
空间利用率低:对于平衡二叉树来说,每个节点值保存一个关键字,一个数据区,两个子节点的指针。这样导致了,一次辛辛苦苦的IO操作就只加载这么点数据,实在是有点杀鸡用牛刀了。
查询效果不稳定:如果在一个高度很深的平衡二叉树中,若是查询的数据正好是根节点,那么就会很快的查到,若是查询的数据正好是叶子节点,那么会进行多次磁盘IO后才能返回,响应时间有可能和根节点的不在一个数量级上。
虽然说二叉树解决的平衡的问题,但是也带来了新的问题,那就是由于它本身树的深度的,会造成一系列的效率问题。
那么为了解决平衡二叉树的这类问题,平衡多叉树(Balance Tree)就成为了更好的选择。
平衡多叉树(Balance Tree--B-Tree)B-Tree的意思是平衡多叉树,一般B-Tree中的一个节点有多少个子节点,我们就称为多少阶的B-Tree。通常用m表示阶数,当m为2的时候,就是平衡二叉树。
一棵B-Tree的每个节点上最多能有m-1个关键字,最少要存放Math.ceil(m/2)-1个关键字,所有的叶子节点都在同一层。如下图就是一个4阶的B-Tree。
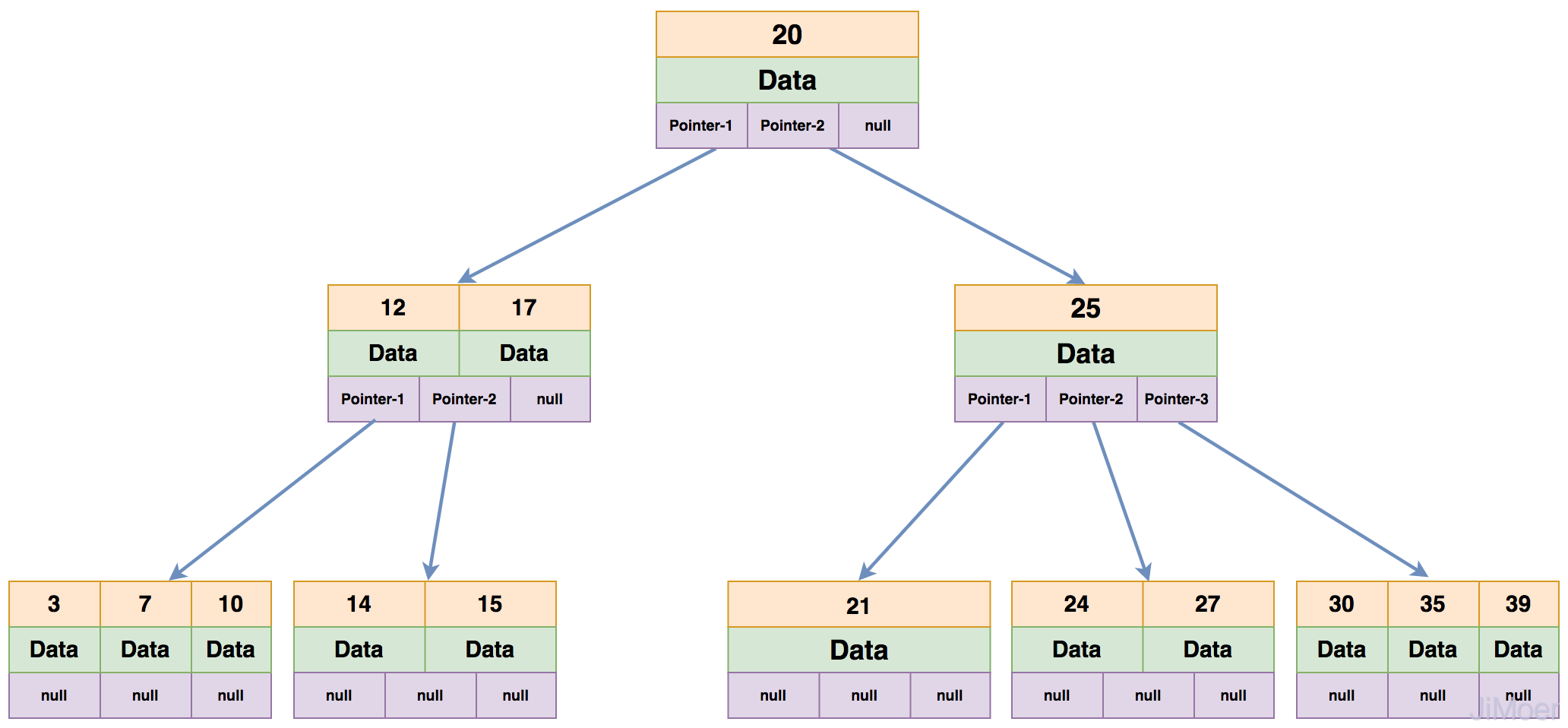
那么我们看一下B-Tree是如何进行查找数据的:
若是查询id=7的数据,先将关键字20的节点加载进内存,判断出7比20小;
那么加载第一个子节点,若查询的数据等于12或17则直接返回,不等于就继续向下找,发现7小于12;
那么继续加载第一个子节点中去,找到7之后,直接将7下面的data数据返回。
这样整个操作其实进行了3次IO操作,但实际上一般的B-Tree每层都是有很多分支(通常都大于100)。
MySQL为了能更好的利用磁盘的IO能力,将操作页的大小设置为了16K,即每个节点的大小为16K。如果每个节点中的关键字都是int类型的,那么就是4个字节,若数据区的大小为8个字节,节点指针再占4个字节,那么B-Tree的每个节点中可以保存的关键字个数为:(16*1000) / (4+8+4)=1000,每个节点最多可存储1000个关键字,每一个节点最多可以有1001个分支节点。
这样在查询索引数据的时候,一次磁盘IO操作可以将1000个关键字,读取到内存中进行计算,B-Tree的一次磁盘IO的操作,顶上平衡二叉数据的N次磁盘IO操作了。
要注意的是:B-Tree为了保证数据的平衡,会做一系列的操作,这个保持平衡的过程比较耗时间,所以在创建索引的时候,要选择合适的字段,并且不要过多的创建索引,创建索引过多的话,在更新数据的时候,更新索引的过程也比较耗时。
还有就是不要选择低区分度字段值作为索引,例如性别字段,总共就两个值,那么就有可能会造成B-Tree的深度过大,索引效率降低。
B+TreeB-Tree已经很好的解决平衡二叉树的问题了,并且也能保证查询效率了,那么为什么会有B+Tree呢?
我们先来B+Tree是什么样子的。
B+Tree是B-Tree的变种,B+Tree的每个节点关键字和m阶的公式关系和B-Tree的不一样了。
首先每个节点的子节点数量和每个节点可存储的关键字比例是1:1,其次就是查询数据的时候采用的是左闭合区间进行查询,还有就是分支节点中没有数据了只保存关键字和子节点指向,数据都存储在叶子节点。
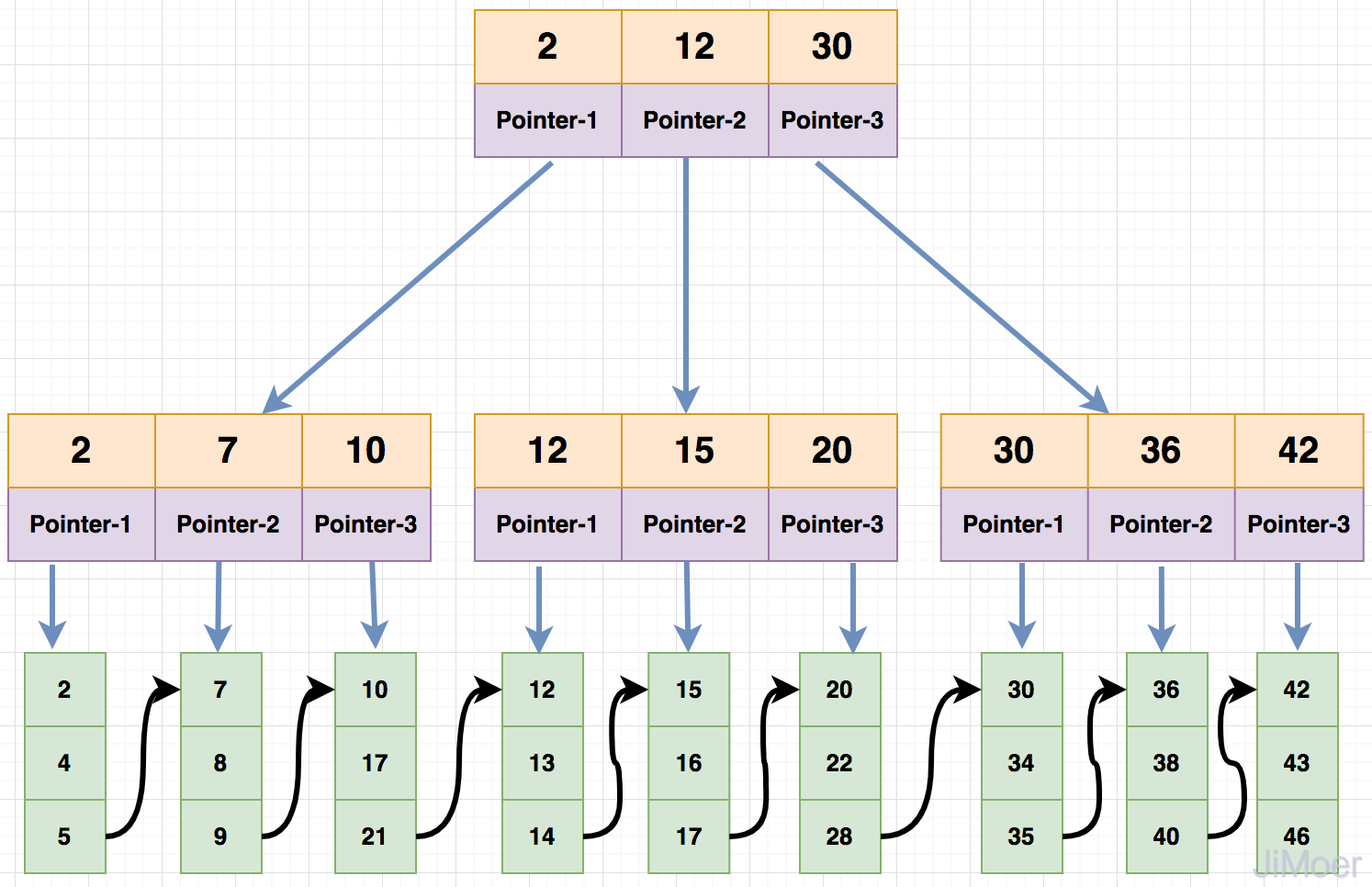
那么来看一下在B+Tree中是如何进行数据查询的。
例如:
现在要查询id=2的数据,那么会先将根节点取出,加载到内存中,发现id=2存在于根节点,因为是左闭合区间存储数据,所以id<=2的都在根节点的第一个子节点上;
那么取出第一个子节点,加载到内存中,发现当前节点存在id=2的关键字,并且已经到了叶子节点了,那么直接取出叶子节点中的数据返回。
现在来看一下B-Tree和B+Tree的区别B+Tree的查询采用的左闭合区间,这样能更好的支持了自增索引的查询效果,所以一般在创建主键的时候通常都是自增的。这一点和B-Tree是不一样的。
B+Tree中的根节点和分支节点上是不保存数据的,关键字相关的数据只保存在叶子节点上,这样保证了查询效果的稳定,任何查询都要走到叶子节点才能获取数据。而B-Tree在分支节点中保存了数据,若是命中关键字则直接返回数据。