
但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
注:GPU中有很多的运算器ALU和很少的缓存cache,缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为线程thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram。
GPU的工作大部分都计算量大,但没什么技术含量,而且要重复很多很多次。
借用知乎上某大神的说法,就像你有个工作需要计算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已;而CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个?
GPU就是用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。
但有一点需要强调,虽然GPU是为了图像处理而生的,但是我们通过前面的介绍可以发现,它在结构上并没有专门为图像服务的部件,只是对CPU的结构进行了优化与调整,所以现在GPU不仅可以在图像处理领域大显身手,它还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce等),金融分析等需要大规模并行计算的领域。
所以GPU也可以认为是一种较通用的芯片。
3.TPU按照上文所述,CPU和GPU都是较为通用的芯片,但是有句老话说得好:万能工具的效率永远比不上专用工具。
随着人们的计算需求越来越专业化,人们希望有芯片可以更加符合自己的专业需求,这时,便产生了ASIC(专用集成电路)的概念。
ASIC是指依产品需求不同而定制化的特殊规格集成电路,由特定使用者要求和特定电子系统的需要而设计、制造。当然这概念不用记,简单来说就是定制化芯片。
因为ASIC很“专一”,只做一件事,所以它就会比CPU、GPU等能做很多件事的芯片在某件事上做的更好,实现更高的处理速度和更低的能耗。但相应的,ASIC的生产成本也非常高。
而TPU(Tensor Processing Unit, 张量处理器)就是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,其实也是一款ASIC。
原来很多的机器学习以及图像处理算法大部分都跑在GPU与FPGA(半定制化芯片)上面,但这两种芯片都还是一种通用性芯片,所以在效能与功耗上还是不能更紧密的适配机器学习算法,而且Google一直坚信伟大的软件将在伟大的硬件的帮助下更加大放异彩,所以Google便想,我们可不可以做出一款专用机机器学习算法的专用芯片,TPU便诞生了。
据称,TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。初代的TPU只能做推理,要依靠Google云来实时收集数据并产生结果,而训练过程还需要额外的资源;而第二代TPU既可以用于训练神经网络,又可以用于推理。
看到这里你可能会问了,为什么TPU会在性能上这么牛逼呢?
嗯,谷歌写了好几篇论文和博文来说明这一原因,所以仅在这里抛砖引玉一下。
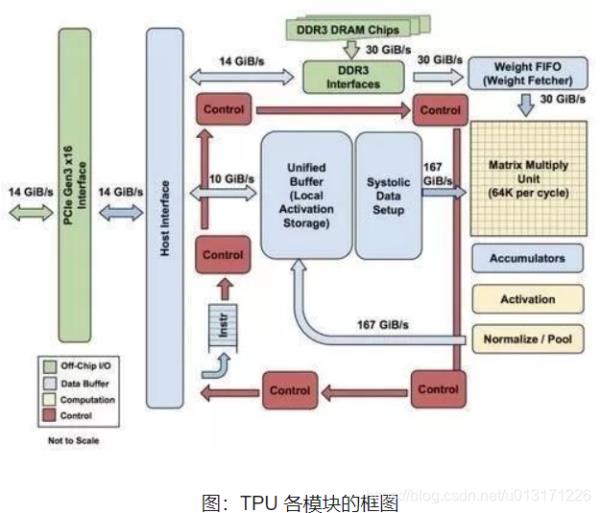
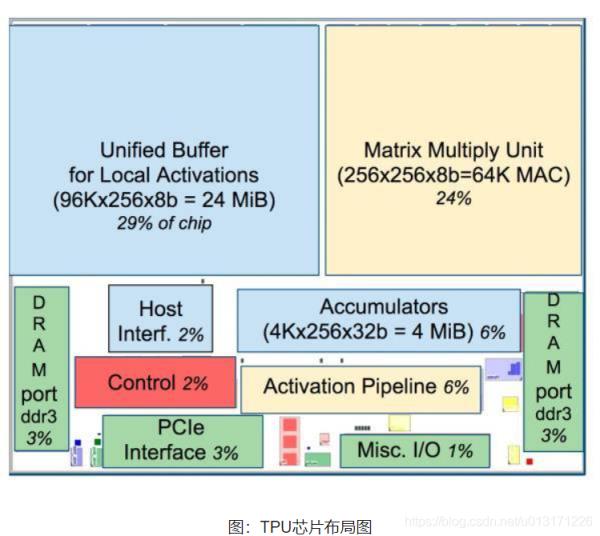
如上图所示,TPU在芯片上使用了高达24MB的局部内存,6MB的累加器内存以及用于与主控处理器进行对接的内存,总共占芯片面积的37%(图中蓝色部分)。
这表示谷歌充分意识到了片外内存访问是GPU能效比低的罪魁祸首,因此不惜成本的在芯片上放了巨大的内存。相比之下,英伟达同时期的K80只有8MB的片上内存,因此需要不断地去访问片外DRAM。
另外,TPU的高性能还来源于对于低运算精度的容忍。研究结果表明,低精度运算带来的算法准确率损失很小,但是在硬件实现上却可以带来巨大的便利,包括功耗更低、速度更快、占芯片面积更小的运算单元、更小的内存带宽需求等...TPU采用了8比特的低精度运算。
其它更多的信息可以去翻翻谷歌的论文。
到目前为止,TPU其实已经干了很多事情了,例如机器学习人工智能系统RankBrain,它是用来帮助Google处理搜索结果并为用户提供更加相关搜索结果的;还有街景Street View,用来提高地图与导航的准确性的;当然还有下围棋的计算机程序AlphaGo!
4.NPU讲到这里,相信大家对这些所谓的“XPU”的套路已经有了一定了解,我们接着来。
所谓NPU(Neural network Processing Unit), 即神经网络处理器。顾名思义,这家伙是想用电路模拟人类的神经元和突触结构啊!