
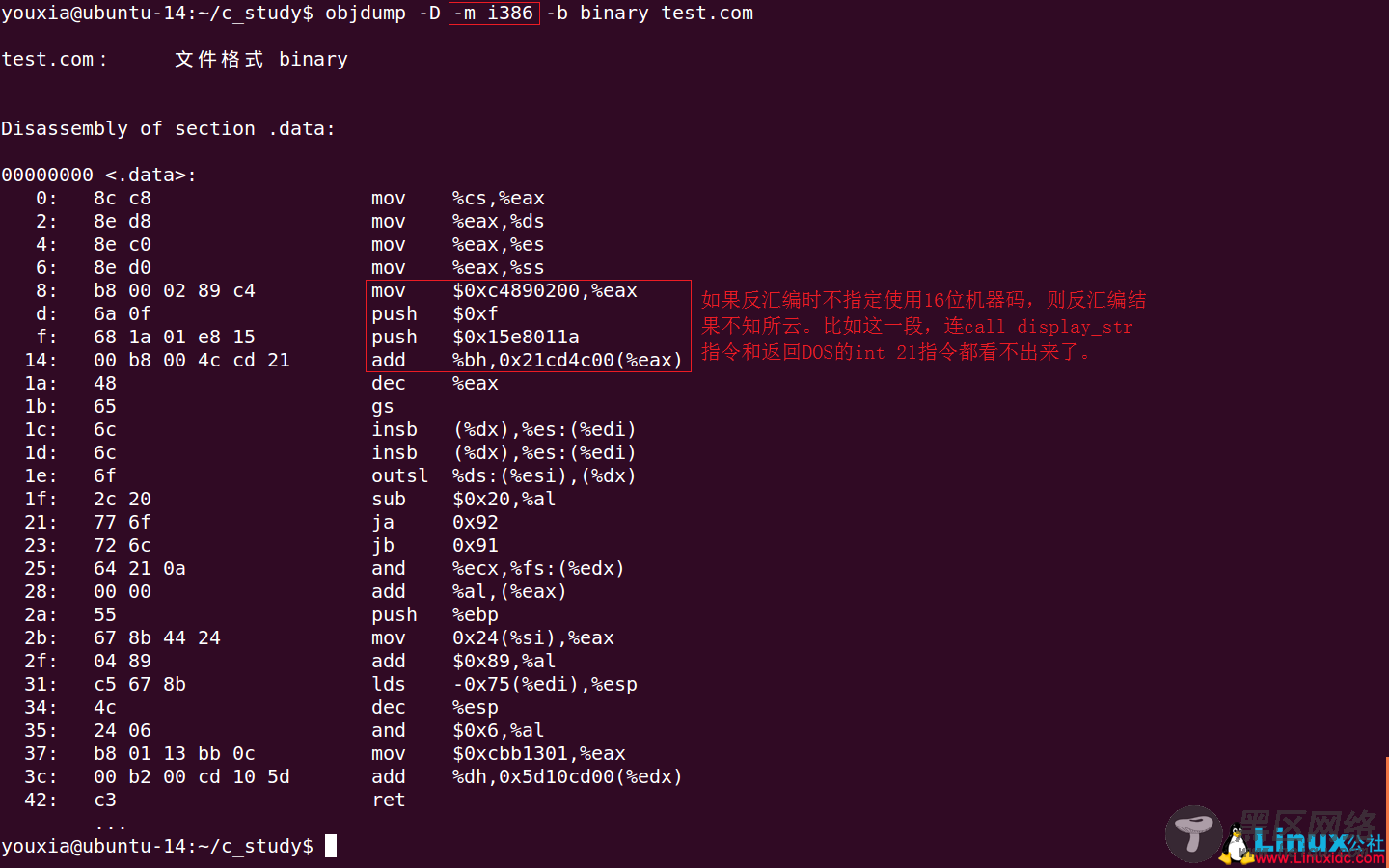
反汇编时,一定要指定-m i8086选项,否则objdump不知道反汇编的是16位代码。(前面提到过Linux从诞生起就是32位,所以ELF只有32位和64位两种,没有16位的ELF格式。)如下图,如果使用-m i386选项进行反汇编,反汇编结果将不知所云:
下面进入C语言的世界。为了搞清楚C语言生成的16位代码的汇编指令有哪些特别之处,先写一个简单的C语言程序进行调研,如下图:
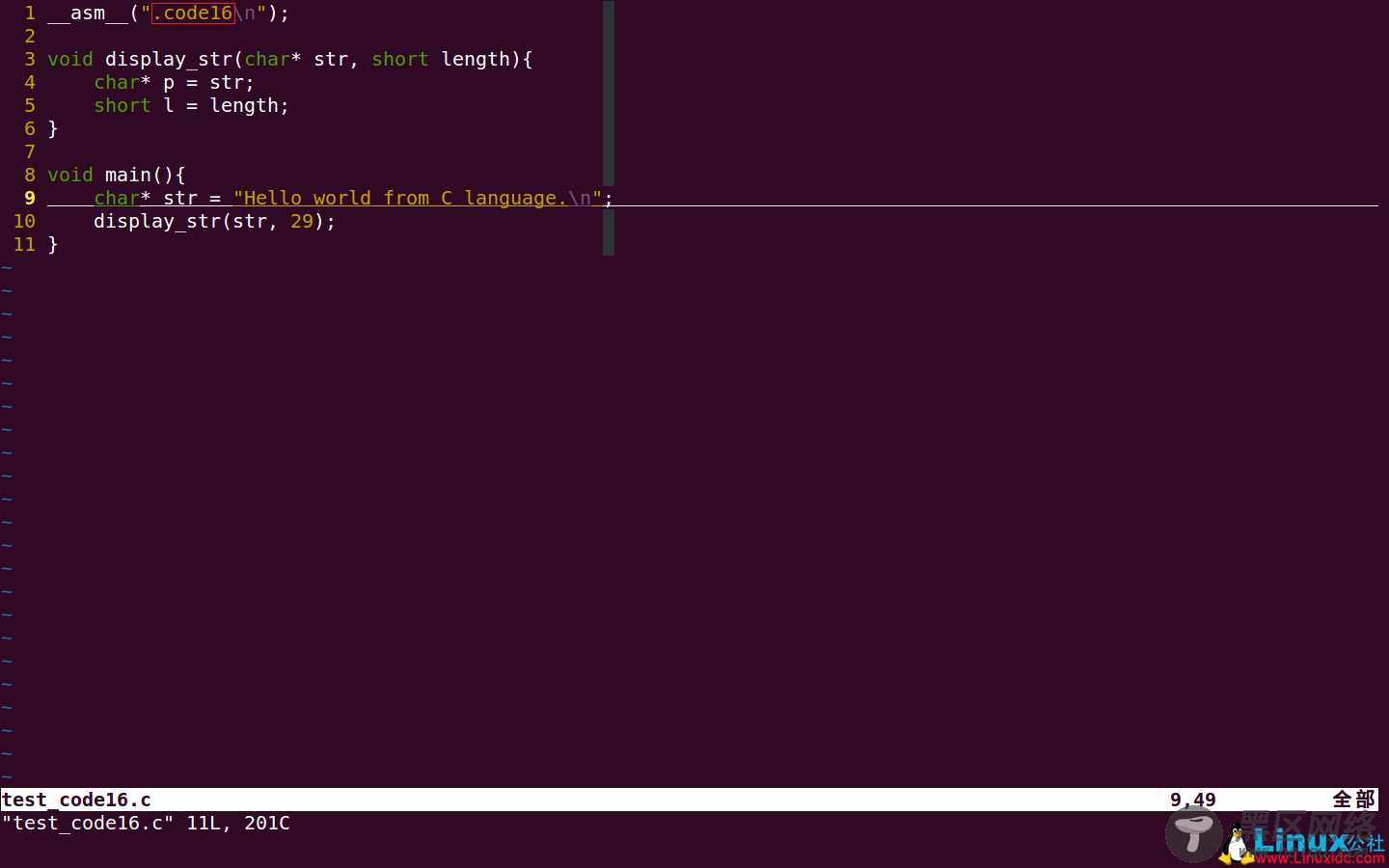
该程序有以下特点:
1. 程序的开头使用了__asm__(".code16\n")嵌入汇编指令,以指示as生成16位代码;
2. display_str函数的签名和之前汇编语言中的相同,可以使用它来观察C语言生成的代码如何传递参数。
使用下面的命令对程序进行编译和反汇编,如下图:

从上图可以看出,C语言生成的代码虽然是16位,但是它有如下特点:①从生成的display_str函数中可以看出,函数一开始是push %ebp,而不是push %bp;②在display_str函数中获取参数的位置分别为0x8(%ebp)和0xc(%ebp),而不是我在汇编语言中写的0x4(%ebp)和0x6(%ebp);③从生成的main函数可以看出,调用diaplay_str之前,没有使用push命令把参数压栈,而是直接通过sub $0x18, %esp调整%esp的位置,然后使用mov指令将参数放到指定位置,和使用push指令的效果相同;④虽然我在display_str函数的定义中故意将长度参数定义为short,但是从生成的代码中可以看到依然是每隔4个字节放一个参数。
另外需要说明的是,调用gcc时除了指定-c选项指示它只编译不连接外,还要指定-m32选项,这样才会生成32位的汇编代码,而只有在32位的汇编代码中使用.code16指令,才能编译成16位的机器码。如果没有指定-m32选项,则生成的是64位汇编代码,然后汇编时会出错。使用-m32选项后,生成的目标文件是ELF32格式。ELF32格式的目标文件只能和ELF32格式的目标文件连接,这也是为什么前面的as和ld需要指定--32和-m elf_i386选项的原因。
通过以上分析,似乎可以得出以下结论:只需要将汇编代码中的pushw %bp更改为pushl %ebp,然后将获取参数的位置调整为0x8(%ebp)和0xc(%ebp),就可以从C语言里面成功调用到汇编语言中的函数了。而事实上,还有一点点小差距。从上面的反汇编代码中可以看到,函数调用时使用的是16位的call指令,该指令压栈的是%ip,而不是%eip,而C语言生成的函数框架中获取的参数位置是按照将%eip压栈计算出来的,它们之间差了两个字节。
为了证明我以上判断的准确性,我将上面的C语言程序和汇编程序修改后,编译连接成一个完整的程序,看看它究竟能否正确运行。如下图:
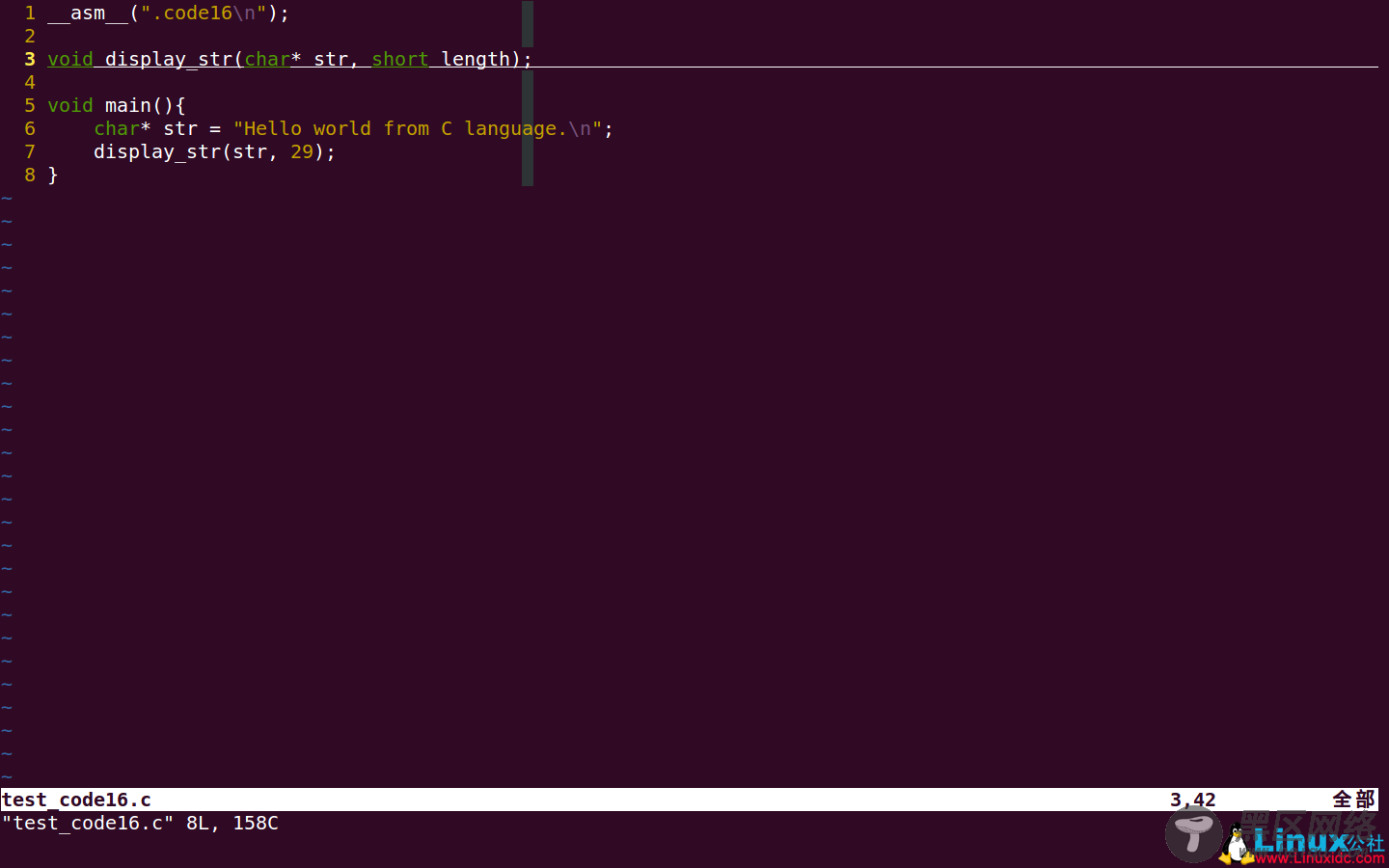
C语言程序修改很简单,就是去掉了display_str函数的实现,只保留声明。汇编代码如下图:
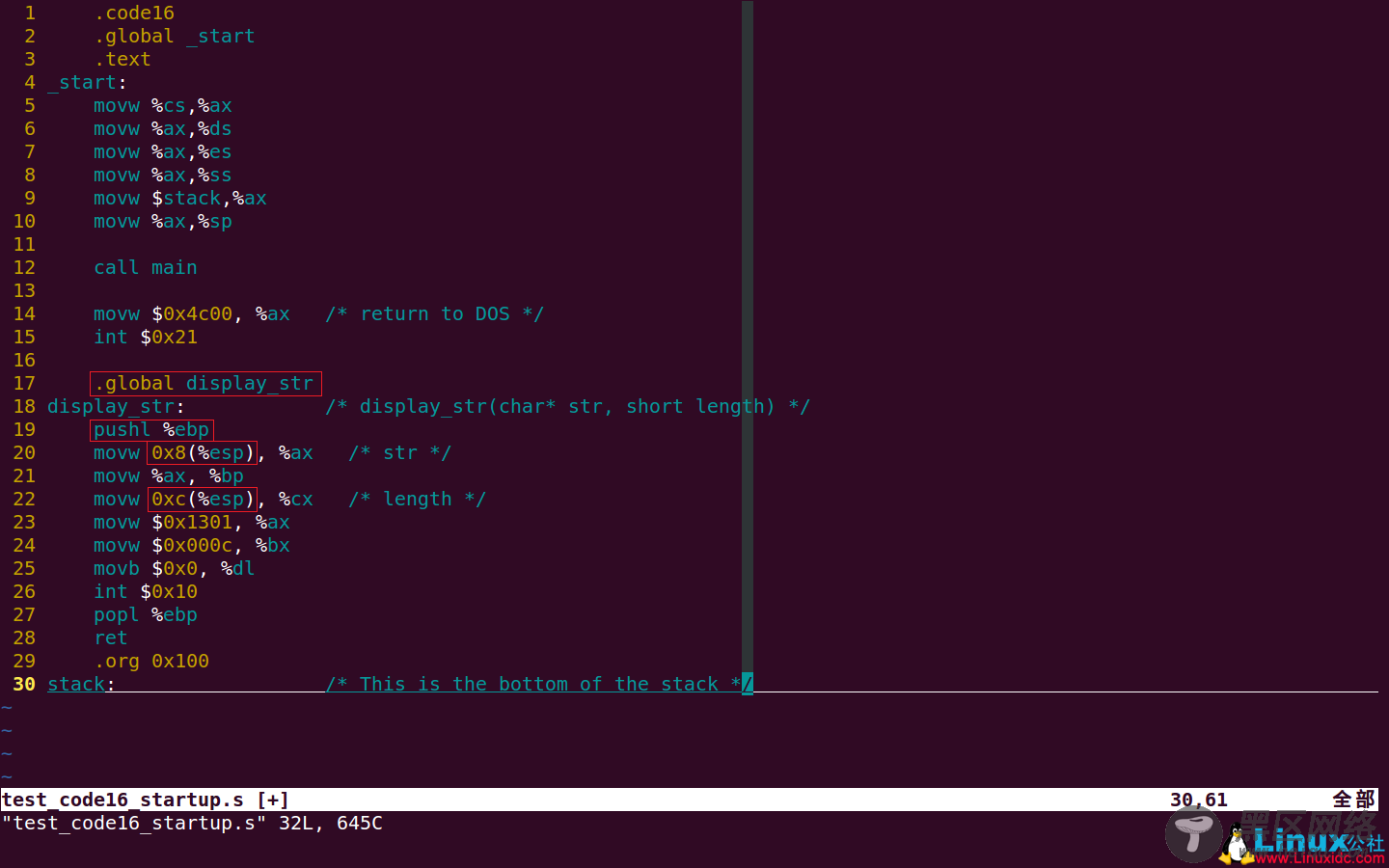
汇编语言的更改包含以下几个地方:将display_str函数导出,将pushw %bp改为pushl %ebp,同时修改获取参数的位置。编译、连接、运行程序的指令如下:
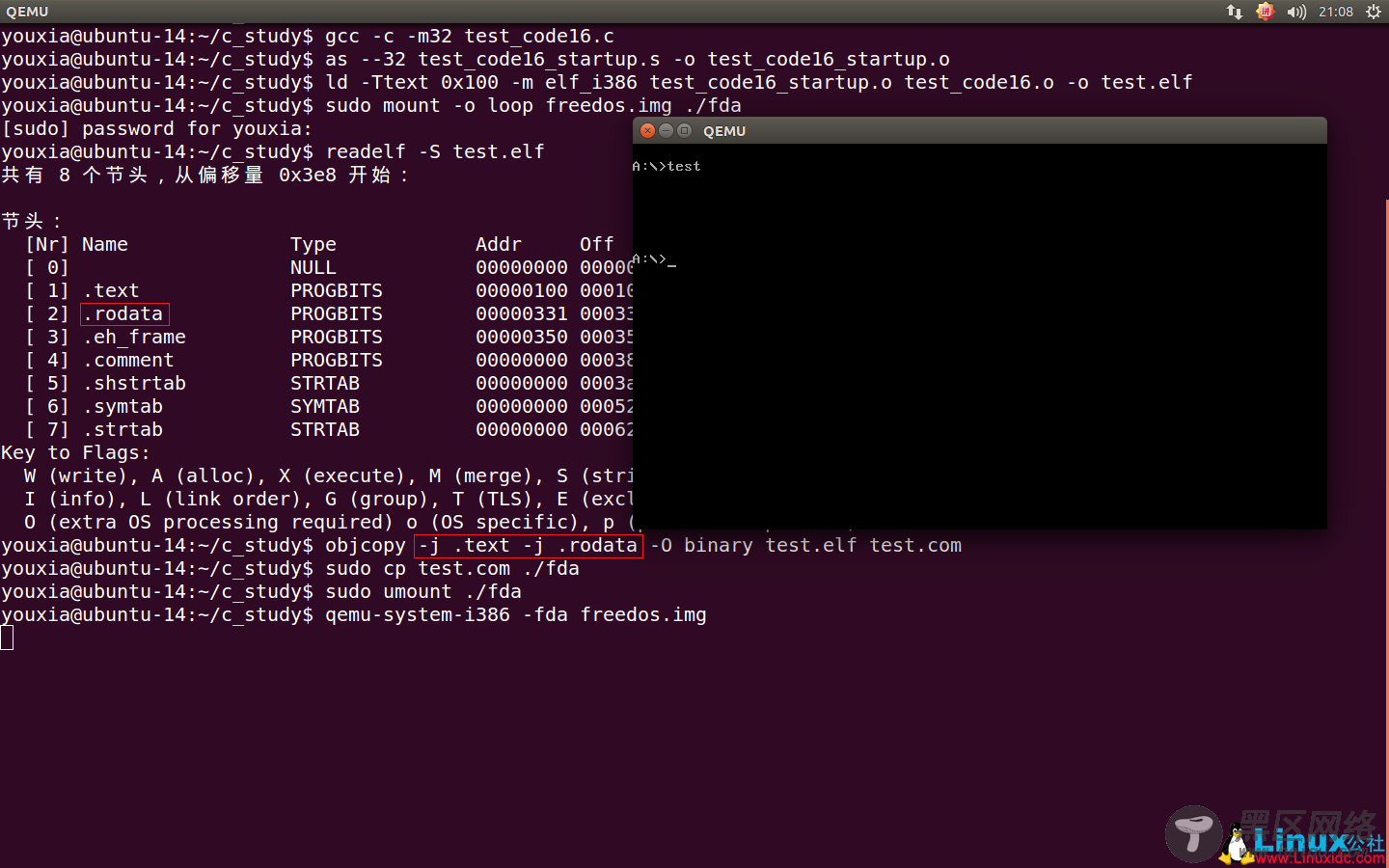
可以看到“Hello world from C language”没有正确显示出来。上面的命令都是前面用过的,不需要多解释,唯一不同的是使用C语言写的程序多了一个.rodata段,所以在objcopy的时候需要把这个段也包含进来。
由于C语言生成的函数框架都是从0x8(%ebp)开始取参数,它认为0x0(%ebp)是old ebp,0x4(%ebp)是%eip,而事实上使用16位的call指令调用函数后,0x4(%ebp)中是%ip而不是%eip,所以要从0x6(%ebp)开始取参数。我们不可能修改C语言生成的函数框架,只能看看能否将16位的call改成32位的call。