
该方案是利用AIX LVM和IBM HACMP软件创建并行的LV镜像作为OCR、Votedisk的第3张盘,实践证明这种方案是不可行的!服务器一旦断电,可能导致LV镜像磁盘与其它两个磁盘的数据不同步,Clusterware无法正常的启动。原因在于在系统层面利用LVM做的软数据镜像的块大小为512KB,而OCR和Votedisk磁盘的块大小为1MB(默认AU=1M),且OCR和Votedisk磁盘使用的都是字符设备,不走缓存,所以在某一时间点,Oracle自身维护的两个磁盘和利用操作系统LVM同步的第3个磁盘的数据可能不一致。
为了实现Oracle RAC双存储的安全性,需要第3个存储提供一个OCR、Votedisk磁盘;我们可以看到,即使是1/8配置的Oracle Exadata服务器,存储也是3个,这跟OCR、Votedisk磁盘的个数有一定的关系。由此可见,不管是AIX平台还是其他的平台,都不应该利用系统层面的软镜像构成OCR、Votedisk磁盘,OCR、Votedisk的所有磁盘都应来自存储本身。
最近几天为客户实施了一套Oracle Database 11.2.0.3 RAC for AIX 6.1.7,这次实施使用了双存储,使用到了IBM HACMP软件,所以遇到了一些新的问题,在此做出记录。
客户环境如下:
服务器:IBM P740
操作系统:IBM AIX 6.1.7
HA软件:IBM POWERHA 6.1
Oracle软件:Oracle Database RAC 11.2.0.3
这套RAC有个最大的特点在于它有两个相同的存储阵列,除了自身的RAID外,还利用ASM的Failgroup完成存储之间的镜像。方案需要达到的效果是当掉任何一个存储都不能对RAC的正常运行带来影响,并且之后能够恢复双存储的正常工作,消除RAC的存储单点故障。
服务器和存储连接的拓扑图如下: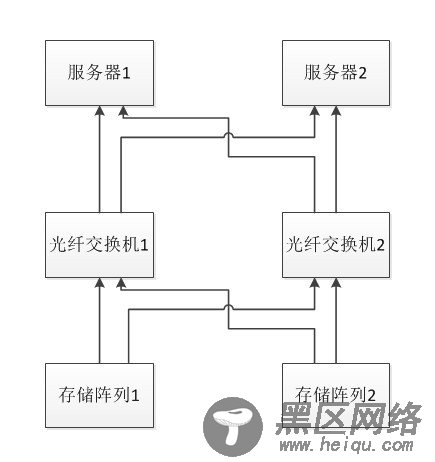
作为存储数据库数据文件的ASM实现存储之间的镜像非常的容易(利用ASM磁盘组的Failgroup实现),这套方案的难点在于如何使用两套存储来保障RAC集群软件的高可用运行。
从11gR2开始,RAC集群软件的安装通常都使用ASM作为存储方式,作为集群软件的ASM磁盘组,要求Normal冗余级别至少3个磁盘,High冗余级别至少5个磁盘(实践证明过多的磁盘对于votedisk来说没有任何意义,只能也必须是这个数目的磁盘存在),Normal情况下允许1个磁盘的丢失,High允许2个磁盘的丢失。如果使用Normal冗余级别必定有两个磁盘在一个存储上,使用High冗余级别必定有3个磁盘在一个存储上,一旦较多磁盘的存储挂掉整个RAC立马停掉,RAC所有的节点最终都会被重启,这样就没有达到RAC数据库存储级别高可用性。
解决这个问题的办法是在系统层面将两个存储上的LV镜像,作为Normal的第3个磁盘存在。系统层面的磁盘镜像,如果是Linux,可以非常容易的使用mdadm工具做软RAID来实现,在AIX平台只能部署HACMP软件,通过它完成对并发LV的镜像。
对共享存储来说需要完成以下操作:
1).在RAC的所有节点部署HACMP,将来源于两个存储的一个PV组成并发VG,创建LV,并在两个PV上镜像。
2).另外在每个存储上在划分一个LUN作为集群软件的磁盘。
3).将以上3个磁盘作为安装集群软件的ASM磁盘。
在执行runInstaller命令安装Oracle Database软件的时候会有以下提示:
Has 'rootpre.sh' been run by root on all nodes?[y/n](n)
操作系统安装有HACMP软件的时候,执行rootpre.sh脚本一定要认真看提示,确保正确执行,并且需要在所有节点执行该脚本。
第一个节点执行rootpre.sh脚本:
# ./rootpre.sh
./rootpre.sh output will be logged in /tmp/rootpre.out_13-06-29.11:07:30
Checking if group services should be configured....
Oracle Clusterware may be in use.
Shutdown the Oracle clusterware and rerun the rootpre.sh script.
Aborting pre-installation procedure. Installations of Oracle may fail.
根据提示需要先将Clusterware软件停止之后再执行,如果系统中不存在hagSUSEr组,该脚本会自动创建。
第二个节点执行rootpre.sh脚本:
# ./rootpre.sh
./rootpre.sh output will be logged in /tmp/rootpre.out_13-06-29.10:22:27
Checking if group services should be configured....
Please confirm your Oracle Clusterware Userid is a member of the group: hagsuser
Configuring HACMP group services socket for possible use by Oracle.
根据提示安装Clusterware软件的用户要属于hagsuser组。
在安装有HACMP软件的AIX下,grid和oracle用户正确的属组关系如下:
# id grid
uid=202(grid) gid=201(oinstall) groups=202(asmadmin),203(asmdba),204(asmoper),211(hagsuser)
# id oracle
uid=203(oracle) gid=201(oinstall) groups=203(asmdba),205(dba),206(oper)
如果在没有正确执行rootpre.sh脚本的情况下完成数据库软件的安装,那么在执行root.sh脚本的最后可能收到如下报错:
chmod: libskgxn2.so: A file or directory in the path name does not exist.
chmod: libskgxnr.so: A file or directory in the path name does not exist.
该错误会导致无法创建数据库。
实施这个方案还有以下两点需要注意:
1).由于在启动Clusterware之前要先将HACMP启动成功,所以在RAC正常运行的情况下执行crsctl disable has命令禁止Clusterware随着系统自动启动,整个RAC启动过程需要手动完成。
2).需要注意ASM实例的初始化参数asm_diskstring,确保它能找到并发VG的LV,例如:asm_diskstring='/dev/rocrlv','/dev/rhdisk*'
该方案还存在以下几个问题:
1).任何一个存储当机都不会影响到RAC的正常运行,但当存储恢复正常之后,Clusterware和存储数据文件的ASM磁盘组都不能自动完成对磁盘的识别和激活,需要手动完成以下操作将磁盘重新强制加载到磁盘组中:
alter diskgroup data01 add failgroup fgdata02 disk '/dev/rhdisk21' force,
'/dev/rhdisk22' force
,'/dev/rhdisk23' force
,'/dev/rhdisk24' force
,'/dev/rhdisk25' force
,'/dev/rhdisk26' force;
存放ocr,votedisk和存放数据文件的ASM磁盘组都需要这样做。
2).在我们进行测试的时候,当第一个存储挂掉之后,RAC正常,然后恢复第一个存储,手动执行磁盘重新加载操作,且确保所有的ASM rebalance操作结束,之后当掉第二个存储,这个时候并发VG没有了,由此看来第一个当掉的存储恢复正常后LV不能自动同步,重新激活后的VG中的OCR数据也不正确,这可能需要执行一定的操作重新同步,当然这也可以接受。
存储脱机,恢复后的重新激活操作Oracle ASM可以在线的完成,非常的方便。
3).如果有第3个存储,哪怕只是从别的存储分过来的一个LUN,整个方案就变得更加完美,更加的简单和稳定了。
这个方案最大的价值体现在用最低的价格保障数据库安全的同时消除了RAC的存储单点故障。
--end--