本差不多,希望想学爬虫的同学自己动动手实践一把,选择自己喜欢的商品抓取一下,只有自己动手才能真的学到知识! 六、requests库介绍
上面我们使用了requests的get方法,我们可以查看源码发现还有其他几个方法:post、put、patch、delete、options、head,他们就是对应HTTP的请求方法。
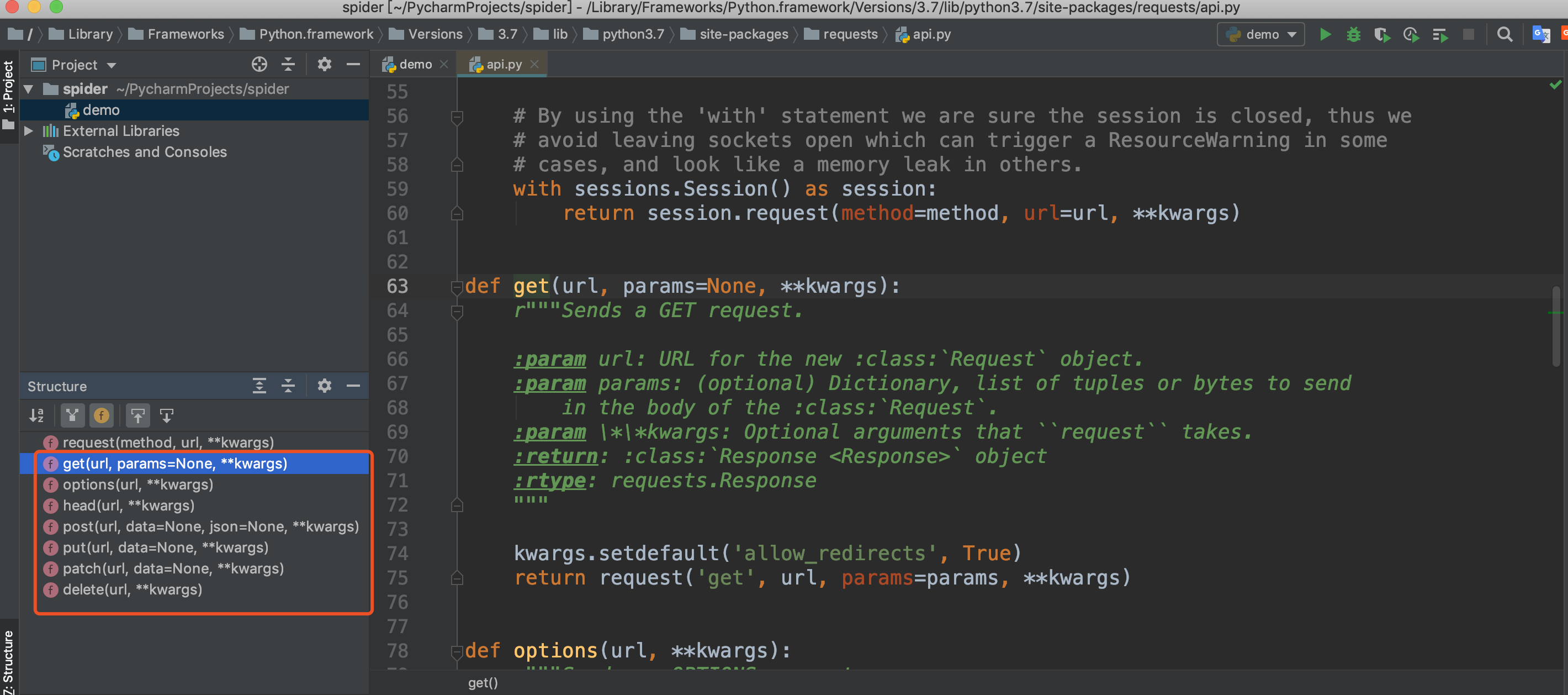
这里简单给大家列一下,后面会用大量的案例来用而后学,毕竟枯燥的讲解没人愿意看。 requests.post('http://httpbin.org/post', data = {'key':'value'}) requests.patch('http://httpbin.org/post', data = {'key':'value'}) requests.put('http://httpbin.org/put', data = {'key':'value'}) requests.delete('http://httpbin.org/delete') requests.head('http://httpbin.org/get') requests.options('http://httpbin.org/get')
注:httpbin.org是一个测试http请求的网站,能正常回应请求
对于HTTP的几种请求方法,没做过RestFul API的同学并不是很清楚每个请求方式表达的含义,这里给大家列一下:
GET:获取用户列表:
GET:获取单个用户:{uid}
POST:创建单个用户:{uid}
PUT:完全替换用户:{uid}
PATCH:局部更新用户:{uid}
DELETE:删除单个用户:{uid}
想了解requests更多使用方法请参考:
后面猪哥也会用大量案例来一点一点学习requests库的一些使用技巧。
今天为大家简单介绍了一下这个非常重要的库:requests,requests可以胜任很多简单的爬虫需求,它强大的功能以及优美的api得到一致的认同。