
编译Hadoop2.6.0的eclipse插件
下载源码:
git clone https://github.com/winghc/hadoop2x-eclipse-plugin.git
编译源码:
src/contrib/eclipse-plugin
ant jar -Dversion=2.6.0 -Declipse.home=/usr/local/eclipse -Dhadoop.home=/usr/local/hadoop-2.6.0 //需要手动安装的eclipse,通过命令行一键安装的不行
eclipse.home 和 hadoop.home 设置成你自己的环境路径
生成位置:
[jar] Building jar: /home/hunter/hadoop2x-eclipse-plugin/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.6.0.jar
安装插件
登录桌面后面要打开eclipse的用户最好是hadoop的管理员,也就是hadoop安装时设置的那个用户,否则会出现拒绝读写权限问题。
复制编译好的jar到eclipse插件目录,重启eclipse
配置 hadoop 安装目录
window ->preference -> hadoop Map/Reduce -> Hadoop installation directory
配置Map/Reduce 视图
window ->Open Perspective -> other->Map/Reduce -> 点击“OK”
windows → show view → other->Map/Reduce Locations-> 点击“OK”
控制台会多出一个“Map/Reduce Locations”的Tab页
在“Map/Reduce Locations” Tab页 点击图标<大象+>或者在空白的地方右键,选择“New Hadoop location…”,弹出对话框“New hadoop location…”,配置如下内容:将ha1改为自己的hadoop用户
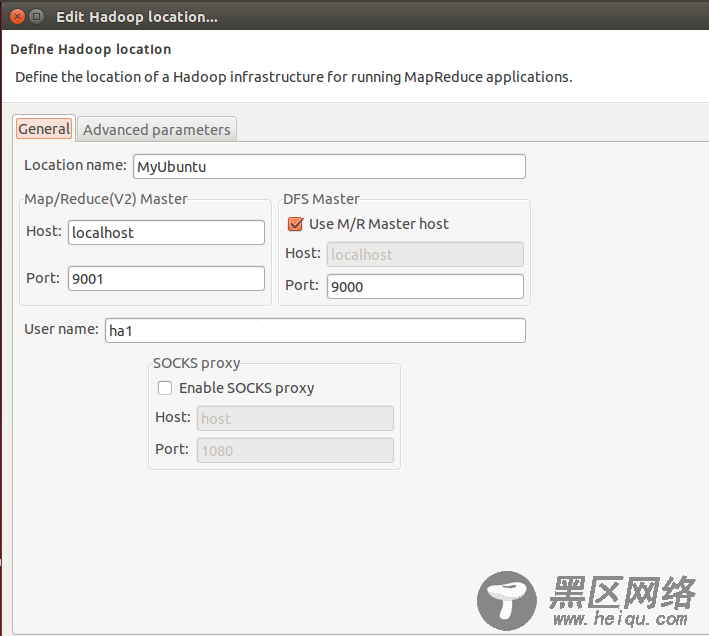
注意:MR Master和DFS Master配置必须和mapred-site.xml和core-site.xml等配置文件一致
打开Project Explorer,查看HDFS文件系统。
新建Map/Reduce任务
File->New->project->Map/Reduce Project->Next
编写WordCount类:记得先把服务都起来
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
配置运行时参数:右键-->Run as-->Run Confiugrations
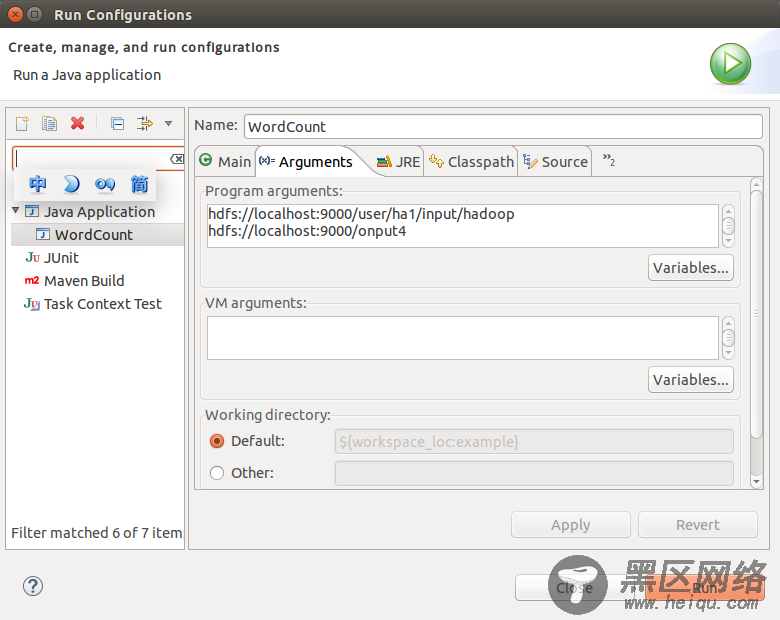
user/ha1/input/hadoop是你上传在hdfs的文件夹(自己创建),里面放要处理的文件。ouput4放输出结果
将程序放在hadoop集群上运行:右键-->Runas -->Run on Hadoop,最终的输出结果会在HDFS相应的文件夹下显示。至此,Ubuntu下hadoop-2.6.0 eclipse插件配置完成。
配置过程中出先的问题:
在eclipse中无法向文件HDFS文件系统写入的问题,这将直接导致eclipse下编写的程序不能在hadoop上运行。
打开conf/hdfs-site.xml,找到dfs.permissions属性修改为false(默认为true)OK了。
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
改完需要重启HDFS;
最简单的就是刚才说的登录桌面启动eclipse的用户本身就是hadoop的管理员