1、问题:
2、排查:
2.1 vmstat
2.2 iostat
2.3 iotop
3、最后的话:另辟蹊径
最近在做日志的实时同步,上线之前是做过单份线上日志压力测试的,消息队列和客户端、本机都没问题,但是没想到上了第二份日志之后,问题来了:
集群中的某台机器 top 看到负载巨高,集群中的机器硬件配置一样,部署的软件都一样,却单单这一台负载有问题,初步猜测可能硬件有问题了。
同时,我们还需要把负载有异常的罪魁祸首揪出来,到时候从软件、硬件层面分别寻找解决方案。

从 top 中可以看到 load average 偏高,%wa 很高,%us 偏低:
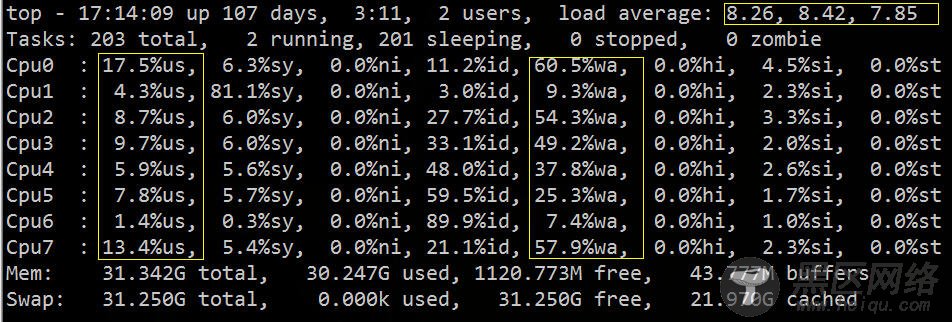
从上图我们大致可以推断 IO 遇到了瓶颈,下面我们可以再用相关的 IO 诊断工具,具体的验证排查下。
PS:如果你对 top 的用法不了解,请参考:Linux 系统监控、诊断工具之 top命令详解
常用组合方式有如下几种:
用vmstat、sar、iostat检测是否是CPU瓶颈
用free、vmstat检测是否是内存瓶颈
用iostat、dmesg 检测是否是磁盘I/O瓶颈
用netstat检测是否是网络带宽瓶颈
2.1 vmstatvmstat命令的含义为显示虚拟内存状态(“Viryual Memor Statics”),但是它可以报告关于进程、内存、I/O等系统整体运行状态。
它的相关字段说明如下:
Procs(进程)
r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
b: 等待IO的进程数量,也就是处在非中断睡眠状态的进程数,展示了正在执行和等待CPU资源的任务个数。当这个值超过了CPU数目,就会出现CPU瓶颈了
Memory(内存)
swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
free: 空闲物理内存大小。
buff: 用作缓冲的内存大小。
cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
Swap(交换区)
si: 每秒从交换区写到内存的大小,由磁盘调入内存。
so: 每秒写入交换区的内存大小,由内存调入磁盘。
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
IO(输入输出)
(现在的Linux版本块的大小为1kb)
bi: 每秒读取的块数
bo: 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
system(系统)
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU
(以百分比表示)
us: 用户进程执行时间百分比(user time)。us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
sy: 内核系统进程执行时间百分比(system time)。sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
wa: IO等待时间百分比。wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
id: 空闲时间百分比
从 vmstat 中可以看到,CPU大部分的时间浪费在等待IO上面,可能是由于大量的磁盘随机访问或者磁盘的带宽所造成的,bi、bo 也都超过 1024k,应该是遇到了IO瓶颈。
2.2 iostat下面再用更加专业的磁盘 IO 诊断工具来看下相关统计数据。
它的相关字段说明如下:
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
可以看到两块硬盘中的 sdb 的利用率已经 100%,存在严重的 IO 瓶颈,下一步我们就是要找出哪个进程在往这块硬盘读写数据。
2.3 iotop根据 iotop 的结果,我们迅速的定位到是 flume 进程的问题,造成了大量的 IO wait。
但是在开头我已经说了,集群中的机器配置一样,部署的程序也都 rsync 过去的一模一样,难道是硬盘坏了?
这得找运维同学来查证了,最后的结论是: