Spark是一个小巧玲珑的项目,由Berkeley大学的Matei为主的小团队所开发。使用的语言是Scala,项目的core部分的代码只有63个Scala文件,充分体现了精简之美。
Spark要解决的问题是,在当前的分布式计算框架中不能有效处理的两类问题:iterative(迭代计算)和 interactive(交互式)计算。
目前最流行的Hadoop 系统实现了DAG(有向无环图)的data flow 式的计算,不能处理有环的计算,也就是输入同时做为输出的循环计算。
Spark更适合于迭代运算比较多的ML(machiningleaning和DM(data mining)运算。Google 的Pregel 的分布式图计算中,就含有大量的迭代计算。
那么Spark是如何实现的呢?其主要的思想就是RDD(Resilient Distributed Dataset),把所有计算的数据保存在分布式的内存中。在迭代计算中,通常情况下,都是对同一的数据集做反复的迭代计算,数据保存在内存中,将大大提高性能。 RDD就是数据partition方式保存在cluster 的内存中。操作有两种: transformation 和 action, transform就是把一种RDD转换为另一个RDD,和Hadoop的 map 操作很类似,只是定义operator比较丰富(map, join,filter, groupByKey 等操作), action 就类似于hadoop 的reduce,其输出是一个aggregation函数的值如count,或者是一个集合(collection)。
Spark 的设计思想并没有什么独特之处,核心就是内存计算。关键的问题是,如何处理fault tolerance这个核心的问题?我们知道hadoop 的核心就是 MapReduce,其计算模型是:
Input(HDFS) --> output(HDFS), 其输入和输出都是在persistent的 disk上保存,并且有replication. 如果输入和输出节点都崩溃,其还有副本,选择一个新节点重新计算。
如果数据保存在内存中,一旦宕机,数据永久丢失。通常的处理方法就是做checkpoint 和 log updates across machine两种方法。
Spark并没有提供一个比较好fault tolerance的方法,其论文中提到的lineage(血统)的方法: logging the transformations used to build a dataset,就是log 每次操作(lineage)用来恢复。
我们看一下Spark操作模型:
Input(RAM) ---> output(RAM) 的计算模型。
在论文中,Spark提到了两种依赖(Dependency)。
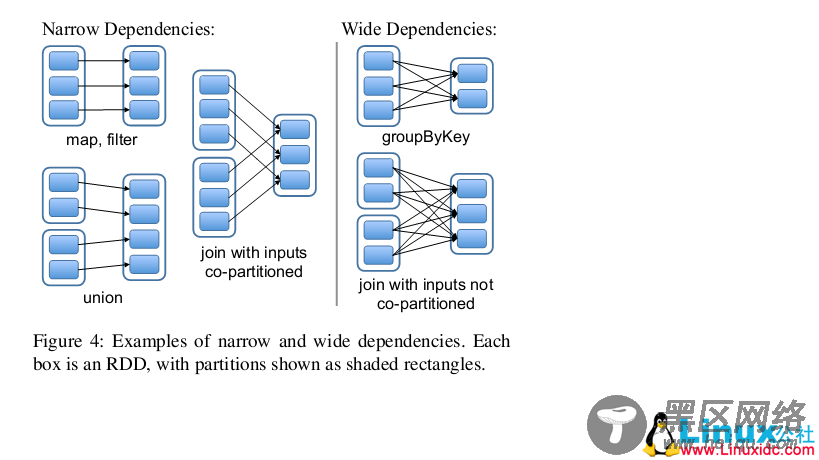
一种是Narrow Dependencies这个计算完全在本地的内存中,对于所谓的Lineage的容错方法对这种情况是没有用的,因为输入和输出在同一个节点,一旦该节点宕机,数据全丢。论文中提到的work around方式是replication;
对与Wide Dependencies,这种计算的输入和输出在不同的节点上,lineage方法于:输入节点完好,而输出节点宕机的情况有效的,通过只重新计算宕机的分区即可。在输入节点宕机的情况下,显然重试是无效,需要向上追溯其祖先看是否可以重试(这就是lineage,血统的意思)。
Spark 论文最后提到了,提供了一种checkpoint 的标志。至于何时做chenkpoint,由用户根据业务自己决定。在论文Discussion部分,提到今后的研究就是如何实现自动的checkpoint操作。MPI的fault tolerance的方法,就是做各种checkpoint的策略,这个在高性能计算已经研究了好多年了,并有很多方法。
最后感叹,很多的研究,转了一圈,最后又回到了起点。