
熟悉MySQL的人,都知道InnoDB存储引擎,如大家所知,Redo Log是innodb的核心事务日志之一,innodb写入Redo Log后就会提交事务,而非写入到Datafile。之后innodb再异步地将新事务的数据异步地写入Datafile,真正存储起来。
那么innodb引擎有了redo log和buffer pool以后,为什么能够在提升性能的同时,还能保证不丢数据呢? Buffer Pool, Redo Log以及Datafile之间的具体关系是什么呢。
另外Innodb还有一大堆概念,Dirty Page, LRU, LSN,Checkpoint等等,这些概念在Innodb里是什么运作的呢?
下面通过一张图来告诉大家
Buffer Pool, Redo Log以及Datafile的关系
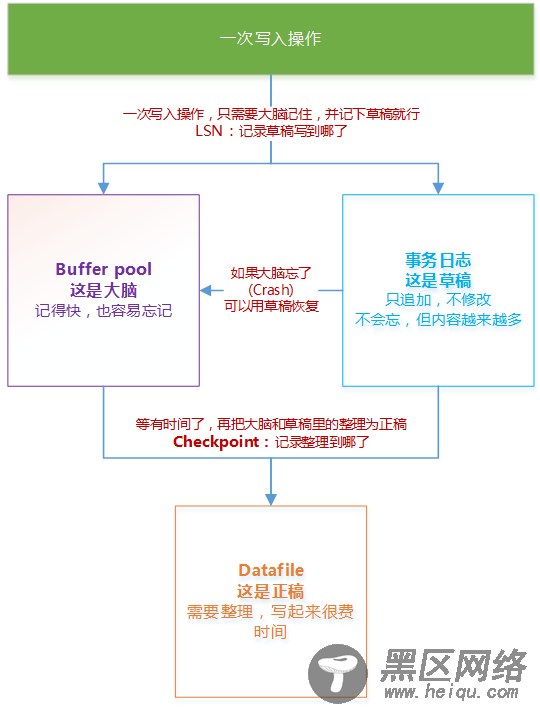
大家可以把innodb的事务写入过程看成写作一篇文章的过程。Innodb的写入过程其实和我们写作的过程是非常类似的。
试想,领导让我们写一篇文章,发表在论坛上。然后我们想到了一个绝佳的点子,并决定要放到文章里,可是手上还有其他事情,一时半会儿写不完,又担心过后忘了,领导还等着我们答复,此时我们会怎么做呢?我们一定会先大概构思个提纲,并把提纲和一些关键细节记录到本子上,作为草稿,然后立刻告诉领导自己要写什么东西,让其确认。最后等晚上有时间了,再根据草稿去斟词酌句,编写正稿。
在这个过程中,我们用到的几个关键的东西:
我们的大脑,用来临时暂时记住我们的点子
草稿,我们需要草稿来保证不会把点子和关键的细节给忘了
正稿,这是我们最终要输出的东西
有了这几个东西,我们不仅能确保我们不会错过一篇漂亮的文章,还能快速告诉领导自己一定可以搞定这件事情。
Innodb实际上也用到了这几个关键的东西:
Buffer Pool:就是我们的大脑
事务日志:就是我们的草稿
Datafile:就是我们的正稿
只要按照之前写文章的过程,来进行整个事务的写入操作,不仅能保证不丢失数据,而且能够快速响应。
一次写入操作是一次事务,innodb首先把事务数据写入到Buffer Pool和事务日志中,也就是在大脑中记忆下来,并写下草稿。然后就可以提交事务,响应客户端了。之后innodb在“有时间的时候”,异步地把这次写入的数据从Buffer Pool,或者事务日志中正式地写入到Datafile中,形成“正稿”。
其中,innodb为了保证事务日志这个“草稿”一定能无损地还原成正稿,还不能占用太多空间,事务日志需要有以下特点:
事务日志中一定保存了要写入的所有数据内容
事务日志只会把新事务追加在日志最后,而不会去修改之前的内容
一旦事务数据被写到datafile,事务日志中的“草稿”就可以删除了
通过上面3个特点我们可以看出,在形成“正稿”之前,“草稿”是不会被删除的;同时,“草稿”的空间是可以被循环利用的;最后,只要“草稿”在,我们一定能写出“正稿”。
这里还需要说明的,是Recovery流程。也就是如果在形成“正稿”前,数据库Crash了,我们需要重启整个进程,服务器,甚至只能把数据复制到另外一台服务器来进行恢复。这个时候,事务日志这个“草稿”就发挥了它最大的作用——数据恢复。这也和我们在工作生活中常出现的问题——把事情忘了——非常类似。
Buffer Pool本质就是存储于内存中的一个数据结构,内存和人的大脑一样,是“健忘”的。数据库Crash时,Buffer Pool中的数据极大可能“灰飞烟灭”了。因此,事务日志就如我们贴心的“记事本”,它把我们的记忆,保存为“草稿”,当我们忘了的时候,就可以翻开,把记忆重新回想起来。

LSN和Checkpoint
上面介绍了一次写入事务的情况,而数据库在使用过程中,事务都是连续不断,根据上面所述innodb逻辑,写“草稿”和写“正稿”速度和进度绝大部分情况下是不一样的。
再继续上面“写作文章”例子,如果我们的文章很长,一天写不完,而白天都有其他工作,我们只能记录草稿,只有晚上回去才能继续写正稿。那么我们就面临一个问题:我们昨天写到哪了。
最常见的办法就是,每天晚上去对照一下草稿的内容和正稿的内容,以此来判断写到哪了,但这比较花时间,因为正稿中可能包含了很多华丽的语句,我们需要思考一下才能对比上内容。