
正则表达式说白了就是有普通字符、以及特殊字符组成的文子模式。{匹配模式标准}
正则表达式将会作为一个模板与所搜索的字符串进行匹配。可以让使用者轻易达到搜寻/删除/取代某些特定字符的处理程序。此外vim、grep、find、awk、sed等命令都支持正则表达式
注:在这里希望大家搞明白一件事,那就是通配符和正则表达式的区别与关系:
1、正则表达式是用来匹配字符串的,这个就不解释了
2、通配符是用来通配的,也就是shell在做Pathname Expansion时用到的
那么在什么情况下使用呢?
在什么地方使用通配符?答案是只要是shell命令行或者shell脚本中,你都可以使用通配符
在什么地方使用正则表达式?当你使用能够支持正则表达式的工具软件进行字符串处理时你就可以使用正则表达式
一、常用的正则表达式:
1)、 . 代表任意单个字符;如要查看某行中的put,可以使用p.t 文件名与之相互匹配。
2)、 ^号代表开始;如以T开头的行进行匹配.
3)、$代表行的结束;如以tty结束的行进行匹配:
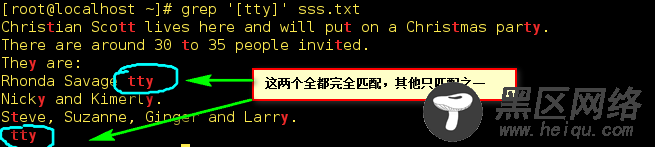
4)、[...]匹配括号中的字符之一。但是只要有和方括号内的字符相同将会全部匹配:
如[tty] 匹配包含tty其中之一字符或者全部包括
注:数字或者大小写字符和上面的都是相同的道理这里不在演示,有兴趣大家可以自己进行测试。
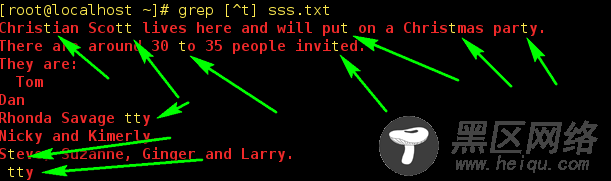
5)、[^xx]这个表示把某个字符或者数字排除在外的匹配,类似与取反的操作:
6)、 * 用于修饰前导字符,表示前导字符出现0次或任意多次,*代表所有和前导字符相同的字符。如:

7)、\?同样用于修饰前导字符,表示前导字符出现0次或者1次
8)、\+修饰前导字符,表示前导字符出现1次或者多次
这三种方式的使用方式基本一样,但就是前导字符出现的次数有所不同,上面已经标明了次数
9)、\{n,m\}同样用于修饰前导字符,但是在这里的n和m表示的是出现的次数,而不是个数,希望大家千万不要混淆。比如匹配连续2到4个a
注意了:在这里换可以使用其他的两种方式进行显示结果:
方式一:
方式二:
这里使用的三种方式进行显示,但是呢,都是进行了转译之后才可以的到想要的结果。egrep就属于转译,另外grep -E也是转译,最后a\{2,4\}也是转译,不管使用那种方式,都可以得到想要的结果,
\ 用于转义紧跟其后的单个特殊字符,使该特殊字符成为普通字符
在这里这个不做深入的研究。
另外还有其他的几种形式:
\{n\} 连续的n个前导字符
\{n,\} 连续的至少n个前导字符
不知道上面的大家伙有没有看明白,如果要是没有看明白的话这里将会为大家继续讲解一个综合的例子希望大家可以看的更加明白一些:
Christian Scott lives here and will put on a Christmas party.
There are around 30 to 35 people invited.
They are:
Tom
Dan
Rhonda Savage
Nicky and Kimerly.
Steve, Suzanne, Ginger and Larry.