spark通过kafka-appender指定日志输出到kafka引发的死(3)
到这里,已经确定是死锁,导致driver一开始就运行停滞,那么当然无法提交executor执行。
具体的死锁稍后分析,先考虑如何解决。从感性认识看,似乎只要不让kafka-client的日志也输出到kafka即可。实验后,发现果然如此:如果只输出org.apache.spark的日志就可以正常执行。
根因分析
从stack的结果看,造成死锁的是如下两个线程:
- kafka-client内部的网络线程spark
- 主入口线程
两个线程其实都是卡在打日志上了,观察堆栈可以发现,两个线程同时持有了同一个log对象。而这个log对象实际上是kafka-appender。而kafka-appender本质上持有kafka-client,及其内部的Metadata对象。log4j的doAppend为了保证线程安全也用synchronized修饰了:
public
synchronized
void doAppend(LoggingEvent event) {
if(closed) {
LogLog.error("Attempted to append to closed appender named ["+name+"].");
return;
}
if(!isAsSevereAsThreshold(event.level)) {
return;
}
Filter f = this.headFilter;
FILTER_LOOP:
while(f != null) {
switch(f.decide(event)) {
case Filter.DENY: return;
case Filter.ACCEPT: break FILTER_LOOP;
case Filter.NEUTRAL: f = f.next;
}
}
this.append(event);
}
于是事情开始了:
- main线程尝试打日志,首先进入了synchronized的doAppend,即获取了
kafka-appender的锁 kafka-appender内部需要调用kafka-client发送日志到kafka,最终调用到Thread 20137展示的,运行到Metadata.awaitUpdate(也是个synchronized方法),内部的wait会尝试获取metadata的锁。(详见https://github.com/apache/kaf...)- 但此时,kafka-producer-network-thread线程刚好进入了上文提到的打
Cluster ID这个日志的这个阶段(update方法也是synchronized的),也就是说kafka-producer-network-thread线程获得了metadata对象的锁 - kafka-producer-network-thread线程要打印日志同样执行synchronized的doAppend,即获取了
kafka-appender的锁
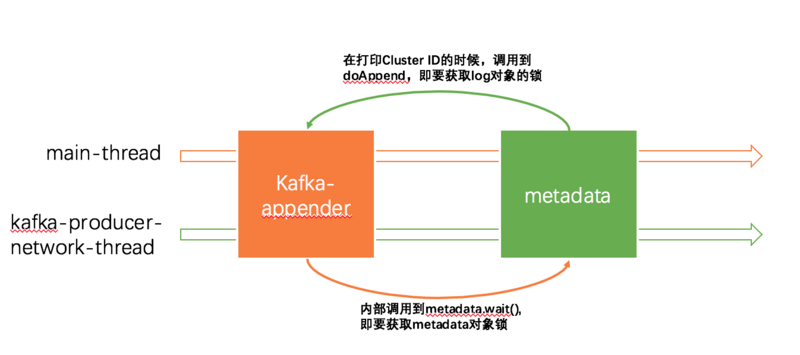
上图main-thread持有了log对象锁,要求获取metadata对象锁;kafka-producer-network-thread持有了metadata对象锁,要求获取log对象锁于是造成了死锁。
总结
到此这篇关于spark通过kafka-appender指定日志输出到kafka引发的死锁的文章就介绍到这了,更多相关spark指定日志输出内容请搜索黑区网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持黑区网络!