
同时输出匹配行后的 n 行
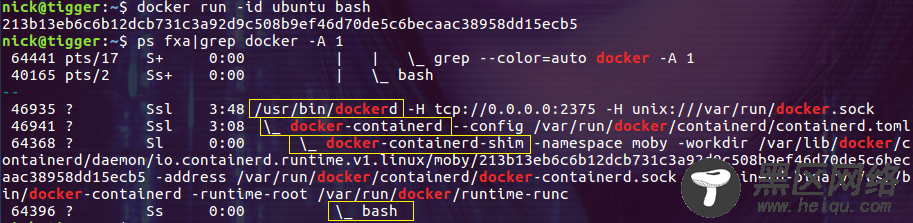
使用选项 -A n 可以输出匹配行后的 n 行,结合 ps 命令,可以用来查找某个进程的子进程。下面的例子通过 -A 1 输出容器运行的进程(bash):
$ ps fxa | grep -A 1 docker
同时输出匹配行前后的行
有时我们想要看到匹配行的前后行的内容,使用选项 -C n 可以实现这个功能,比如下面的命令会同时输出匹配行前后 1 行的内容:
$ grep -C 1 'grey' email1.txt
在输出中显示行号
使用选 -n 可以在输出中显示行号:

统计匹配到的行的数量
使用选项 -c 可以统计匹配到的行的数量:
反转匹配条件
如果我们想要获取正则表达式没有匹配到的行,可以使用选项 -v, --invert-match:
$ grep -v '^[a-zA-Z].*' email1.txt

上面的输出为不是以字母开头的行。
只匹配完整的行
如果我们只对一个完整的行感兴趣,可以使用选项 -x, --line-regexp。这样会忽略那些包含在行中的内容:
从文件中读取正则表达式
如果正则表达式太长,或者是需要指定多个正则表达式,可以把它们放在文件中,然后使用 选项 -f FILE, --file=FILE 来指定这个文件。如果指定了多个正则表达式(每行一个),任何一个匹配到的结果都会被输出:

使用预定义的命名字符类
$ grep '[[:digit:]]\{1,3\}' email1.txt
BRE(basic regular expression) 语法 说明 解释
. 匹配一个任意的字符 在 [] 中 . 号并不是元字符
^ 行的起始 ^ 和 $ 匹配的是一个位置而不是具体的文本
$ 行的结束 ^ 和 $ 匹配的是一个位置而不是具体的文本
* 匹配 0 次或多次 不匹配上一次表达式,匹配上一次或匹配多次,并生成所有可能的匹配
匹配尽可能多的次数,如果实在无法匹配,也不要紧
[] 匹配若干个字符之一 又叫字符组、字符类,比如 [0-9]、[a-z]、[A-Z]
只有在字符组内部 - 才是元字符,表示一个范围
[^...] 排除型字符组 字符组以 ^ 开头,它会匹配一个任何未列出的字符
\? 可选元素 在 BRE 中需要使用转义符 \
出现一次或者不出现
\+ 匹配 1 次或多次 在 BRE 中需要使用转义符 \
匹配前面表达式的至少一个搜索项
匹配尽可能多的次数,如果实在无法匹配,也不要紧
\{min,max\} 量词区间 在 BRE 中需要使用转义符 \
\| 或(多选结构) 在 BRE 中需要使用转义符 \
bob\|nick 能够同时匹配其中任意一个的正则表达式,此时的子表达式被称为 "多选分支"
多选结构可以包括很多字符,但不能超越括号的界限
\(\) 分组 在 BRE 中需要使用转义符 \
括号能够 "记住" 它们包含的子表达式匹配的文本
反向引用(backreference)是正则表达式的特性之一,它允许我们匹配与表达式先前部分匹配的同样的文本
\<\> 单词分界符 在 BRE 中需要使用转义符 \
< 和 > 本身并不是源字符,只有它们与反斜线结合时才具有单词分界符的含义
\ 转义符 如果需要匹配的某个字符本身就是元字符,就需要使用转义符
命名的字符类 命名的预定义字符类 [[:upper:]] [A-Z]
[[:lower:]] [a-z]
[[:digit:]] [0-9]
[[:alnum:]] [0-9a-zA-Z]
[[:space:]] 空格或 tab
[[:alpha:]] [a-zA-Z]
ERE(extended regular expression)
与 BRE 相比 ERE 最大的优点是支持更多的元字符,也就是在使用这些字符时不需要 \ 了。比如上面 BRE 中使用的 \ 符可以全部去掉。
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx