
对于延迟实验而言,客户端会发起足够少量的操作,从而避免在服务器中发生排队。从 1 个副本的实验中,提交等待大约是 5ms,Paxos 延迟大约是 9ms。随着副本数量的增加, 延迟大约保持不变,只具有很少的标准差,因为在一个组的副本内,Paxos 会并行执行。随着副本数量的增加,获得指定投票数量的延迟对一个 slave 副本的慢速度不会很敏感。
对于吞吐量的实验而言,客户端发起足够数量的操作,从而使得 CPU 处理能力达到饱和。快照读操作可以在任何足够新的副本上进行,因此,快照读的吞吐量会随着副本的数量增加而线性增加。单个读的只读事务,只会在领导者上执行,因为,时间戳分配必须发生在领导者上。只读事务吞吐量会随着副本数量的增加而增加,因为有效的 spanserver 的数量会增加:在这个实验的设置中,spanserver 的数量和副本的数量相同,领导者会被随机分配到不同的 zone。写操作的吞吐量也会从这种实验设置中获得收益(副本从 3 变到 5 时写操作吞吐量增加了,就能够说明这点),但是,随着副本数量的增加,每个写操作执行时需要完 成的工作量也会线性增加,这就会抵消前面的收益。
表 4 显示了两阶段提交可以扩展到合理数量的参与者:它是对一系列实验的总结,这些实验运行在 3 个 zone 上,每个 zone 具有 25 个 spanserver。扩展到 50 个参与者,无论在平均值还是第 99 个百分位方面,都是合理的。在 100 个参与者的情形下,延迟开发明显增加。
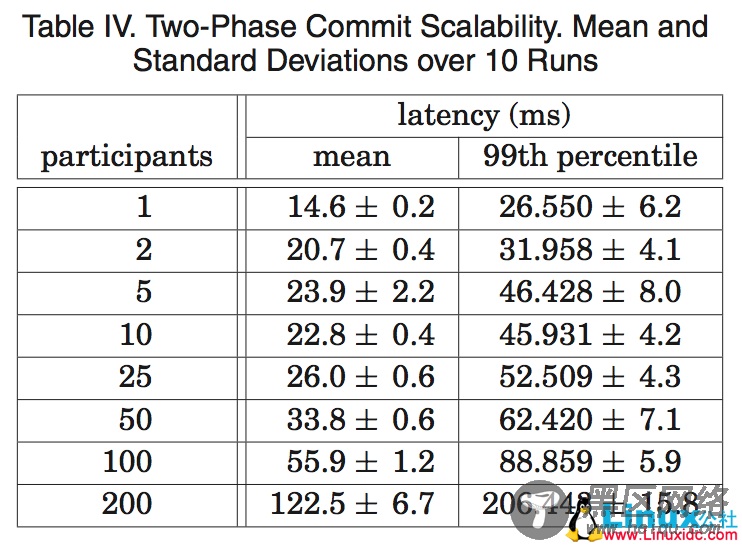
图 5 显示了在多个数据中心运行 Spanner 时的可用性方面的收益。它显示了三个吞吐量实验的结果,并且存在数据中心失败的情形,所有三个实验结果都被重叠放置到一个时间轴 上。测试用的 universe 包含 5 个 zone Zi,每个 zone 都拥有 25 个 spanserver。测试数据库被 分片成 1250 个 Paxos 组,100 个客户端不断地发送非快照读操作,累积速率是每秒 50K 个读操作。所有领导者都会被显式地放置到 Z1。每个测试进行 5 秒钟以后,一个 zone 中的所有服务器都会被“杀死”:non-leader 杀掉 Z2,leader-hard 杀掉 Z1,leader-soft 杀掉 Z1,但是,它会首先通知所有服务器它们将要交出领导权。
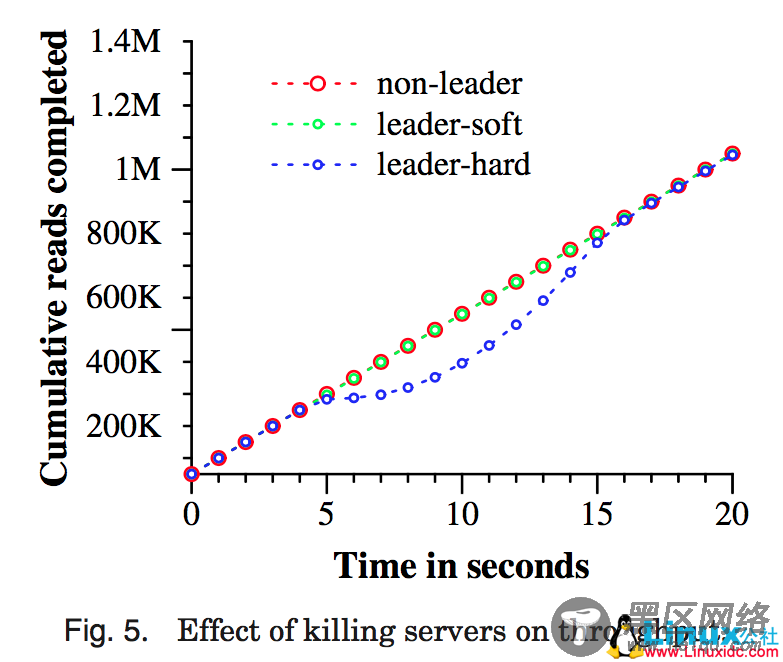
杀掉 Z2 对于读操作吞吐量没有影响。杀掉 Z1,给领导者一些时间来把领导权交给另一个 zone 时,会产生一个小的影响:吞吐量会下降,不是很明显,大概下降 3-4%。另一方面,没有预警就杀掉 Z1 有一个明显的影响:完成率几乎下降到 0。随着领导者被重新选择,系统的吞吐量会增加到大约每秒 100K 个读操作,主要是由于我们的实验设置:系统中有额外的能力,当找不到领导者时操作会排队。由此导致的结果是,系统的吞吐量会增加直到到达 系统恒定的速率。
我们可以看看把 Paxos 领导者租约设置为 10ms 的效果。当我们杀掉这个 zone,对于这 个组的领导者租约的过期时间,会均匀地分布到接下来的 10 秒钟内。来自一个死亡的领导者的每个租约一旦过期,就会选择一个新的领导者。大约在杀死时间过去 10 秒钟以后,所有的组都会有领导者,吞吐量就恢复了。短的租约时间会降低服务器死亡对于可用性的影响, 但是,需要更多的更新租约的网络通讯开销。我们正在设计和实现一种机制,它可以在领导者失效的时候,让 slave 释放 Paxos 领导者租约。
5.3 TrueTime关于 TrueTime,必须回答两个问题: ε 是否就是时钟不确定性的边界? ε 会变得多糟糕? 对于第一个问题,最严峻的问题就是,如果一个局部的时钟漂移大于 200us/sec,那就会破坏 TrueTime 的假设。我们的机器统计数据显示,坏的 CPU 的出现概率要比坏的时钟出现概率大 6 倍。也就是说,与更加严峻的硬件问题相比,时钟问题是很少见的。由此,我们也相信,TrueTime 的实现和 Spanner 其他软件组件一样,具有很好的可靠性,值得信任。