开发团队和 SRE 团队对上述事件很感兴趣,以了解特定应用程序或多个应用程序在网站上发生错误的数量,这些错误可能会造成很大影响。将每分钟几百万个事件实时收集到集中式存储并对其进行处理,会带来一系列事关准确性、速度、可靠性和弹性方面的挑战。
扩展
监控事件在整个集群中,以每秒 800 万个事件的速度生成,在高峰流量时平均为每秒 1000 万个事件,这些来自 5000 多个应用程序。监控事件需要跨多个维度进行切片和切块,例如应用程序名称、应用程序类型、操作名称、错误状态、运行应用程序的构建、主机等。所有数据都应以近实时服务级别协议进行汇总和提供。共有 11 个固定维度,所有维度的纬度值基数在 140 万到 200 万个唯一组合之间。
我们的 Druid 集群部署在多个可用区域,以实现高可用性,并保持每个数据中心的每个示例保留 2 个副本。这使得我们可以在 2 个数据中心共有 4 个副本可用。每个数据中心都有几百个中间管理器、2 个统治 + 协调(Overlord+Coordinator)节点,15 个代理节点和 80 个历史节点。
峰值数据流量如下图所示。
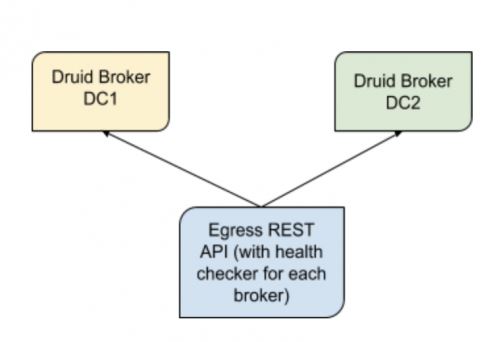
出口设计
数据出口的设计目标是保持数据的高可用性。Druid 代理前面的一层被设计用于查询 Druid 的数据,以确定每个数据中心的健康状况。我们希望两个数据中心的运行状况始终保持在最佳状态,且高度可用。如果任何数据中心出现任何数据丢失的情况,出口会切换到数据质量更好的集群。
我们每分钟从每个集群中获取事件计数,以确定两个集群是否具有相似的数据(偏差小于集群之间的事件计数差异的 0.5%)。如果偏差过大,我们则选择事件计数更好的集群。计算每分钟进行一次,我们继续更新集群的运行状况,以确定能够在一段时间内为数据提供服务的最佳集群。如果检测到任何数据丢失,我们还会标记集群,这样就不会有任何查询进入有问题的集群的代理节点进行查询。
我们支持早期版本的 Druid 所支持的各种粒度(1 分钟、1 刻钟、1 小时、1 天),这取决于查询数据的时间长度。这种粒度的选择是自动进行的。在需要时,由于查询的数据量很大,可以强制粒度以更长的时间段获取更细粒度的数据,但要付出响应时间的代价。
结论
对于站点监控和事件跟踪而言,带有需要实时或近实时聚合的高基数数据的用例,对于像 eBay 这样的大型生态系统做出数据驱动的决策至关重要。像 Druid 这样的分析存储可以提供洞见的能力,从监控的角度来说非常有价值,也很重要;很多团队和开发人员都依赖维护 eBay 客户系统的可用性和可靠性。