
当要把一个新的键值对添加到字典里面时,程序先要根据键值对中的键值计算出哈希值,再计算出索引值,然后将包含新键值对的哈希表结点放到哈希表数组的指定索引上面。
Redis使用murmurhash算法来计算哈希值
解决键冲突键冲突:存在两个或者两个以上的键被分配到了哈希表数组的同一个索引上面。
解决办法:Redis的哈希表使用开链法来解决冲突,每个哈希表结点都存在一个next指针,多个哈希表值可以用next指针来构成一个单向链表,被分配到同一个索引上的多个结点可以用这个单向链表连接起来,从而解决键冲突问题。
需要注意的是,因为考虑到下次方便再次读取,因此总是将冲突的新结点插入到链表的表头位置,也就是已有其他结点的前面。
rehash当哈希表的负载因子(已有数量/表数量)达到一个阀值以后,再次保存新的键值对时,冲突的几率将逐渐增加,因此需要进行响应的扩展(收缩)。
以扩展为例,程序需要经过以下步骤(腾笼换鸟):
扩展空间:为字典的ht[1]哈希表分配空间,其空间将会被扩展到第一个大于等于ht[0].used*2^n的整数值;
数据迁移:将保存在ht[0]上的所有键值对迁移到ht[1]中;
交换:迁移完后,释放掉ht[0],将现在的ht[1]设置为ht[0],并且为ht[1]新创建一个空白哈希表,实现了相互交换的过程;
渐进式rehash为了避免一次性交换所造成的性能影响,Redis采用的是渐进式rehash,也就是说,将会分多次、渐进式的完成数据的迁移。所以会同时存在两个哈希表数组,并不会急着一次性的将数ht[0]的数据迁移到ht[1]中,而是在每次操作的同时,将部分的ht[0]中的数据保存到ht[1]中,采用愚公移山的方式最终将ht[0]中的数据搬完,为了避免ht[0]中的数据不断增加,相关的增加的操作都会作用在ht[1]之上,最后,搬完后的操作和之前的操作是一致的。
它的优点在于:采用了分而治之的方式,将rehash键值对所需的操作均摊到字典的每个添加、删除、查找和更新操作之上,从而避免集中式rehash而带来的庞大计算量。
我认为它的缺点也是存在的,譬如在查询的时候,可能在ht[0]中查找不到,还得跑到ht[1]中查找,无形中增加了开销。
跳跃表跳跃表是一种有序数据结构,它通过在每个结点中维持多个指向其它结点的指针,从而达到快速访问结点的目的。其查找的时间复杂度平均可以达到O(logn),最坏O(N),还可以通过顺序性操作来批量处理结点。
目前,Redis中只有两个地方用到了跳跃表,一个是有序集合键,另外一个是集群结点中用作内部数据结构。
跳跃表由多个跳跃结点组成:
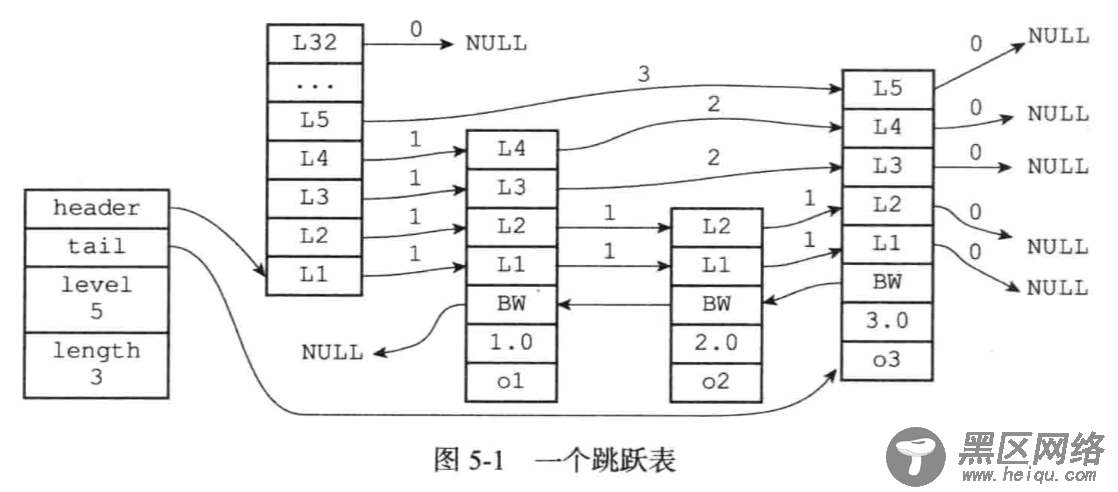
typedef struct zskiplistNode{ //层 struct zskiplistLevel{ //前进指针 struct zskiplistNode *forward; //跨度 unsigned int span; } level[]; //后退指针 struct zskiplistNode *backward; //分值 double score; //成员对象 robj *obj; }
层:level 数组可以包含多个元素,每个元素都包含一个指向其他节点的指针。
前进指针:用于指向表尾方向的前进指针
跨度:用于记录两个节点之间的距离
后退指针:用于从表尾向表头方向访问节点
分值和成员:跳跃表中的所有节点都按分值从小到大排序。成员对象指向一个字符串,这个字符串对象保存着一个SDS值
跳跃表typedef struct zskiplist { //表头节点和表尾节点 structz skiplistNode *header,*tail; //表中节点数量 unsigned long length; //表中层数最大的节点的层数 int level; }zskiplist;