之前项目里遇到一个需求,需要前端上传一个word文档,然后后端提取出该文档的指定位置的内容并保存。这里后端用的是nodejs,开始接到这个需求,发现无从下手,主要是没有处理过word这种类型的文档,怎么解析? Excel倒是有相关的库可以用,而且很简单
思路
搜索了好一会儿,在npm上发现了一个叫做 adm-zip 的包,这个包可以解压缩word文档,原来word文档也是可以解压缩的,之前一直不知道,通过如下代码就可以将word文档解压缩,并进一步提取内容
var admZip = require('adm-zip'); const zip = new admZip('test.docx'); //将该docx解压到指定文件夹result下 zip.extractAllTo("./result", /*overwrite*/true);
首先我们新建一个docx文档,内容如下

然后运行上述代码进行解压缩,得到如下的文件,由下图可以看出生成了好几个文件夹,word的内容其实是在word文件夹里的document.xml文件内(这里解压缩后其实源文件还在,并没有消失)

进入word文件夹后的内容
我们继续打开document.xml文件来一探究竟里面到底是啥?注意要用浏览器直接打开,如果用ide打开显示出的所有内容都在一行,无法阅读!

上图只是word文档的一部分,会发现word文档内看着只有几段文字,但是xml中却是长篇大论,仔细分析下也很正常,xml全称可扩展标记语言,其被设计为传输和存储数据,它仅仅是一个纯文本的表示,而word中内容格式千变万化,肯定需要一种方法来有效描述这些内容的格式,因此采用了xml来描述
我们尝试一下将 测试文档 四个字加粗变色倾斜字体,如下图
然后再进行解压缩,得到docuemnt.xml并查看对应的内容,如下

这就很明显了, <w:b/> 表示文字加粗, <w:i/> 表示文字倾斜, <w:color>
表示文字的颜色,所以这么4个字就需要这几行xml来描述,因此长篇大论的xml也就不足为奇
提取内容
上面说到了xml仅仅是一个文本的表示,我们可以用如下代码读取整个xml的内容,结果是一个 string
var contentXml = zip.readAsText("word/document.xml");
接下来是重点,如何提取我们想要的内容呢,答案是正则表达式,首先我们得分析一下word文档的结构,word文档其实是由叫做 Paragraph 的段落所构成,在vb中可以很轻松的获取并修改段落,官网传送门点此

那么到底怎么样才是一个 Paragraph 呢,其实很简单,仔细观察word文档,见到下图中的小箭头了么,每个小箭头前面的内容就是一个段落,那么下图中一共有16个 Paragraph ,当然有些段落是空的,没有任何内容

我们再来研究xml的结构,收起展开的xml,如下图,发现 <w:p></w:p> 这么个标签就是表示的一个段落,中间还有些 <w:p>
藏在表格内,这么一看表格前面3个段落,后面3个段落,和上图是对应的
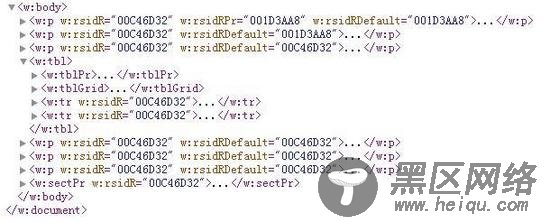
因此, 我们就可以提取出每个段落的文本并返回一个数组,每一项就是一个段落的内容 ,这样就能够完整的解析出整个word的内容,关键在于如何提取每个 <w:p> 的内容,我们继续展开一个 <w:p> 进行观察,如下图,发现内容虽多,其实文本都保存在 <w:t> 中间,因此思路就清晰了, 首先用正则表达式提取出所有<w:p>的内容,再针对每个<w:p>的内容,进行进一步正则提取,提取出其里面所有<w:t>的内容,并拼接在一起构成一个段落的总内容

具体代码
下面是具体的提取代码