
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master.hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master.hadoop:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master.hadoop:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master.hadoop:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master.hadoop:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.hadoop</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
</configuration>
7、配置/home/hadoop/hadoop-2.9.0/etc/hadoop目录下hadoop.env.sh、yarn-env.sh的JAVA_HOME
取消JAVA_HOME的注释,设置为 export JAVA_HOME=/home/java/jdk1.8.0_11
8、配置/home/hadoop/hadoop-2.9.0/etc/hadoop目录下的slaves,删除默认的localhost,添加2个slave节点:
slave1.hadoop
slave2.hadoop
9、将master服务器上配置好的Hadoop复制到各个节点对应位置上,通过scp传送:
scp -r /home/hadoop 192.168.10.129:/home/
scp -r /home/hadoop 192.168.10.130:/home/
10、启动hadoop。在master节点启动hadoop服务,各个从节点会自动启动,进入/home/hadoop/hadoop-2.9.0/sbin/目录,hadoop的启动和停止都在master上进行;
a、初始化,输入命令:hdfs namenode -format
b、启动命令:start-all.sh

c、输入jps命令查看相关信息,master上截图如下:
d、slave节点上输入jps查看:

e、停止命令:stop-all.sh
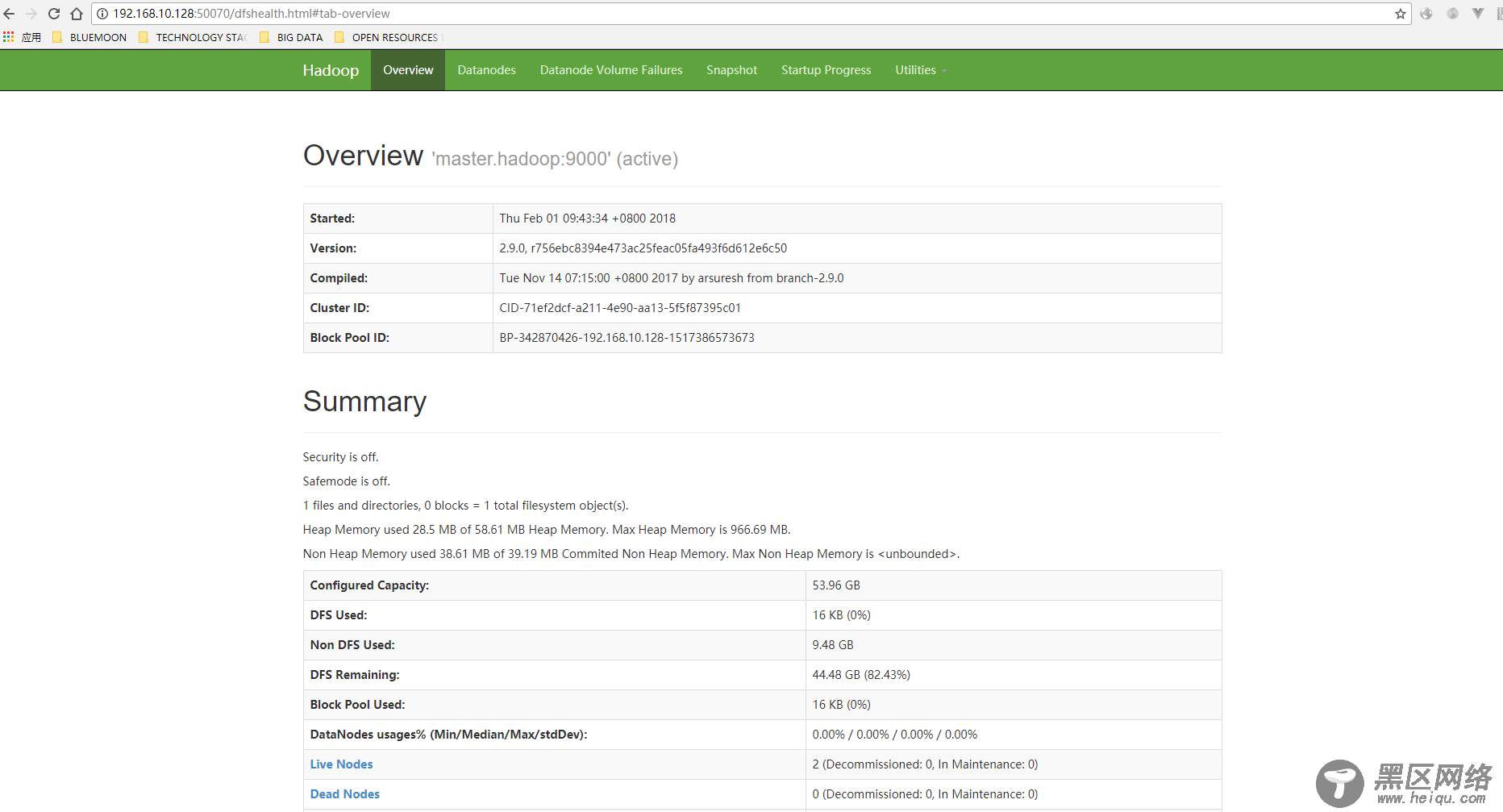
11、访问,输入:50070,看到如下界面:
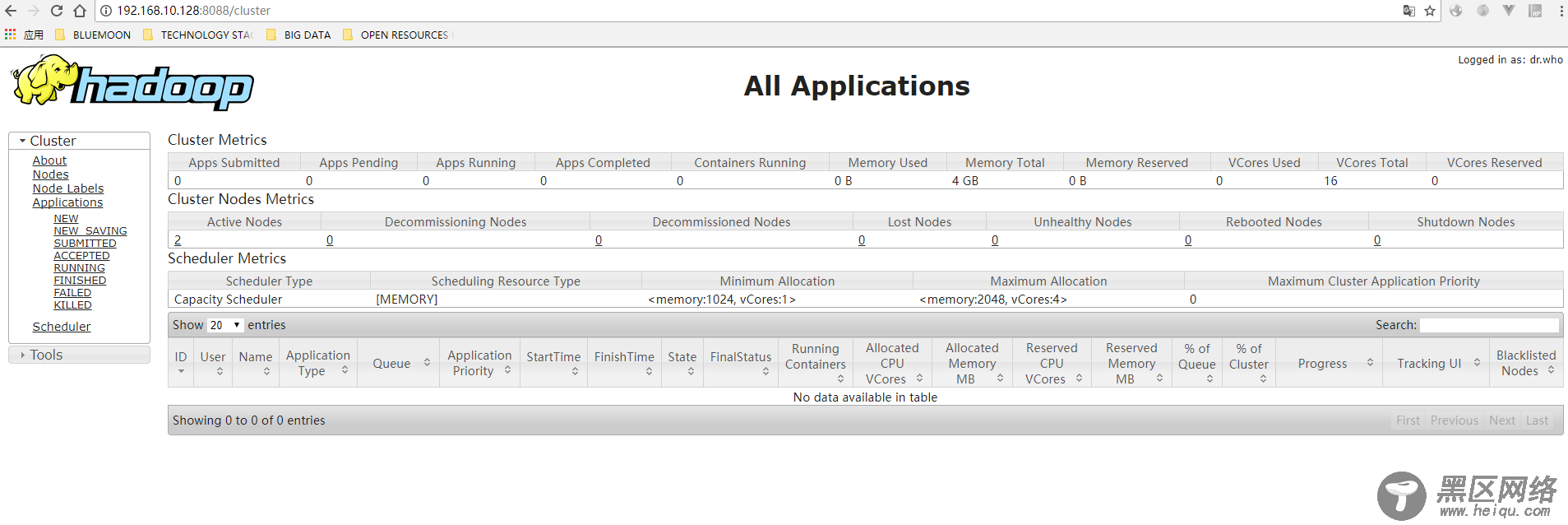
输入:8088,看到如下界面:
好了。如果以上都成功,那么基本上完成了hadoop集群的搭建。