
使用上述代码,我们可以确保,即使我们使用CTRL+C命令杀死了一个正在处理消息的woker,也不会丢失什么。这个worker挂掉后不久,所有未确认的消息将会被重新传送。
消息确认必须在同一个传输消息的channel中发送。尝试着在不同的channel中进行消息确认将会引发channel-level protocol exception。
我们已经学习了如何在消费者挂掉的情况下,任务不会丢失。但是,当RabbitMQ server停止时,我们的任务仍然会丢失。
当RabbitMQ停止或崩溃时,它将会忘记所有的队列和消息,除非你告诉它不这么做。在这种情况下,需要做两个事情确保消息不会丢失:我们需要将队列和消息都设置为持久化。
首先,我们需要确保RabbitMQ不会丢失队列。为了实现这个,我们需要将队列声明为持久化:
尽管这个命令是正确的,但他仍会不会起作用。这是因为,我们已经创建了一个叫为hello的非持久化队列。RabbitMQ不允许你重新定义一个已经存在的队列而参数不一样,所有这样做的程序只会引发错误。但是有一个快速的应变办法——我们可以创建一个不同名称的队列,比如task_queue:
channel.queue_declare(queue='task_queue', durable=True)queue_declare需要同时应用于生产者和消费者。
在这点上我们可以确保task_queue队列不会丢失消息即使RabbitMQ重启。现在,我们需要声明消息为持久化——将delivery_mode这个参数设置为2。
你也许注意到了,刚才的消息分发机制并不会严格地按照我们所希望的方式进行。举这样一个例子,设想有两个worker,而所有的奇数消息都很重而偶数消息都是轻量级的,这样其中一个worker就会一直很忙而另一个worker几乎不做什么工作。然而,RabbitMQ对此一无所知,它仍然会平均分配消息。
这种情况的发生是因为RabbitMQ仅仅是当消息进入队列的时候就会分发这个消息。它并不会注意消费者所接收的未确认的消息数量。它盲目地将第n个消息发送至第n个消费者。
为了克服这种情况,我们可以在basic.qos方法中设置prefetch_count=1。这就告诉RabbitMQ一次不要将多于一个的消息发送给一个worker。换句话说,不要分发一个新的消息给worker除非这个worker已经处理好之前的消息并且进行了消息确认。也就说,RabbitMQ将会将这个消息分发给下一个不是很忙的worker。
channel.basic_qos(prefetch_count=1) 实战1 为了对上面的例子有一个好的理解,我们需要写代码进行实际操练一下。
生产者new_task.py的代码如下:
消费者worker.py的完整代码如下:
# -*- coding: utf-8 -*- import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) print(' [*] Waiting for messages. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] Received %r" % body) time.sleep(body.count(b'.')) print(" [x] Done") ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(queue='task_queue', on_message_callback=callback) channel.start_consuming() 开启三个终端,消息的发送和接收情况如下:

如果我们停掉其中一个worker,那么消息的接收情况如下:
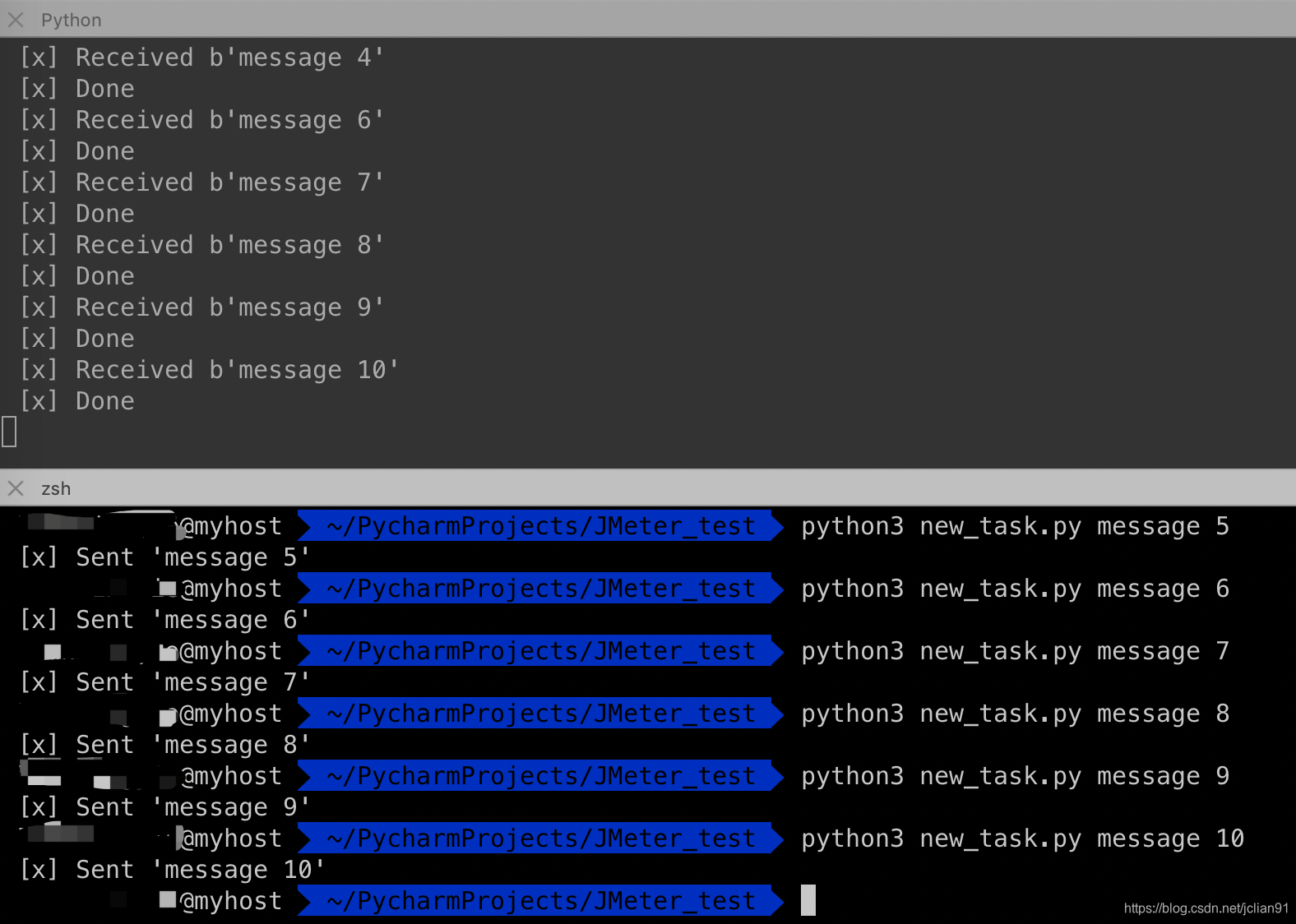
可以看到,现在所有发送的消息都会被这个仍在工作的worker接收到。 实战2
接下来,我们将会使用RabbitMQ的这种工作队列的方式往MySQL数据库中的表插入数据。
数据库为orm_test,表格为exam_user,表结构如下: