通过以上分析可以看得出,Linux共享内核地址空间的机制设计得非常精巧,但是却付出了巨大的代价。Linux第一次面临了对画出的饼感到不满的情况!1G的地址空间实在太小了。
线性映射空间的不足:896M的一一映射空间中充满了必须物理内存连续的映射,比如内核代码中的静态数组之类的,典型的就是mem_map,即page数组,它会随着物理内存的增加而增加,会占据巨大的一一线性映射空间。另外,task_struct结构体也是一笔开销,每一个进程还要有一个页目录,若干页表等,这些都是线性空间的开销,如果线性空间被占满了,其它必需使用线性空间的该怎么办?只能PANIC。
动态空间的不足:所有的内核模块中的代码和数据都需要虚拟地址,而这些地址处(挤)在128M不到的地址空间中,不说也知道了吧,你可以试一下调用一下vmalloc(...),然后再加载一个模块...
永久映射和临时映射的不足:这个空间比动态映射空间还要小得多。
这就是共享地址空间的代价,如果使用4G/4G模式,当然更好,但是难道在3G/1G模式中就没有办法了吗?彻底解决是不可能的,管理毕竟是需要付出代价的。于是设计精巧的数据结构也成了一个解决之道,另外,将一些不必非要在线性空间的数据结构移出去,让它们从高端内存即大于896M的物理地址处分配,然后不映射任何虚拟地址,因此也就不占据虚拟地址空间的席位,只有等待真正读写它们的时候,再映射到永久或临时的空间里,得到一个虚拟地址,读写该虚拟地址即可!HIGHPTE这个编宏就是一个实现实例!
3.3.总结
Linux进程的虚拟地址空间中,最上面1G的内核空间是共享的,Linux采用了更加直接的方式敷衍了MMU,即将这部分地址空间一一线性映射到了物理内存的前面896M空间,同时保留了128M的其它映射空间。对于每一个进程而言,其MMU关键机构页表并不直接映射到虚拟内存空间,虽然由于一一线性映射的缘故,知道了其page下标后,它确实可以直接被访问,访问方式为:
((pte_t *)page_address(pmd_page(*(dir))) + pte_index(address))
page_address对于非高端物理内存会直接返回lowmem_page_address:
static inline void *lowmem_page_address(struct page *page)
{
return __va(page_to_pfn(page) << PAGE_SHIFT);
}
而__va宏说明了什么是一一线性映射:
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
虽然费了这么大的周折,实际上定位一个页表的虚拟地址是很简单的。如果这些页表被分配在了前896M的物理内存,MMU会将其一一映射到3G至3G+896M的虚拟地址空间,导致该空间被消耗。因此更加正常的方式是在大于896M的高端内存分配页表页面,由于不再是一一映射,那么它就是一个游离的页面了,需要设置页表项时,必须将页表物理页面映射到PageMap区:
#if defined(CONFIG_HIGHPTE)
#define pte_offset_map(dir, address) \
((pte_t *)kmap_atomic(pmd_page(*(dir)),KM_PTE0) + pte_index(address))
...
设置页表项完毕后,随即释放掉:
#define pte_unmap(pte) kunmap_atomic(pte, KM_PTE0)
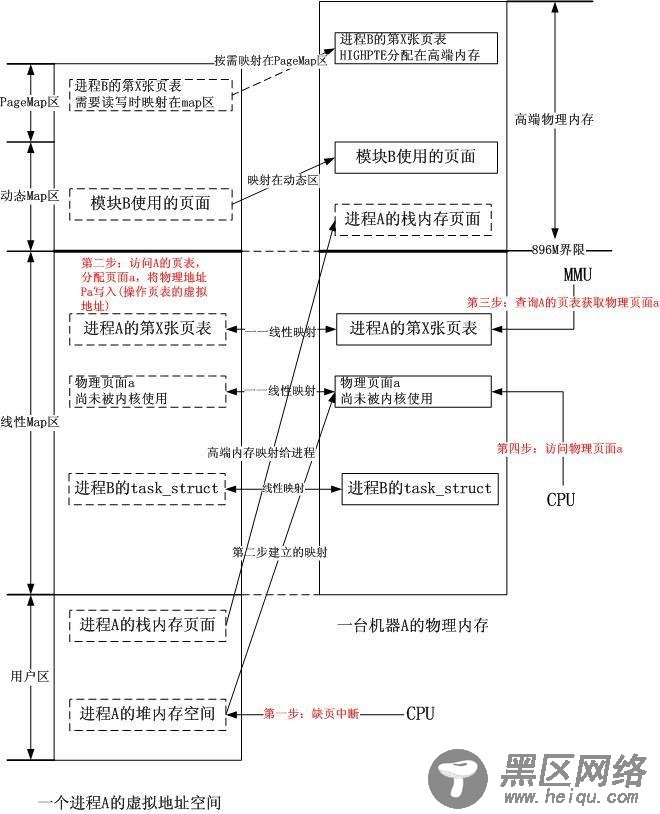
3.4.图示
是时候给出一幅图了。我一直没有画图的原因在于这部分的图已经很多了,实际上Linux的映射方式和Windows一样简单,不知道为什么很多人都纠结于诸如高端内存的概念,像纠结与Windows自映射一样痛苦不堪,实际上它们都是虚拟地址空间布局方式的一种自然而然的结果,并没有那么多为什么。在给出我自己的图之前,再简略回答一个问题。
很多人都在问,如果我的物理内存条只有512M,那么高端内存在哪里?很简单如果只有512M内存,那么就没有高端内存!Linux内核地址空间的映射同样不变,所有的512M物理地址全部线性映射到虚拟地址的3G+512M这个空间,所有的用户进程,内核模块等的物理内存也从这个512M的物理内存中分配,只要内核不在引用的页面都可以分配(实际上还保留着一一线性映射),然后这些页面可以被映射在不同的地方,小于3G的用户空间,VMALLOC的动态空间,或者PageMap空间。有一个疑问就是,此时的896M限制还有吗?也就是说,既然内核虚拟地址空间只能一一线性映射到512M,那么从地址空间的3G+512M到3G+896M之间的空洞怎么用?答案很明确,全都给VMALLOC的动态区域使用,因为1G的地址空间中,最下面的是一一映射空间,大小最大896M,最上面是PageMap空间,大小固定,处在中间的VMALLOC理所当然可以吃掉由于物理内存不到896M而被空出的虚拟地址空间。这就是说物理内存小于896M的时候,你可以使用更多的VMALLOC空间,注意,是虚拟的!唯一的好处,那就是你可以搜罗大量不连续的物理内存,将其映射到很大的VMALLOC空间中去,可是你又能搜罗多少呢?VMALLOC空间可是常驻的,所有的页面必须从实际的物理内存中获取,而你的实际物理内存只有896M不到!哈哈,是不是有种被耍的感觉!
好了,该上图了!
4.一些感悟
很多人希望我能提供一些学习网络或者Linux内核的书,不得不说的是,学习这些东西真的是不需要书的,一份提纲,一些想法以及随时想付诸实践的冲动即可。也许我已经度过了读书的阶段,但是不得不说的是,从来我都不认为从书上可以学得技术。技术是练出来的,经验是攒出来的,书,只是一个提纲,它代表了别人的想法,你读它,要么你很赞同他的想法,要么你情愿被洗脑!
如果你把书看得太重要,那就大错特错了,我深有感悟!平时喜欢历史,喜欢欧洲史,喜欢希腊罗马,但是从来啃不动大部头的《罗马帝国衰亡史》,虽然有藏书,但几乎不读,于是买一些入门级的,科普级的,比如《罗马人的故事》等(日本人写的一般都很易懂),最近我有点膨胀,于是只要是欧洲历史都会买来读,反正地铁上要一个多小时。但是我发现越来越混乱了,以前曾经想写几篇罗马历史的评论,现在因为读了太多的书只有搁置!以前还有自己的思想,现在由于读书太多被充斥了...思想总是合不拢。想放弃那些新买来的历史书,却又舍不得!这也许就是读书人的悲哀吧。
为何人们要就事论事呢?为何不能把一些朴实又普世的经验用于一切呢?编程难道就是这么的排外吗?一些历史的,物理的,人文的经验难道就不能用于编程算法吗?林奈分类去死吧,这世界本来就是融会贯通的,不存在什么分类,只是人们的无知才将所有人分为搞历史的,搞IT的,搞房地产的...其实所有人都一样!
周末,幸福的时光,学习国学,学习拉洋片,学习吹糖人,学习育儿,学习...但不读书!