
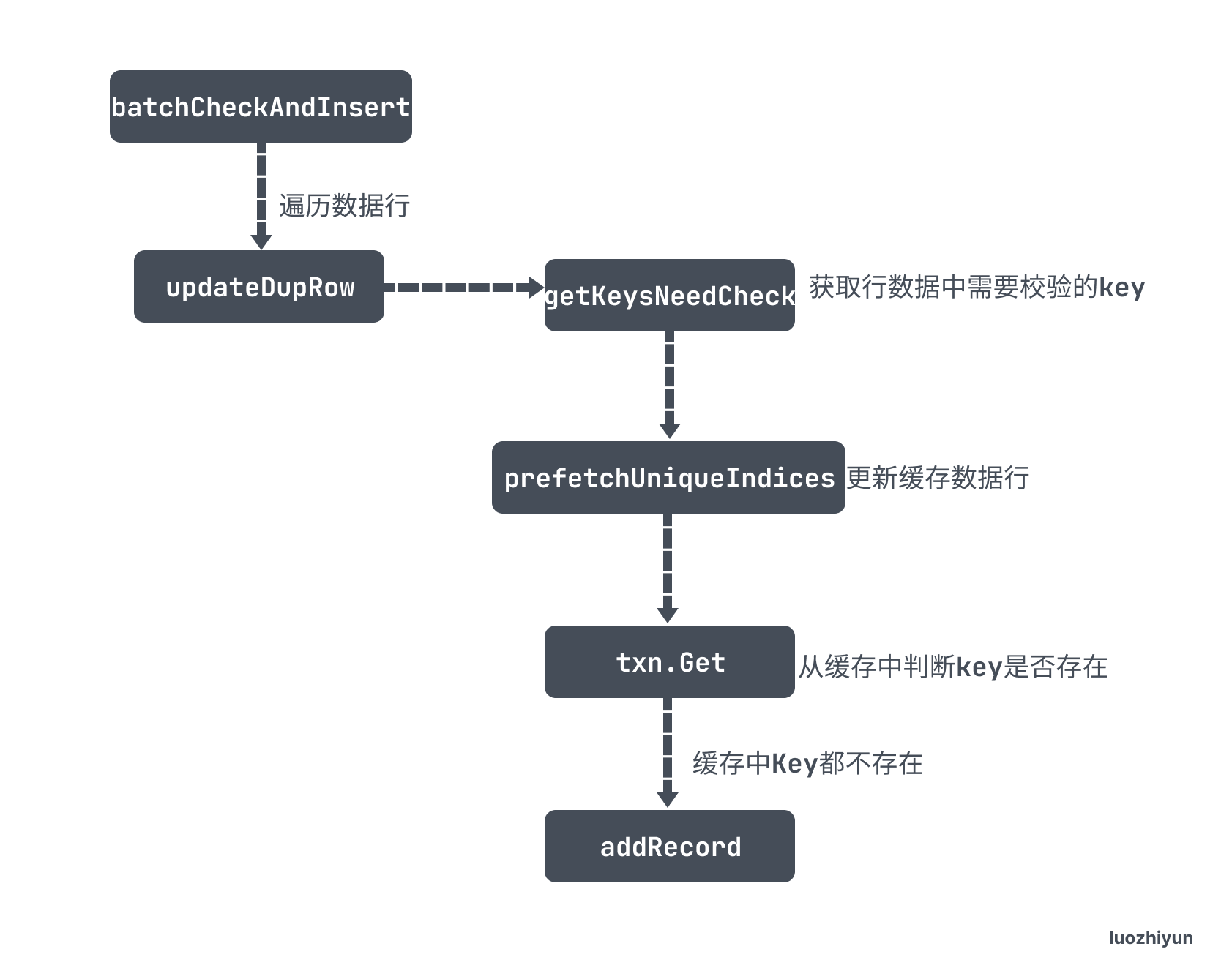
在 InsertExec 的 exec 方法中如果 SQL 语句包含 IGNORE 会进入到 IF 判断的第二个分支中调用 batchCheckAndInsert 方法进行冲突校验。
func (e *InsertValues) batchCheckAndInsert(ctx context.Context, rows [][]types.Datum, addRecord func(ctx context.Context, row []types.Datum) error) error { ... start := time.Now() // 获取行数据中需要校验的key,如主键,唯一键 toBeCheckedRows, err := getKeysNeedCheck(ctx, e.ctx, e.Table, rows) if err != nil { return err } // 获取事务处理器 txn, err := e.ctx.Txn(true) if err != nil { return err } // 批量从 tikv 中根据传入的 key 获取数据,存入到缓存中 if _, err = prefetchUniqueIndices(ctx, txn, toBeCheckedRows); err != nil { return err } for i, r := range toBeCheckedRows { if r.ignored { continue } skip := false // 判断主键 if r.handleKey != nil { // 从缓存中判断key是否存在,存在则重复 _, err := txn.Get(ctx, r.handleKey.newKey) if err == nil { e.ctx.GetSessionVars().StmtCtx.AppendWarning(r.handleKey.dupErr) continue } if !kv.IsErrNotFound(err) { return err } } // 判断唯一键 for _, uk := range r.uniqueKeys { // 从缓存中判断key是否存在,存在则重复 _, err := txn.Get(ctx, uk.newKey) if err == nil { // If duplicate keys were found in BatchGet, mark row = nil. e.ctx.GetSessionVars().StmtCtx.AppendWarning(uk.dupErr) skip = true break } if !kv.IsErrNotFound(err) { return err } } // 没有冲突,调用 addRecord 添加数据 if !skip { e.ctx.GetSessionVars().StmtCtx.AddCopiedRows(1) err = addRecord(ctx, rows[i]) if err != nil { return err } } } return nil }这一段代码比较长,但是也很好理解。
getKeysNeedCheck 作用是根据所有的 rows 数据封装好里面唯一键和主键的key,按照 TiKV 中存储的格式封装,我在上面普通 Insert 已经讲过了,这里就不再重复贴出 Key 的规则;
prefetchUniqueIndices 是根据 toBeCheckedRows 里面封装好的 Key 通过 BatchGet 发送 RPC 请求批量去 TiKV 获取数据,然后存入到缓存中;
然后会遍历 toBeCheckedRows 这里面的主键和唯一键,通过 txn.Get从缓存中判断key是否存在,存在则重复;
最后如果不冲突,那么会调用 addRecord 将数据缓存到本地事务中。
ON DUPLICATE 指的是INSERT ON DUPLICATE KEY UPDATE语句,它是几种 INSERT 语句中最为复杂的。其语义的本质是包含了一个 INSERT 和 一个 UPDATE。
它的入口在 InsertExec 执行 exec 方法的时候:
func (e *InsertExec) exec(ctx context.Context, rows [][]types.Datum) error { ... sessVars := e.ctx.GetSessionVars() defer sessVars.CleanBuffers() ignoreErr := sessVars.StmtCtx.DupKeyAsWarning // 判断是否有 OnDuplicate 语句 if len(e.OnDuplicate) > 0 { err := e.batchUpdateDupRows(ctx, rows) if err != nil { return err } // 判断是否包含 IGNORE 语句 } else if ignoreErr { ... // 普通 Insert } else { ... } return nil }与 INSERT IGNORE相同,首先会进入 IF 分支,判断是否包含 ON DUPLICATE执行语句,然后执行 batchUpdateDupRows 方法。
func (e *InsertExec) batchUpdateDupRows(ctx context.Context, newRows [][]types.Datum) error { ... // 构造唯一键和主键的key toBeCheckedRows, err := getKeysNeedCheck(ctx, e.ctx, e.Table, newRows) if err != nil { return err } txn, err := e.ctx.Txn(true) if err != nil { return err } // 根据key填充对应的缓存 if err = prefetchDataCache(ctx, txn, toBeCheckedRows); err != nil { return err } for i, r := range toBeCheckedRows { if r.handleKey != nil { handle, err := tablecodec.DecodeRowKey(r.handleKey.newKey) if err != nil { return err } // 根据主键判断是否有冲突,如果有冲突 err 则为 nil err = e.updateDupRow(ctx, i, txn, r, handle, e.OnDuplicate) if err == nil { continue } if !kv.IsErrNotFound(err) { return err } } // 如果主键没有冲突,那么判断唯一键是否有冲突 for _, uk := range r.uniqueKeys { val, err := txn.Get(ctx, uk.newKey) if err != nil { if kv.IsErrNotFound(err) { continue } return err } handle, err := tablecodec.DecodeHandleInUniqueIndexValue(val, uk.commonHandle) if err != nil { return err } err = e.updateDupRow(ctx, i, txn, r, handle, e.OnDuplicate) if err != nil { return err } newRows[i] = nil break } // 如果主键和唯一键都没有冲突,那么执行正常插入逻辑 if newRows[i] != nil { err := e.addRecord(ctx, newRows[i]) if err != nil { return err } } } if e.stats != nil { e.stats.CheckInsertTime += time.Since(start) } return nil }batchUpdateDupRows 方法首先会构造唯一键和主键的 key ,然后调用 prefetchDataCache 方法根据 Key 值一次性获取 TiKV 对应值填充缓存。