正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串。通过特殊字符+普通字符来进行模式描述,从而达到文本匹配目的工具。类似于生活中常见的寻人启示,通过描述一个人的特征来进行“搜索匹配”
如今正则已经被我们广泛应用,目前被集成到了各种文本编辑器/文本处理工具当中
应用场景**验证: **表单提交时,进行用户名密码验证。**查找: **从大量信息中快速提取指定内容。在一批url中,查找指定url替换: 将指定格式的文本,进行正则匹配查找,找到之后进行特定替换,(vim文本替换等)
在很多技术领域(比如,自然语言处理,数据存储等),正则表达式可以很方便的提取出我们想要的信息,所以这部分必不可少构成基本要素字符类数量限定符位置限定符特殊符号
1. 字符类:
字符 说明 举例. 匹配任意的一个字符 abc. 可以匹配abcd、abc0等
[] 匹配 [] 内的任意一个字符 [012]a可以匹配0a、1a、2a
- 在括号内表示字符范围 如[0-9]可以匹配任何一个数字
^ 放在[]内前面表示匹配除括号中字符外的任意一个字符 [^ab]c可以匹配1c、dc,但是不能匹配ac、bc
[[:xxx:]] grep工具预定义的一些命名字符类 [[:digit:]]可以匹配一个数字,[[:alpha:]]匹配一个字符,[[:lower:]]匹配任何一个小写字母等
应用:
grep使用--color选项将匹配的字符串以红色标注出来Linux下可以用echo $?来打印上一条命令执行的退出码,为0表示执行成功,1表示失败。
实验如下:

注意:使用 . 默认为贪心匹配,和后面的正则匹配方式相关,后面再述。

2. 数量限定符:
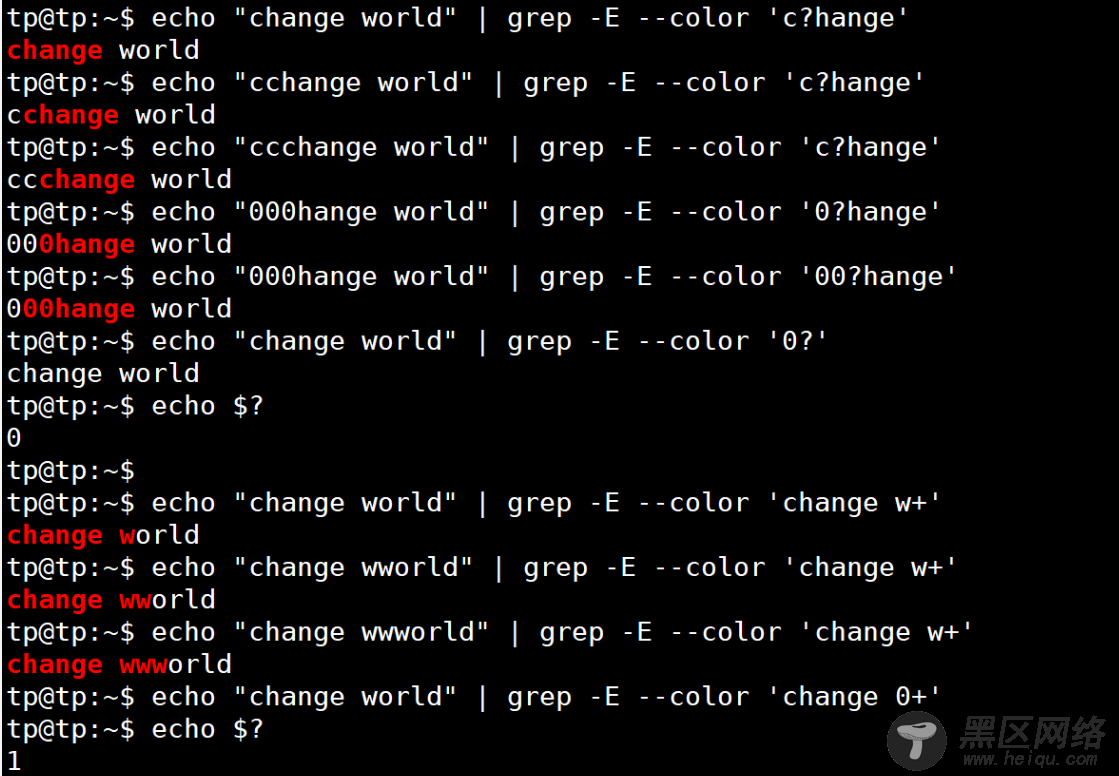
字符 说明 举例? 匹配紧跟它前面的单元(前面的一个数字或字符) 0或1次 如匹配小数,用0\.?[0-9]匹配0.1 、0.2、0.3等;由于.在正则里面是特殊符号所以需要用\进行转义操作(后面再说)
+ 匹配紧跟它前面的单元 1或多次 [a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+\.com匹配一个邮箱地址
* 匹配紧跟它前面的单元0或多次 [0-9][0-9]*匹配至少一位数字,等价于[0-9]+
{N} 精确匹配紧跟它前面的单元N次 [0-9]{3}匹配000到999之间的数字
{N,} 匹配紧跟它前面的单元至少N次 [0-9]{3,}匹配三位及其以上的数字
{,M} 匹配紧跟它前面的单元最多M次 [0-9]{,1}等价于[0-9]?
{N,M} 匹配紧跟它前面的单元N~M次 近似匹配IP地址:[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}
应用:

3. 位置限定符:
字符 说明 举例^ 匹配行首位置,从行首开始匹配 ^world只匹配一行开头的world
$ 匹配行末位置,从行末尾开始匹配 ;$匹配一行末尾的;号,^$匹配空行
< 匹配单词开始位置 < th匹配this,不匹配teach、ethernet
\> 匹配单词末尾位置 p\>匹配sleep、leap等,不匹配parent、sleepy
\b 匹配单词的开始位置、末尾位置 如 \borld匹配world、aorld,\borld\b只匹配orld
\B 匹配非单词的开头、末尾位置 如 \Bat\B匹配battery,不匹配attend、hat等以字符串"at"开头、结尾的单词
注意:其中 \b 用来限定是目标串中是否有以指定字符串开头的单词,我们称之为词界。 \B 称之为非词界
应用:
