
随着Linux系统在企业中的应用越来越多,服务器的自动化管理也变得越来越重要。在Linux服务器的自动化维护工作中,除了计划任务的设置以外,Shell脚本的应用也是非常重要的一部分。作为Linux系统运维工程师,必须得要掌握Shell脚本的基本知识和编写及使用。
shell脚本基础在一些复杂的Linux维护工作中,大量重复性的输入和交互操作不仅费时费力,而且容易出错,而编写一个恰到好处的Shell脚本程序,可以批量处理、自动化地完成一些列维护任务,大大减轻管理员的负担。
一、编制shell脚本Linux系统中的Shell脚本是一个特殊的应用程序,它介于操作系统内核与用户之间,充当了一个“翻译官”的角色,负责接收用户输入的操作指令并进行解释,将需要执行的操作传递给内核执行,并输出执行结果。如图:
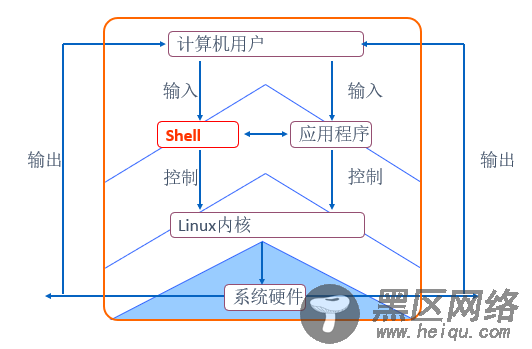
Linux系统中常见的shell解释程序有很多种,使用不同的shell脚本时,其内部指令、命令提示灯方面会存在一些区别。 [root@localhost ~]# cat /etc/shells //查看当前系统支持哪些shell * /bin/sh * /bin/bash * /sbin/nologin * /usr/bin/sh * /usr/bin/bash * /usr/sbin/nologin * /bin/tcsh * /bin/csh [root@localhost ~]# /bin/sh //切换shell sh-4.2# exit //返回上一层shell [root@localhost ~]#
/bin/bash是目前大多数Linux版本采用的默认shell脚本。
shell脚本:简单来说就是把在命令行执行的命令按顺序存放在一个文本文件中,赋予其可执行权限。那么这个文本文件就可称为一个脚本。比如:
[root@localhost ~]# cd / [root@localhost /]# pwd / //这是两条命命输出的结果 [root@localhost ~]# vim a.sh //编写为本文件,以“.sh”结尾只是为了让别人知道这是一个脚本。 cd / pwd [root@localhost ~]# chmod +x a.sh //服务文本文件可执行的权限 [root@localhost ~]# ./a.sh / //查看脚本的执行结果和命令行执行的结果是一样执行脚本的方法:
“./”:(相对或绝对路径)这种方法脚本必须得需要可执行权;
sh:通过/bin/sh来解释脚本;
source或“.”:内部命令来加载脚本中的内容。
前两种方法是在子shell中执行;第三种方法是在当前shell中执行!
由于shell脚本的“批量处理”的特殊性,其大部分操作过程以静默的方式运行,不需要用户干预。因此学会提取、过滤执行信息变得十分重要。
1.重定向操作用户通过操作系统处理信息的过程中,包括三类交互设备文件:
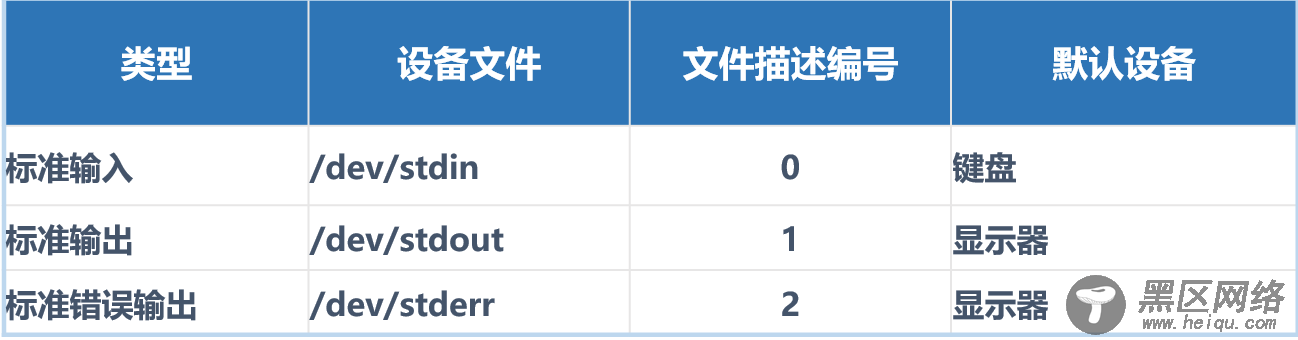
标准输入:从该设备接收用户输入的数据;
标准输出:通过该设备向用户输出数据;
标准错误:通过该设备报告执行出错信息。
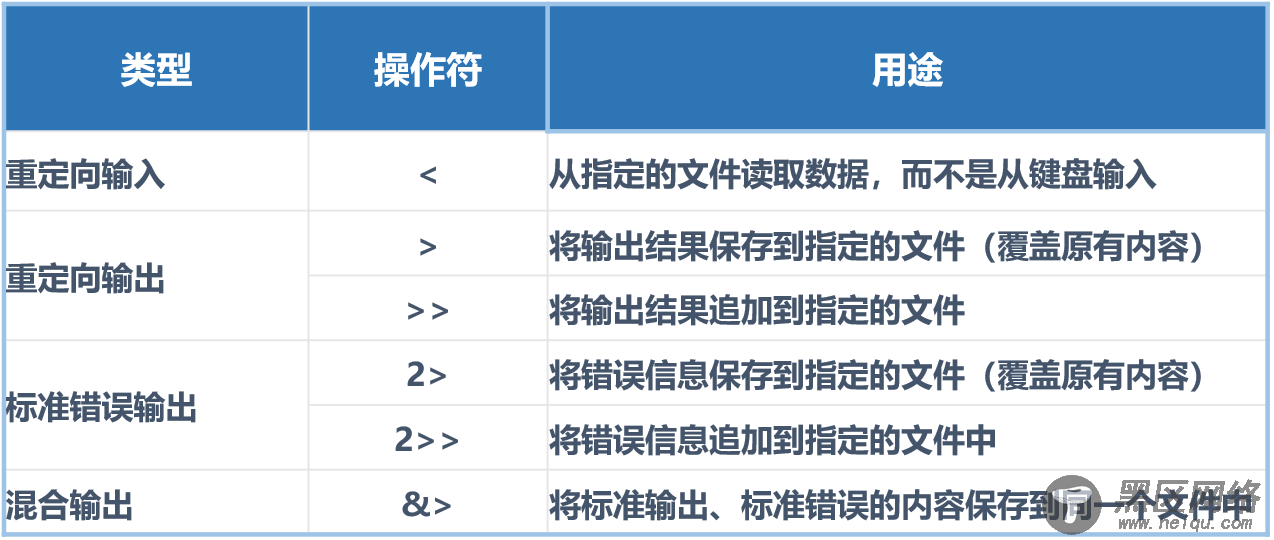
重定向的类型分为:
管道符的作用就是将左侧的命令输出结果,作为右侧命令的处理对象。比如:
[root@localhost ~]# df -hT | grep "/$" | awk '{print $6}' 26% //提取根分区(/)的磁盘使用率信息 三、shell变量各种Shell环境中都使用到了“变量”的概念。Shell变量用来存放系统和用户需要使用的特定参数(值),而且这些参数可以根据用户的设定或系统环境的变化而相应变化。通过适当地使用变量,Shell程序能够提供更加灵活的功能,适应性更强。
Linux系统下常见的四种变量: 1.自定义变量自定义变量是由系统用户自己定义的变量吗,只在用户自己的Shell环境中有效,因此,也有人称为本地变量。在编写Shell脚本程序是,用户通常会设定一些特定的自定义变量,以适应程序执行过程中各种变化,以满足不同的需求。
1)定义新的变量
定义变量的基本格式“变量名=变量值”,等号两边不允许有空格。变量名称需要以字母或下划线开头,名称中不要包含特殊字符(比如:+、-、*、/、……?、&、%等)。比如:
2)查看和引用变量
通常在变量名称前添加前导符“$”,可以引用一个变量的值。比如: