Linux内核实现了数据包的队列机制,配合多种不同的排队策略,可以实现完美的流量控制和流量整形(以下统称流控)。流控可以在两个地方实现,分别为egress和ingress,egress是在数据包发出前的动作触发点,而ingress是在数据包接收后的动作触发点。Linux的流控在这两个位置实现的并不对称,即Linux并没有在ingress这个位置实现队列机制。那么在ingress上就几乎不能实现流控了。
虽然使用iptables也能模拟流控,但是如果你就是想用真正的队列实现流控的话,还真要想想办法。也许,就像电子邮件的核心思想一样,你总是能完美控制发送,却对接收毫无控制力,如果吸收了这个思想,就可以理解ingress队列流控的难度了,然而,仅仅是也许而已。
Linux在ingress位置使用非队列机制实现了一个简单的流控。姑且不谈非队列机制相比队列机制的弊端,仅就ingress的位置就能说明我们对它的控制力几乎为0。ingress处在数据进入IP层之前,此处不能挂接任何IP层的钩子,Netfilter的PREROUTING也在此之后,因此在这个位置,你无法自定义任何钩子,甚至连IPMARK也看不到,更别提关联socket了,因此你就很难去做排队策略,你几乎只能看到IP地址和端口信息。
一个现实的ingress流控的需求就是针对本地服务的客户端数据上传控制,比如上传大文件到服务器。一方面可以在底层释放CPU压力,提前丢掉CPU处理能力以外的数据,另一方面,可以让用户态服务的IO更加平滑或者更加不平滑,取决于策略。
既然有需求,就要想法子满足需求。目前我们知道的是,只能在egress做流控,但是又不能让数据真的outgoing,另外,我们需要可以做很多策略,这些策略远不是仅由IP,协议,端口这5元组可以给出。那么一个显而易见的方案就是用虚拟网卡来完成,图示如下:
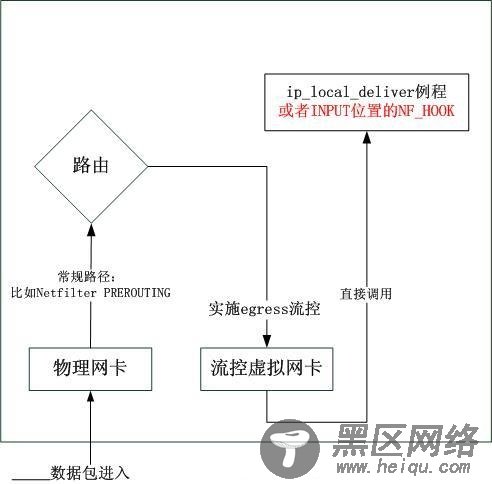
以上的原理图很简单,但是实施起来还真有几个细节。其中最关键是路由的细节,我们知道,即使是策略路由,也必须无条件从local表开始查找,在目标地址是本机情况下,如果希望数据按照以上流程走的话,就必须将该地址从local表删除,然而一旦删除,本机将不再会对该地址回应ARP请求。因此可以用几个方案:
1.使用静态ARP或者使用ebtables更改ARP,或者使用arping主动广播arp配置;
2.使用一个非本机的地址,然后修改虚拟网卡的xmit函数,内部使其DNAT成本机地址,这就绕开了local表的问题。
不考虑细节,仅就上述原理图讨论的话,你可以在常规路径的PREROUTING中做很多事情,比如使用socket match关联socket,也可以使用IPMARK。
下面,我们就可以按照上述图示,实际实现一个能用的。首先先要实现一个虚拟网卡。仿照loopback接口做一个用于流控的虚拟接口,首先创建一个用于ingress流控的虚拟网卡设备
dev = alloc_netdev(0, "ingress_tc", tc_setup);
然后初始化其关键字段
static const struct net_device_ops tc_ops = {
.ndo_init = tc_dev_init,
.ndo_start_xmit= tc_xmit,
};
static void tc_setup(struct net_device *dev)
{
ether_setup(dev);
dev->mtu = (16 * 1024) + 20 + 20 + 12;
dev->hard_header_len = ETH_HLEN; /* 14 */
dev->addr_len = ETH_ALEN; /* 6 */
dev->tx_queue_len = 0;
dev->type = ARPHRD_LOOPBACK; /* 0x0001*/
dev->flags = IFF_LOOPBACK;
dev->priv_flags &= ~IFF_XMIT_DST_RELEASE;
dev->features = NETIF_F_SG | NETIF_F_FRAGLIST
| NETIF_F_TSO
| NETIF_F_NO_CSUM
| NETIF_F_HIGHDMA
| NETIF_F_LLTX
| NETIF_F_NETNS_LOCAL;
dev->ethtool_ops = &tc_ethtool_ops;
dev->netdev_ops = &tc_ops;
dev->destructor = tc_dev_free;
}
接着构建其xmit函数