
上游服务器缓存的是图片,但是图片中加了cookie ,图片一般而言跟用户的关联不是很大,除非是邮件服务器,虽然图片的关联不大,但是加了cookie,就没办法在多个用户之间共享缓存,那这种情况下需要将cookie删掉,将图片缓存,并且缓存很长时间
所以这些处理机制都需要在内部完成策略的,所以这些都需要在不同的步骤完成
所以所谓的状态引擎就是当一个用户的请求到达后,大致走到哪一层,我们在哪个步骤哪个位置大致做出哪些处理,这就为状态
在请求的报文在大致经过的位置,内置了几个状态引擎,在用户的请求到达状态引擎的时候,我们在其状态引擎上做规则并做出相应处理
状态引擎图解
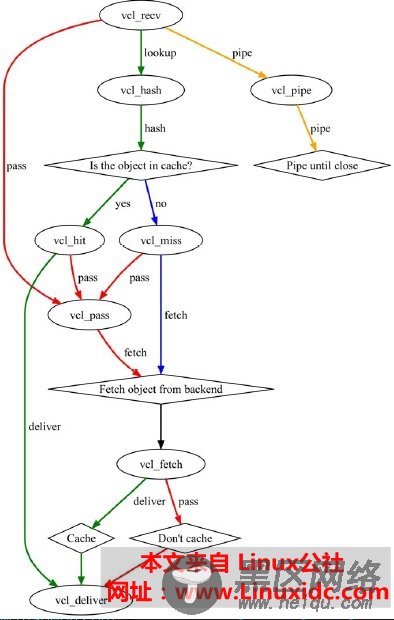
椭圆形为状态引擎
菱形的为条件判断
每个颜色箭头下面的字符串为处理机制
首先用户请求到达后,首先进入vcl_recv
vcl_recv对其做判断,是否命中缓存(vcl_hash)
如果不想使用缓存则直接交由vcl_pipe,建立管道并交由后端服务器
如果期望本地缓存处理则自定义检测缓存lookup
很显然,如果要检查缓存是需要根据什么方式做检查
判断缓存中是否存在对象 ,如果命中了yes 于是交予vcl_hit
就算命中了也有两条路可以走:
·deliver 直接由vcl_deliver在缓存中取出直接返回至用户
·如果命中了交予给vcl_pass 通过自行手动控制了到后端缓存中去取的数据,有些时候有独特的控制机制
而vcl_miss也可以交由vcl_pass来处理
而为什么使用pass
如果我们期望处理缓存的,比如要清理缓存,缓存中的内容找到则清理,如果没有找到则通过pass做一些处理
仅仅是提供用户编辑一些规则的而已
如果未命中,很先让必然要到后端去取vcl_fatch
取完之后是否缓存下来就是在fatch中定义的
如果要缓存就先放着cache中,如果不想缓存则Dont'Cache
最后再响应至客户端
因此用户请求到达varnish之后,varnish大致要经过以上的处理阶段,而每个处理阶段要自定义处理规则对其做出处理,而有些功能只能在后端实现,有些只能在前端,不同的规则要在不同的位置实现的
VCL_RECV
vcl_recv是在Varnish完成对请求报文的解码为基本数据结构后第一个要执行的子例程,它通常有四个主要用途:
(1)修改客户端数据以减少缓存对象差异性;比如删除URL中的等字符;
(2)基于客户端数据选用缓存策略;比如仅缓存特定的URL请求、不缓存POST请求等;
(3)为某web应用程序执行URL重写规则;
(4)挑选合适的后端Web服务器;
可以使用下面的终止语句,即通过return()向Varnish返回的指示操作:
pass:绕过缓存,即不从缓存中查询内容或不将内容存储至缓存中;
pipe:不对客户端进行检查或做出任何操作,而是在客户端与后端服务器之间建立专用“管道”,并直接将数据在二者之间进行传送;此时,keep-alive连接中后续传送的数据也都将通过此管道进行直接传送,并不会出现在任何日志中;
lookup:在缓存中查找用户请求的对象,如果缓存中没有其请求的对象,后续操作很可能会将其请求的对象进行缓存;
error:由Varnish自己合成一个响应报文,一般是响应一个错误类信息、重定向类信息或负载均衡器返回的后端web服务器健康状态检查类信息;
vcl_recv也可以通过精巧的策略完成一定意义上的安全功能,以将某些特定的攻击扼杀于摇篮中。同时,它也可以检查出一些拼写类的错误并将其进行修正等。