
2015年11月9日谷歌开源了人工智能平台TensorFlow,同时成为2015年最受关注的开源项目之一。经历了从v0.1到v0.12的12个版本迭代后,谷歌于2017年2月15日发布了TensorFlow 1.0 版本,并同时在美国加州山景城举办了首届TensorFlow Dev Summit会议。
TensorFlow 1.0及Dev Summit(2017)回顾和以往版本相比,TensorFlow 1.0 的特性改进主要体现在以下几个方面:
在TensorFlow 1.0版本发布的当天,谷歌公司还举办了TensorFlow 2017 DEV Summit。该主要包括以下几个方面的主题演讲:
XLA (TensorFlow, Compiled)编译技术 :介绍采用XLA技术最小化图计算执行时间和最大化利用计算资源,用于减少数据训练和模型结果推断时间。
Hands-on TensorBoard可视化技术:介绍了如何使用TensorBoard,以及TensorFlow图模型、训练数据的可视化等。
TensorFlow High-Level API:介绍了使用Layers, Estimators, and Canned Estimators High-Level API定义训练模型。
Integrating Keras & TensorFlow: 介绍了如何在TensorFlow中使用Keras API进行模型定义及训练。
TensorFlow at DeepMind:介绍了在DeepMind中使用TensorFlow平台的典型案例,包括AlphaGo等应用。
Skin Cancer Image Classification:介绍了斯坦福医学院使用TensorFlow分类皮肤癌照片,用于医学诊断。
Mobile and Embedded TensorFlow:介绍了如何把TensorFlow模型运行在移动终端、嵌入式设备,包括安卓,iOS等系统。
Distributed TensorFlow:系统性地介绍了分布式TensorFlow的相关技术,以及如何应用于大规模模型训练。
TensorFlow Ecosystem:讲解了TensorFlow的生态系统,包括生成训练数据,分布式运行TensorFlow和serving models的产品化流程。
Serving Models in Production with TensorFlow Serving:系统性讲解了如何在生产环境中应用TensorFlow Serving模型。
ML Toolkit:介绍了TensorFlow的机器学习库,如线性回归,KMeans等算法模型的使用。
Sequence Models and the RNN API:介绍了如何构建高性能的sequence-to-sequence模型,以及相关API。
Wide & Deep Learning: 介绍了如何结合Wide模型和Deep模型构建综合训练模型。
Magenta,Music and Art Generation:使用增强型深度学习模型生成音乐声音和艺术图片。
Case Study,TensorFlow in Medicine - Retinal Imaging:使用TensorFlow机器学习平台对医学视网膜图片进行分类,辅助医学诊断。
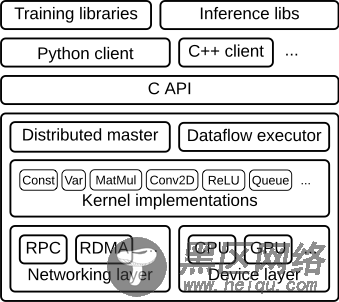
TensorFlow系统架构TensorFlow作为分布式机器学习平台,主要架构如下图所示。RPC和RDMA为网络层,主要负责传递神经网络算法参数。CPU和GPU为设备层,主要负责神经网络算法中具体的运算操作。Kernel为TensorFlow中算法操作的具体实现,如卷积操作,激活操作等。Distributed Master用于构建子图;切割子图为多个分片,不同的子图分片运行在不同的设备上;Master还负责分发子图分片到Executor/Work端。Executor/Work在设备(CPUs,GPUs,etc.)上,调度执行子图操作;并负责向其它Worker发送和接收图操作的运行结果。C API把TensorFlow分割为前端和后端,前端(Python/C++/Java Client)基于C API触发TensorFlow后端程序运行。Training libraries和Inference libs是模型训练和推导的库函数,为用户开发应用模型使用。
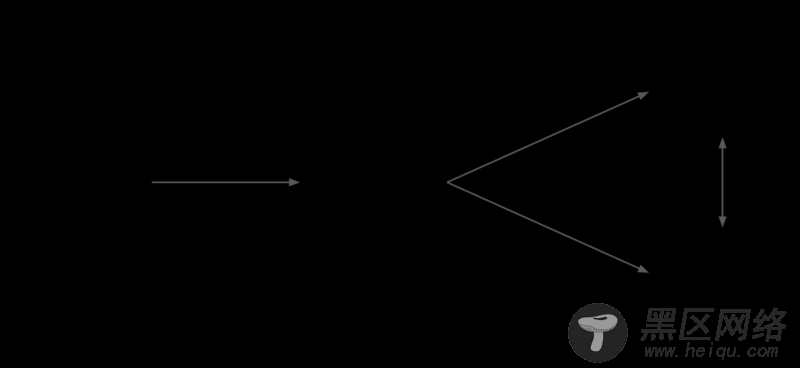
下图为Client、Master及Worker的内部工作原理。"/job:worker/task:0" 和 "/job:ps/task:0" 表示worker中的执行服务。"job:ps"表示参数服务器,用于存储及更新模型参数。"job:worker"用于优化模型参数,并发参数发送到参数服务器上。Distributed Master和Worker Service只存在于分布式TensorFlow中。单机版本的TensorFlow实现了Local的Session,通过本地进程的内部通讯实现上述功能。
用户编写TensorFlow应用程序生成计算图,Client组件会创建Session,并通过序列化技术,发送图定义到Distributed Master组件。下图中,Client创建了一个 s+=w*x+b的图计算模型。

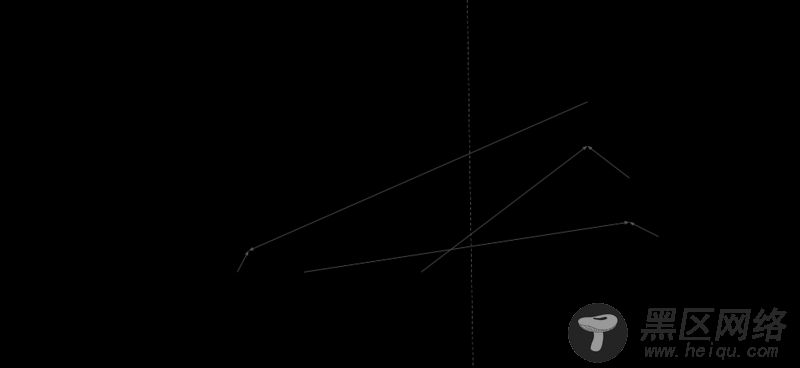
当Client触发Session运算的时候,Maser构建将要运行的子图。并根据设备情况,切割子图为多个分片。下面为Master构建的运行子图:

接着切割子图,把模型参数分组在参数服务器上,图计算操作分组在运算Worker上。下图为一种可行的图切割策略:
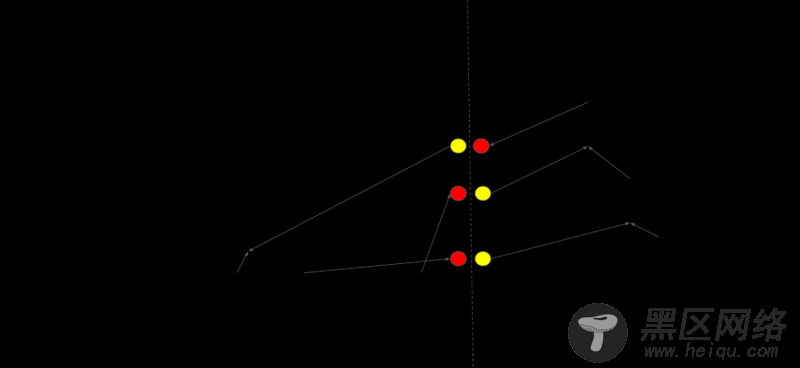
Distributed Master会根据模型参数的分区情况进行切割边,在Task间插入发送和接收Tensor信息的通信节点,如下图所示:
接着Distributed Master通过RegisterGraph方法发送子图分片给Task,如下图所示:
