
从上面可以看出,如果我们要查询某条记录的话,数据库会从最小记录开始,一条条查找所有记录。如果中途找到了,则直接返回该记录。如果一直找到最大记录,还没有找到想要的记录,则返回空。
咋一看,没有问题。
但如果仔细想想。
效率会不会有点低?
这不是要对整页用户数据进行扫描吗?
有没有更高效的方法?
这就需要使用页目录了。
说白了,就是把一页用户记录分为若干组,每一组的最大记录都保存到一个地方,这个地方就是页目录。每一组的最大记录叫做槽。
由此可见,页目录是有多个槽组成的。所下图所示:
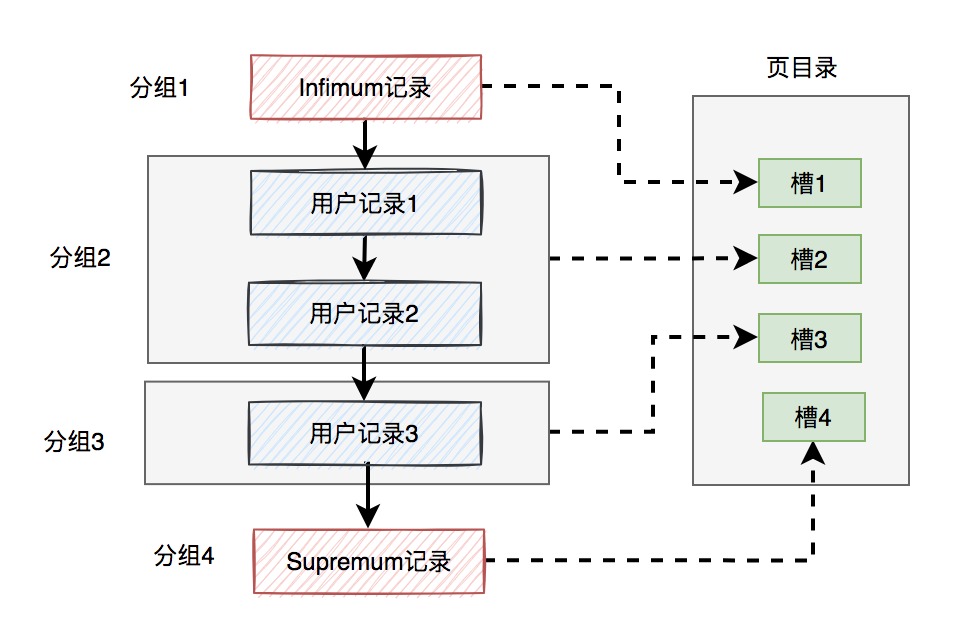
假设一页的数据分为4组,这样在页目录中,就对应了4个槽,每个槽中都保存了该组数据的最大值。
这样就能通过二分查找,比较槽中的记录跟需要找到的记录的大小。如果用户需要查找的记录,小于当前槽中的记录,则向上查找上一个槽。如果用户需要查找的记录,大于当前槽中的记录,则向下查找下一个槽。
如此一来,就能通过二分查找,快速的定位需要查找的记录了。
so easy
6.文件头部和尾部 6.1 文件头部通过前面介绍的行记录中下一条记录的位置和页目录,innodb能非常快速的定位某一条记录。但有个前提条件,就是用户记录必须在同一个数据页当中。
如果用户记录非常多,在第一个数据页找不到我们想要的数据,需要到另外一页找该怎么办呢?
这时就需要使用文件头部了。
它里面包含了多个信息,但我只列出了其中4个最关键的信息:
页号
上一页页号
下一页页号
页类型
顾名思义,innodb是通过页号、上一页页号和下一页页号来串联不同数据页的。如下图所示:
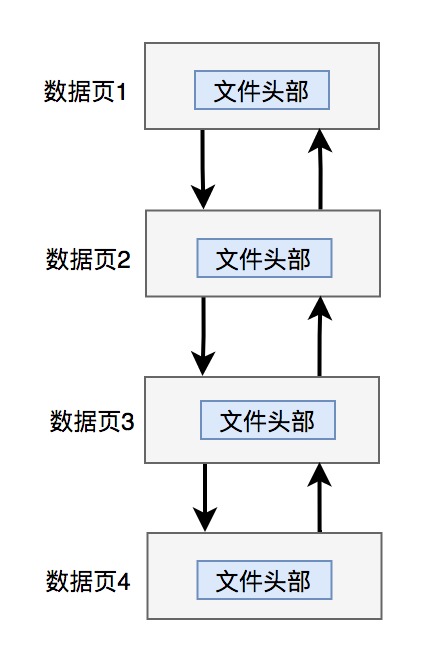
不同的数据页之间,通过上一页页号和下一页页号构成了双向链表。这样就能从前向后,一页页查找所有的数据了。
此外,页类型也是一个非常重要的字段,它包含了多种类型,其中比较出名的有:数据页、索引页(目录项页)、溢出页、undo日志页等。
6.2 文件尾部我之前提过,数据库的数据是以数据页为单位,加载到内存中,如果数据有更新的话,需要刷新到磁盘上。
但如果某一天比较倒霉,程序在刷新到磁盘的过程中,出现了异常,比如:进程被kill掉了,或者服务器被重启了。
这时候数据可能只刷新了一部分,如何判断上次刷盘的数据是完整的呢?
这就需要用到文件尾部。
它里面记录了页面的校验和。
在数据刷新到磁盘之前,会先计算一个页面的校验和。后面如果数据有更新的话,会计算一个新值。文件头部中也会记录这个校验和,由于文件头部在前面,会先被刷新到磁盘上。
接下来,刷新用户记录到磁盘的时候,假设刷新了一部分,恰好程序出现异常了。这时,文件尾部的校验和,还是一个旧值。数据库会去校验,文件尾部的校验和,不等于文件头部的新值,说明该数据页的数据是不完整的。
7.页头部通过上面介绍的内容,数据页之间能够轻松访问了,但剩下还有个比较重要的问题,就是记录的状态信息。
比如一页数据到底保存了多条记录,或者页目录到底使用了多个槽等。这些信息是实时统计,还是事先统计好了,保存到某个地方?
为了性能考虑,上面的这些统计数据,当然是先统计好,保存到一个地方。后面需要用到该数据时,再读取出来会更好。这个保存统计数据的地方,就是页头部。
当然页头部不仅仅只保存:槽的数量、记录条数等信息。
它还记录了:
已删除记录所占的字节数
最后插入记录的位置
最大事务id
索引id
索引层级
其实还有很多,在这里就不一一列举了,有兴趣的朋友可以找我私聊。
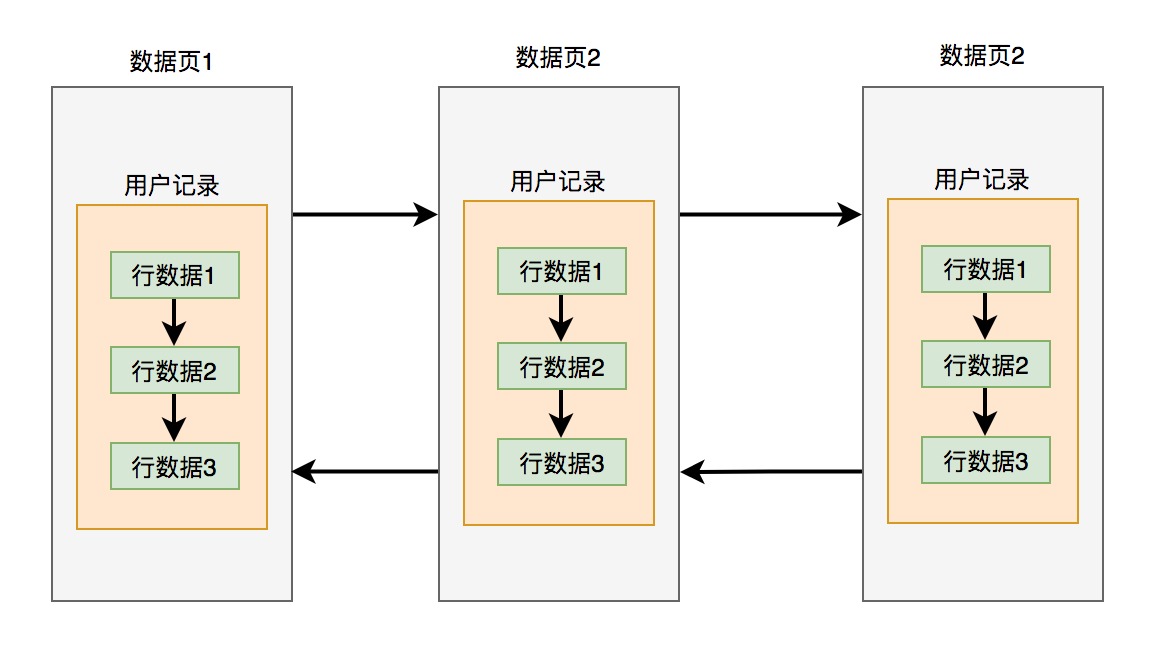
总结多个数据页之间通过页号构成了双向链表。而每一个数据页的行数据之间,又通过下一条记录的位置构成了单项链表。整体架构图如下:
好了,本文内容先到这里。如果小伙伴们有任何疑问的话,欢迎找我私聊。
顺便预告一下,在innodb的存储结构中,还有一个非常重要的内容没讲,它就是:索引。敬请期待,我们下期见。
最后说一句(求关注,别白嫖我)如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。