
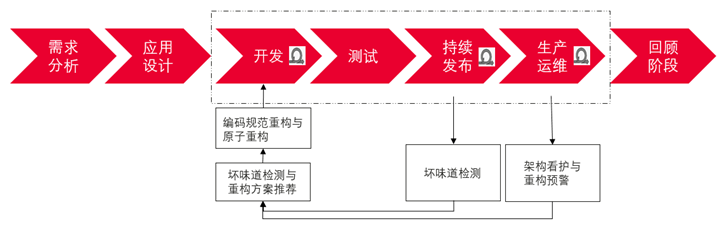
对于持续交付过程中的代码开发与发布环节,如上图虚线框所示,几乎每一步都与代码质量的看护或代码重构相关。
开发环节可大致分为两种类型:用于添加新功能的“增量式开发”以及维护老版本的“存量式维护”。对于“增量式开发”而言,需要重构服务的编码规范重构和原子重构能力在开发过程中帮助开发人员提升代码质量与开发效率;对于“存量式整改”而言,则需要重构服务具备架构、代码坏味道的检查、重构机会点挖掘以及重构方案的推荐能力,并将相应的重构方案拆解为彼此独立且正交的原子重构能力,最终作为一个原子重构序列推荐给开发人员,在与人机交互中一步步完成重构应用。
在持续发布环节,MR门禁中的代码静态检测需要触发对坏味道代码的识别,作为一种增量式检测,主要识别由新增代码引入的代码及架构坏味道, 并自动生成一次重构任务,引导开发人员进行一次重构,避免代码中技术债堆积。
在生产运维环节,需要做定期的架构看护,将相应度量结果通过架构可视化图形界面展示出来,当架构某个模块腐化到一个阈值时自动报警,提示版本负责人做相应重构。
三、如何辅助开发人员实现代码分层重构 1. 都有哪些层级的重构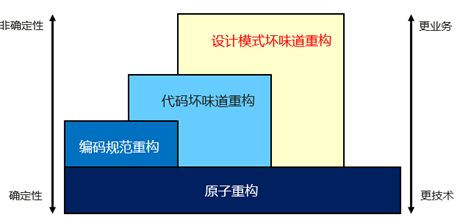
个人认为重构大致可以分为4个层级,这些层级之间的关系可以从上图看出,并非是自底向上依次包含的关系,它们之间会有些重叠也有些不同。单纯从重构本身来讲,越上层级的重构操作非确定性越强,更偏业务性,而越下层级的重构操作确定性越强,更偏技术性。从智能重构服务的角度来讲,越上层越偏检测能力,越下层越偏纯重构能力。下面我们由下至上依次来看看不同层级重构操作的特点与异同。
原子重构能力:上文中也有提到原子重构,原子重构到底有哪些呢?顾名思义,即不可再分的重构操作,例如重命名、移动、删除等重构操作,这些重构操作是完全确定性的,例如我想要抽取一段代码形成一个新方法,是否可抽,可以抽成什么样都是完全确定的。这些重构操作因为其不可再分性位于重构最底层。
编码规范重构:有些同学可能会对这个层级的重构比较陌生,其实它就是基于规范和规则的重构,通常包含了我们所说的微重构,例如对违反了命名风格的标识符进行重命名重构,亦或是对无用代码进行删除的安全删除重构等等,并且这层的重构操作完全可以通过调用下层的1个原子重构来实现。正因为这些重构操作基于规则,其重构结果也是相对确定的。
代码坏味道重构:代码坏味道也包括了架构坏味道,例如Feature Envy、God Class等类型,这些层级重构的目的是为了消除相应的代码坏味道,所以相对来说更复杂,一次重构的完成往往要调用下层多个原子重构操作,例如对God Class进行重构,需要调用至少一次Extract Class原子重构。同时这层重构的非确定性也更高,对一种代码坏味道的重构消除往往可以通过多种手段。
设计模式坏味道重构:这层重构应该属于金字塔顶端的重构,因为它涉及范围太广,更偏向于对业务的理解与预测,从具象到抽象,显得有些虚无缥缈。设计模式有7中坏味道和11中原则,目前无论学术界还是工业界对于这类问题检测、重构相关的研究都还不多。
2. 智能重构服务在不同层级下的应用结合Devops下的重构服务需求与上图中的四层重构,我们基本可以看出智能重构服务不同层级的重构能力主要运用在开发工作流中的哪个阶段。对于原子重构来说,因为其确定性以及业务无关性,最适合作为插件集成在IDE上,由开发者做增量开发时调用;对于编码规范重构来说,适合同原子重构一起集成进IDE插件,在开发过程中自动且快速的识别到违反特定规则的代码,并辅助开发者重构;对于代码坏味道重构来说,适合在持续发布环节的门禁阶段拦截问题并引导开发者回到IDE进行代码智能重构;对于设计模式坏味道重构来说,因为其涉及业务理解与预测,更适合放进生产运维环节,结合版本演进与迭代历史,给出架构腐化的预测以及相应重构方案的推荐。
3. 搭积木式的重构应用