是不是晕了。让我们从头分析。

例二:
把例一的add.asp的<%@ codepage=936%>改为<%@ codepage=950%>,又会怎么样呢?

到这里发现了什么?
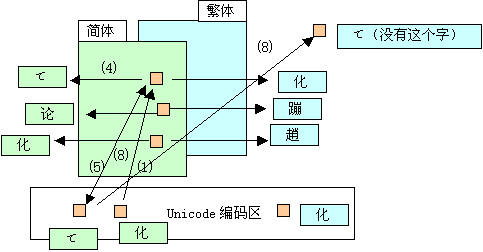
1.如果输入的文字和Charset对应的不同,一转换,就可能出现Unicode形式的字了。这里就是原因所在。以后整个过程都保留着。
2.Add.asp里codepage决定了保存到数据库的文字,用的是哪个语言对应的Unicode.如codepage=936,
那么数据库保存的就是简体中文的Unicode(数据库拿回简体中文系统,一切正常的),
codepage=950保存的就是繁体中文的Unicode.(拿回简体中文系统,就不对了)。
3.注意一下串串的变化过程:
1)输入法---CharsetUnicode----指定字符集的映射
2)Charset----表单编码串串简单编码
3)表单解码上步的逆过程,两步抵消了。
4)串串à按codepage读取串串没变,这步有可能“误会读取”
5)转为对应的Unicode Codepage指定字符集----Unicode映射
6)中间处理,进数据库无变化,直接以Unicode形式进入
7)按codepage读取数据库 Unicode----codepage指定字符集的映射
8)显示,按Charset指定字符集读取串串没变。
以例一说明:
例二:

晕了。现在来用用知识。
案例1。
简体中文系统下跑的好好的代码,放到国外空间上,数据库里乱码,原有的数据也乱码。
分析:因为大多数人平时用的都是简体中文系统,默认的codepage=936,所以平时大家不写也没有关系。
但到了国外空间问题就出来了。从数据库里的Unicode转换到英文编码去了,所以数据库原有的简体中文转换到英文后,按GB显示自然乱码。
如图,新输入的文字显示正常,但数据库里保存的是英文的Unicode的。
解决方法:全部加上<%@codepage=936即可%>。
全程只有简体中文与对应Unicode间的转换。

案例二:
简体中文的代码和数据,想转为完全的繁体版,该怎么办?
分析:1。代码文件编码全部改为Big5的,文件本身保存编码选繁体。
2.<%@ codepage=936 %>
3.Charset=big5
4.access版本无所谓,因为access里的数据是Unicode的。
5.好了,代码可以在纯繁体系统下跑了。
6.遗留问题:原有的简体中文数据读出会有一些问号。效果同例一的950读取,big5显示。因为从简体中文的Unicode转换到繁体中文了,有些字繁体中没有,就会出问号。