
index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
在Kafka中,索引文件的实现类为OffsetIndex,它的类图如下: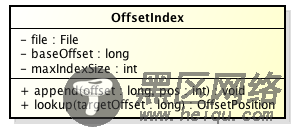
主要的方法有:
append方法,添加一对offset和position到index文件中,这里的offset将会被转成相对的offset。
lookup, 用二分查找的方式去查找小于或等于给定offset的最大的那个offset
小结我们以几张图来总结一下Message是如何在Kafka中存储的,以及如何查找指定offset的Message的。
Message是按照topic来组织,每个topic可以分成多个的partition,比如:有5个partition的名为为page_visits的topic的目录结构为:
partition是分段的,每个段叫LogSegment,包括了一个数据文件和一个索引文件,下图是某个partition目录下的文件:
可以看到,这个partition有4个LogSegment。
查找Message原理图: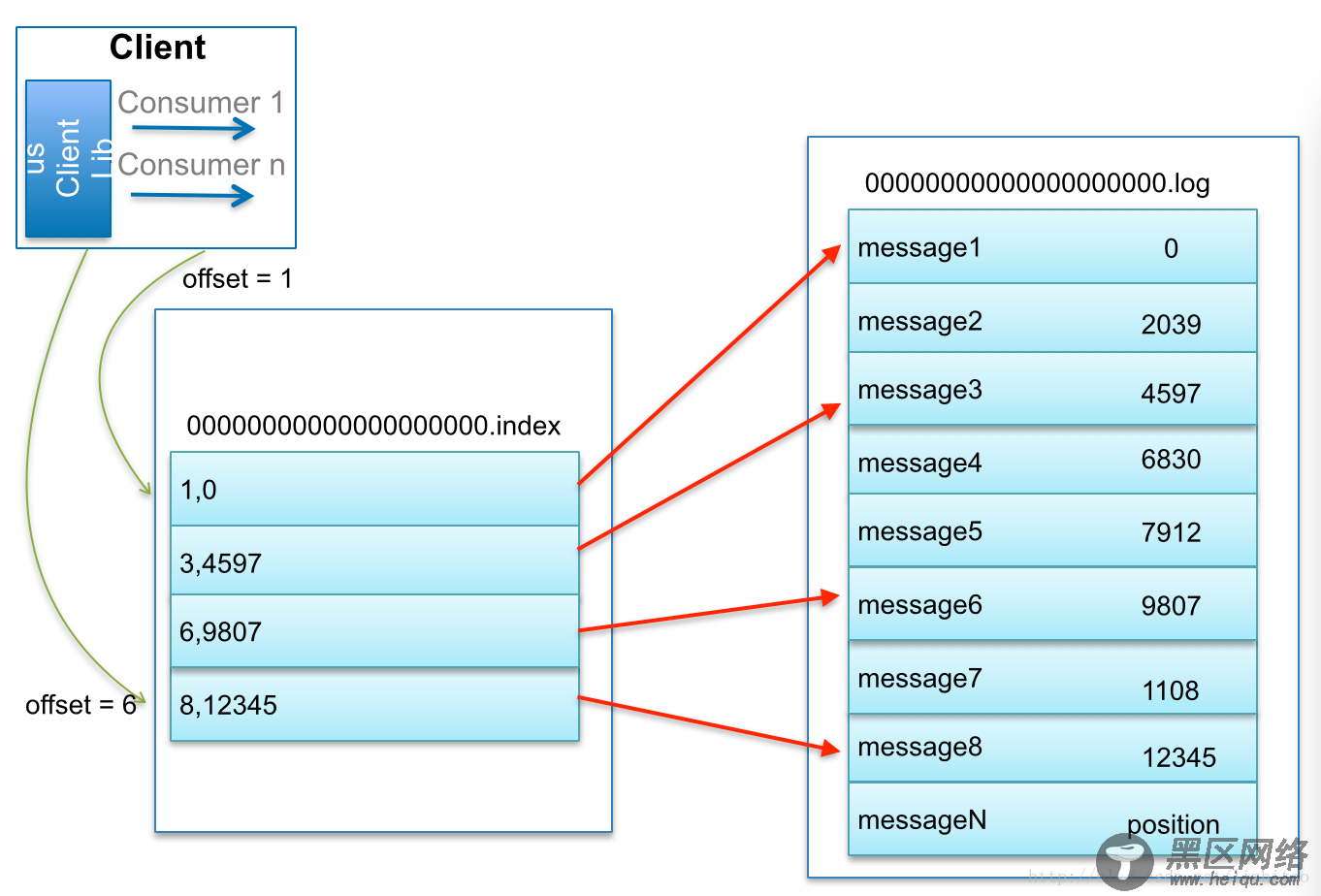
比如:要查找绝对offset为7的Message:
首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
这套机制是建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
一句话,Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。
Kafka使用jmxtrans+influxdb+grafana监控JMX指标 https://www.linuxidc.com/Linux/2019-04/158037.htm
Kafka单机环境搭建简记 https://www.linuxidc.com/Linux/2019-03/157651.htm
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx