
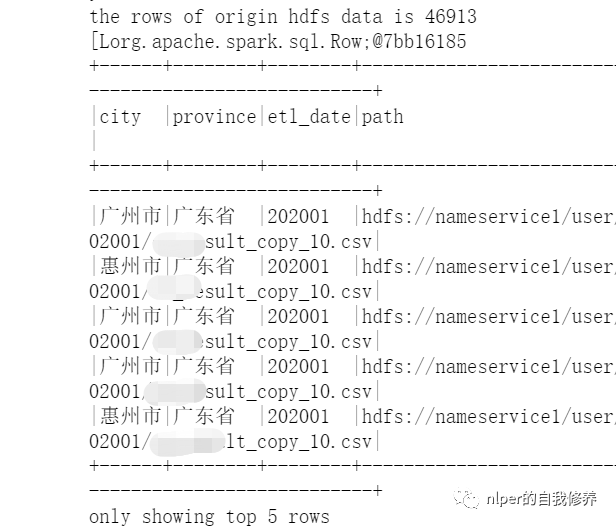
通过wholeTextFiles读取文件夹里面的文件时,保留文件名信息;
具体示例可以参考文末的
object LoadingData_from_hdfs_wholetext_with_path extends mylog{// with Logging ... def main(args: Array[String]=Array("tb1", "hdfs:/", "3","\n", "\001", "cols", "")): Unit = { ... val tb_name = args(0) val hdfs_address = args(1) val parts = args(2) val sep_line = args(3) val sep_text = args(4) val select_col = args(5) val save_paths = args(6) val select_cols = select_col.split("#").toSeq val Cs = new DataProcess_get_data(spark) val tb_desc = Cs.get_table_desc(tb_name) val rddWhole = spark.sparkContext.wholeTextFiles(s"$hdfs_address", 10) rddWhole.foreach(f=>{ println(f._1+"数据量是=>"+f._2.split("\n").length) }) val files = rddWhole.collect val len1 = files.flatMap(item => item._2.split(sep_text)).take(1).flatMap(items=>items.split(sep_line)).length val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString) import org.apache.spark.sql.types.StructType // 解析wholeTextFiles读取的结果并转化成dataframe val wordCount = files.map(f=>f._2.split(sep_text).map(g=>g.split(sep_line):+f._1.split("http://www.likecs.com/").takeRight(1)(0))).flatMap(h=>h).map(p => Row(p: _*)) val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType))) val new_schema1 = schema1.add(StructField("path", StringType)) val rawRDD = sc.parallelize(wordCount) val df_data = spark.createDataFrame(rawRDD, new_schema1) val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left") //df_desc.show(false) val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*) df_gb_result.show(5, false) println("生成的dataframe,依path列groupby的结果如下") df_gb_result.groupBy("path").count().show(false) ... // spark.stop() } } val file1 = "hdfs:file1_1[01].csv" val tb_name = "tb_name" val sep_text = "\n" val sep_line = "\001" val cols = "city#province#etl_date#path" // 执行脚本 LoadingData_from_hdfs_wholetext_with_path.main(Array(tb_name, file1, "4", sep_line, sep_text, cols, ""))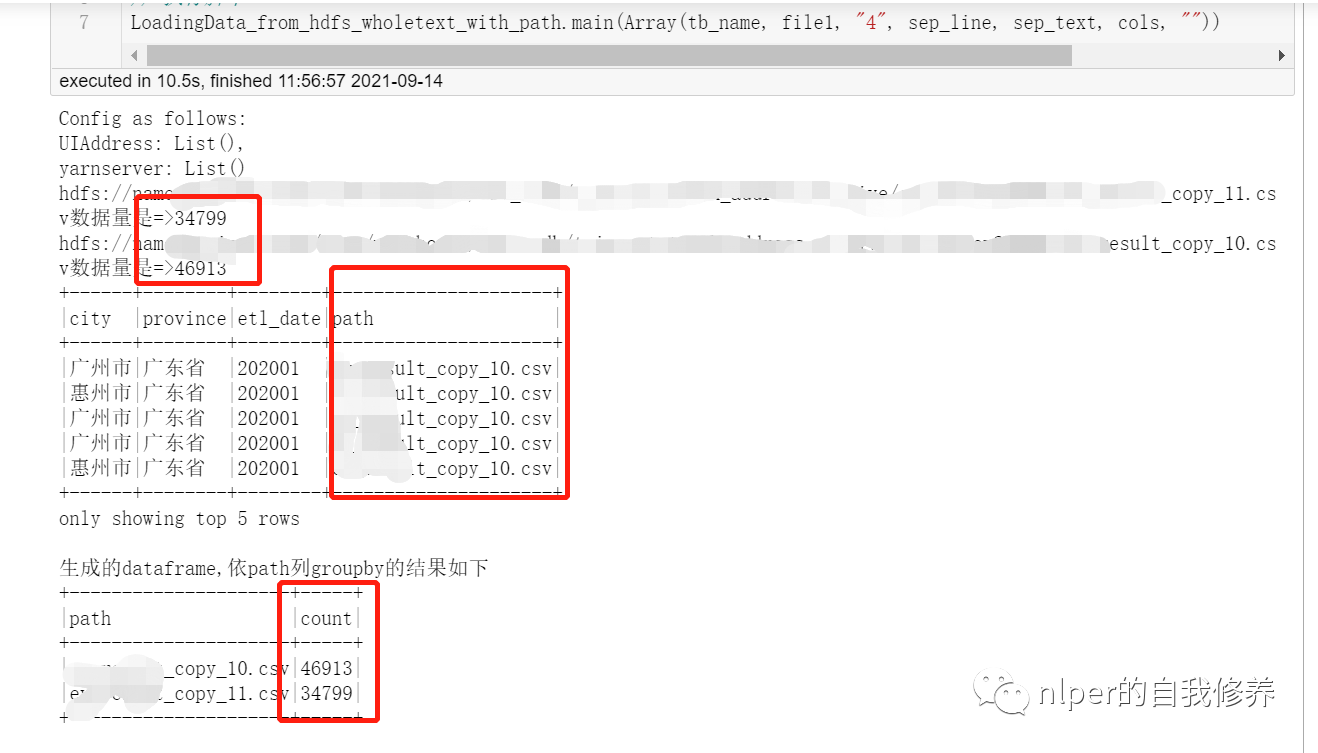
以下实现功能
将Array[(String, String)]类型的按(String, String)拆成多行;
将(String, String)中的第2个元素,按照\n分割符分成多行,按\?分隔符分成多列;
将(String, String)中的第1个元素,分别加到2中的每行后面。在dataframe中呈现的就是新增一列啦
业务场景
如果要一次读取多个文件,且相对合并后的数据集中,对数据来源于哪一个文件作出区分。
// 测试用例,主要是把wholetextfile得到的结果转化为DataFrame val test1 = Array(("abasdfsdf", "a?b?c?d\nc?d?d?e"), ("sdfasdf", "b?d?a?e\nc?d?e?f")) val test2 = test1.map(line=>line._2.split("\n").map(line1=>line1.split("\\?"):+line._1)).flatMap(line2=>line2).map(p => Row(p: _*)) val cols = "cn1#cn2#cn3#cn4#path" val names = cols.split("#") val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType))) val rawRDD = sc.parallelize(test2) val df_data = spark.createDataFrame(rawRDD, schema1) df_data.show(4, false) test1