
当硬件处理能力不能按照摩尔定律垂直发展的时候,选择了水平发展,多核处理器已经广泛应用。未来随着技术的进一步发展,可能出现成百上千个处理核心,但现有的程序运行在多核心处理器上并不能得到较大性能的提升,主要的瓶颈在于程序本身的并发处理能力不强,不能够合理的利用多核心资源。
现有的处理方案是从软件入手,试图采用多线程,是程序在同一时间支持多个任务的计算,这种多线程的处理方案在处理器数目较少的情况下可以较为明显的提高应用性能,但我们更加青睐于由硬件实现的多线程处理模式,但这一领域至今没有很好的结果。
ForkJoin是Java7提供的原生多线程并行处理框架,其基本思想是将大人物分割成小任务,最后将小任务聚合起来得到结果。它非常类似于Hadoop提供的MapReduce框架,只是MapReduce的任务可以针对集群内的所有计算节点,可以充分利用集群的能力完成计算任务。ForkJoin更加类似于单机版的MapReduce。
即使不通过mapreduce,仅有应用程序本身进行任务的分解与合成也是可以的,但从实现难度上考虑,自己实现可能会带来较大规模的复杂度,因此程序员急需一种范式来处理这一类的任务。在处理多线程中已经有了如AKKA这样的基于ACTOR模型的框架,而FORKJOIN则是针对具有明显可以进行任务分割特性需求的实现。
其场景为:如果一个应用程序能够被分解成多个子任务,而且结合多个子任务的结果就能够得到最终的答案,那么它就适合使用FORK/JOIN模式来实现。
Fork/Join使用两个类完成以上两件事情:
· ForkJoinTask: 我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join的操作机制,通常我们不直接继承ForkjoinTask类,只需要直接继承其子类。
1. RecursiveAction,用于没有返回结果的任务
2. RecursiveTask,用于有返回值的任务
· ForkJoinPool:task要通过ForkJoinPool来执行,分割的子任务也会添加到当前工作线程的双端队列中,进入队列的头部。当一个工作线程中没有任务时,会从其他工作线程的队列尾部获取一个任务。
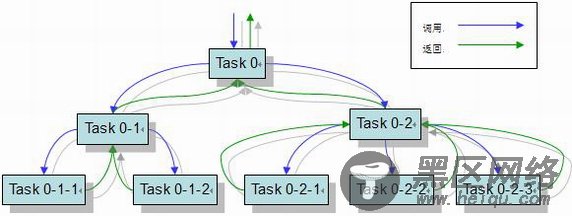
ForkJoin框架使用了工作窃取的思想(work-stealing),算法从其他队列中窃取任务来执行,其工作流图为:
[img][/img]
通过此算法降低线程等待和竞争。
下面是示例:
package com.inspur.jiyq.forkjoin.sum;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask<Integer>
{
private static final long serialVersionUID = -3611254198265061729L;
public static final int threshold = 2;
private int start;
private int end;
public CountTask(int start, int end)
{
this.start = start;
this.end = end;
}
@Override
protected Integer compute()
{
int sum = 0;
//如果任务足够小就计算任务
boolean canCompute = (end - start) <= threshold;
if(canCompute)
{
for (int i=start; i<=end; i++)
{
sum += i;
}
}
else
{
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end)/2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle+1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
//等待任务执行结束合并其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
//合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args)
{
ForkJoinPool forkjoinPool = new ForkJoinPool();
//生成一个计算任务,计算1+2+3+4
CountTask task = new CountTask(1, 100);
//执行一个任务
Future<Integer> result = forkjoinPool.submit(task);
try
{
System.out.println(result.get());
}
catch(Exception e)
{
System.out.println(e);
}
}
}
像这种求和以及排序的需求都可以通过FORKJOIN思想来实现,但在实际使用时还是要进行必要的性能测试来确认性能提升的幅度。