
1.操作系统是怎么组织进程的?
1.1什么是线程,什么是进程:
刚接触时可能经常会将这两个东西搞混。简单一点的说,进程是一个大工程,线程则是这个大工程中每个小地方需要做的东西(在linux下看作"轻量级进程"):
例如当你打开QQ微信,这时系统启动了一个进程。然后你开始看别人发的消息,这时启动了一个线程用来传输文本,如果发了一段语音,这也会启动一个线程来传输语音......(当然一个程序并不代表一定只有一个进程)
1.2进程内核栈与thread_info(用于存储进、线程及其信息等):
struct task_struct {
......
/* 指向进程内核栈 */
void *stack;
......
};
1 union thread_union {
2 struct thread_info thread_info;
3 unsigned long stack[THREAD_SIZE/sizeof(long)]; /*内核态的进程堆栈*/
4 };
/*线程描述符(linux4.5 x86架构)*/
/*typedef unsigned int __u32*/
struct thread_info {
struct task_struct *task; /* 存储进(线)程的信息 */
__u32 flags; /* 进程标记 */
__u32 status; /* 线程状态 */
__u32 cpu; /* current CPU */
mm_segment_t addr_limit;
unsigned int sig_on_uaccess_error:1;
unsigned int uaccess_err:1; /* uaccess failed */
};
进程在内核态运行时需要自己的堆栈信息, 因此linux内核为每个进程都提供了一个内核栈kernel stack;
内核还需要存储每个进程的PCB信息, linux内核是支持不同体系的的, 但是不同的体系结构可能进程需要存储的信息不尽相同, 这就需要我们实现一种通用的方式, 我们将体系结构相关的部分和无关的部门进行分离;
linux将内核栈和thread_info融合在一起, 组成一个联合体thread_union。(下图左块)
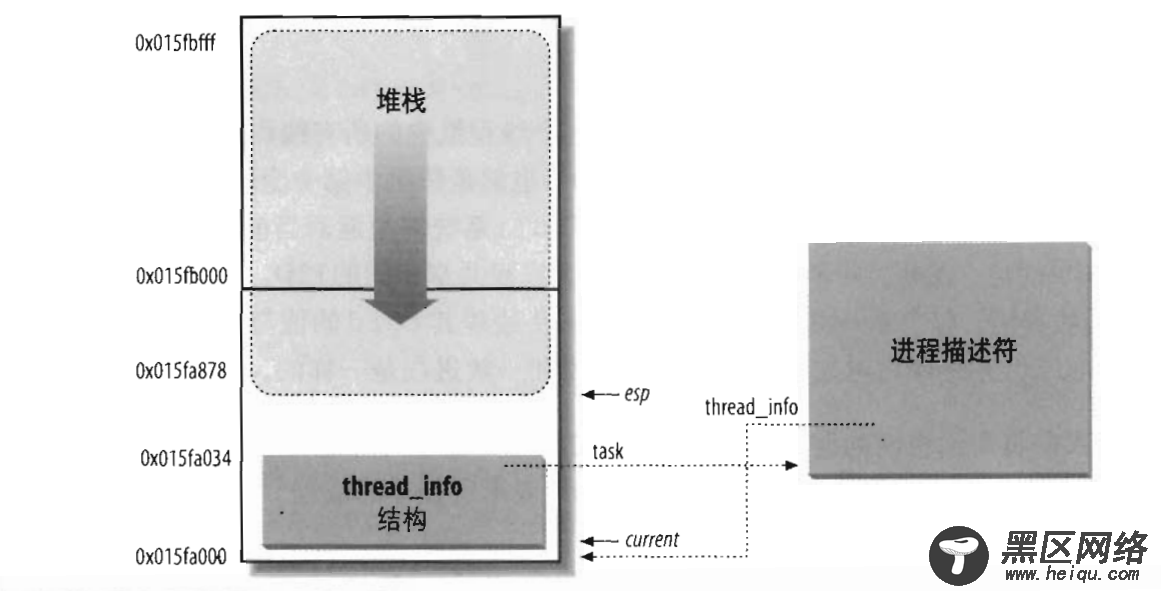
由上图(左大块为"进程内核栈", 右块为"进程描述符")所示,进程的内核栈是向下增长的,也就是栈底在高位地址,栈顶在低位地址,thread_info在进程内核栈的最低处。其中可总结出:
esp寄存器为CPU栈指针,用来存放栈顶单元的地址。当数据写入时,esp的值减少;
thread_info和内核栈虽然共用了thread_union结构, 但是thread_info大小固定, 存储在联合体的开始部分, 而内核栈由高地址向低地址扩展, 当内核栈的栈顶到达thread_info的存储空间时, 则会发生栈溢出(内核中有kstack_end函数判断);
系统的current指针指向了当前运行进程的thread_union(或者thread_info)的地址;
其中在早期的Linux内核中使用struct thread_info *thread_info,而之后的新版本(2.6.22后)中用进程task_struct中的stack指针指向了进程的thread_union(或者thread_info)的地址来代替thread_info指针,因为联合体中stack和thread_info都在起始地址, 因此可以很方便的转型:
#define task_thread_info(task) ((struct thread_info *)(task)->stack)
1.3进程标示符PID:
struct task_struct {
........
/* 进程ID,每个进程(线程)的PID都不同 */
pid_t pid;
/* 线程组ID,同一个线程组拥有相同的pid,与领头线程(该组中第一个轻量级进程)pid一致,保存在tgid中,线程组领头线程的pid和tgid相同 */
pid_t tgid;
/* 用于连接到PID、TGID、PGRP、SESSION哈希表 */
struct pid_link pids[PIDTYPE_MAX];
/*PID : 进程的ID(Process Identifier),对应pids[PIDTYPE_PID]
*TGID : 线程组ID(Thread Group Identifier),对应pids[PIDTYPE_TGID]
*PGRP : 进程组(Process Group),对应pids[PIDTYPE_PGID]
*SESSION : 会话(Session),对应pids[PIDTYPE_SID]
*/
........
};
PID就像我们学生的学号,每个人的身份证号一样,是独一无二的。而我们会有一个群体,比如同一个班级,同一个学校等,即有同一个组群,因此建立了TGID,用来将同一个组的PID串联起来。其中getpid()返回当前进程的tgid值而不是pid的值。
而在系统运行的时候,可能会建立非常非常多的进程,因此为了提高内核的查找效率,专门建立了四个hash表pids[PIDTYPE_TGID]、pids[PIDTYPE_TGID]、pids[PIDTYPE_PGID]、pids[PIDTYPE_SID]用来索引。